
总第522篇
2022年 第039篇


-
1. 背景
-
2. 问题及思路
-
2.1 业务介绍
-
2.2 主要挑战
-
2.3 解决思路
-
3. 整体架构
-
4. 核心设计点
-
4.1 作业调度设计
-
4.2 资源池划分设计
-
4.3 组件分层设计
-
5. 后续规划
1. 背景
-
第一阶段(2014-2015):搭建Jenkins统一集群,解决业务接入的通用问题(如单点登录、代码仓库集成、消息通知、执行机的动态扩缩等),降低业务的建设成本。
-
第二阶段(2016-2018):拆分多个Jenkins集群,解决业务增长导致单集群性能瓶颈。最多时有十几个集群,这些集群通常是按业务线维度划分,并由业务自行建设。但随着时间的推移,集群的拆分管理难度越来越大,Jenkins安全隐患频出,对平台方造成了很大的运维负担。
-
第三阶段(2019-至今):为了彻底解决引擎单机瓶颈和工具重复建设问题,我们开始自研分布式流水线引擎(美团内部项目名称为Pipeline),并逐步收敛各业务依赖的底层基建。
2. 问题及思路
2.1 业务介绍
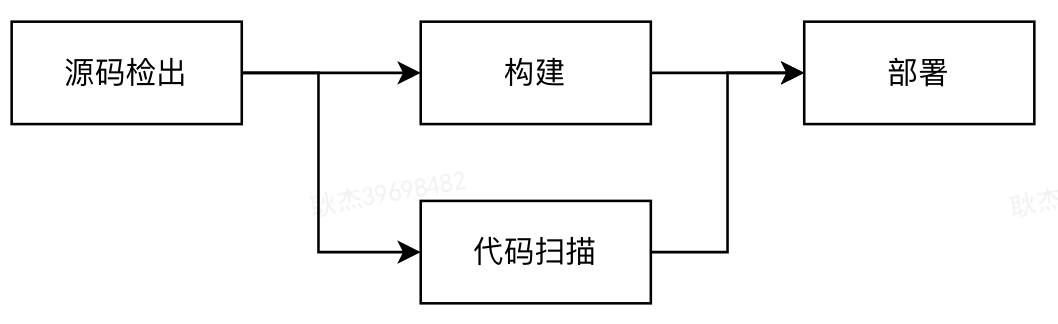
-
组件:出于代码复用和业务共享的考虑,我们将某一工具的操作行为封装成一个组件,表示对于一项具体的加工或校验行为。通过组件方式,业务可以便捷地使用已集成的质量工具(如静态代码扫描、安全漏洞分析等),减少在同一工具上的重复开发成本;对于不满足需求的场景,业务可以自定义一个新的组件。
-
组件作业:表示组件的一次运行实例。
-
资源:为组件作业分配的一个可执行环境。
-
流水线编排:表示流水线中不同组件执行的先后顺序。
-
引擎:负责调度所有的组件作业,为其分配相应的执行资源,保证流水线执行按预期完成。
2.2 主要挑战
-
从业务场景考虑,调度逻辑存在一定的业务复杂性(如组件串并行判断、优先级抢占、降级跳过、复用上一次结果等),不仅仅是作业与资源的匹配计算,作业调度耗时存在一定的业务开销。
-
引擎支撑公司每天近十万次的执行量,峰值量情况下,并发调度的作业量大,常见的开源工具(Jenkins/GitLab CI/Tekton等)都是采用单体调度模式,作业是串行调度的,容易出现调度瓶颈。
-
如果只依靠动态扩容,容易出现资源不足时无法扩容、作业排队等待的情况。特别是对于依赖流水线做研发卡控的业务,这会直接阻塞业务的上线流程。
-
出于执行耗时的考虑,大部分资源采用预部署的方式,缩短资源申请和应用启动的准备时间。而对于预部署的资源,如何进行有效划分,既保证每类资源都有一定配额,同时也避免出现部分资源利用率过低,影响作业整体的吞吐能力。
-
不是所有工具的执行资源都由引擎管理(如发布系统,部署任务的资源管理是单独的),在作业的资源分配上,还需要考虑不同的资源管理方式。
-
不同工具实现形式差异化大,有些工具有独立的平台,可以通过接口方式进行集成,有些仅仅是一段代码片段,还需要提供相应的运行环境。面对不同的接入形态,引擎如何屏蔽不同工具带来的差异,使业务在编排流水线时不用关注到工具的实现细节。
-
随着业务场景的不断丰富,组件执行还会涉及人工交互(审批场景)、支持重试、异步处理、故障恢复等能力,这些能力的扩展如何尽可能减少对系统的冲击,降低实现的复杂度。
2.3 解决思路
-
调度决策:负责计算出可以调度的作业,提交决策,等待合适的资源来执行。该模块具体水平扩展,分担调度决策的压力。
-
资源分配:负责维护作业与资源的关系,通过主动拉取作业的方式,资源可以向任意的实例拉取作业,取消了原先串行分配资源的单点限制。
-
在作业端,作业基于标签属性拆分到不同的作业队列,并引入优先级概念,保证每个队列中作业按优先级高低被拉取到,避免在积压时,高优作业排在后面无法被及时处理,阻塞业务研发流程。
-
在资源端,结合资源的实际场景,提供三种不同的资源池管理方式,以解决不同资源类型的配额和利用率问题。 -
预置的公共资源,这部分资源会提前在资源池上扩容出来,主要应对业务高频使用的且对时间敏感的组件作业。在资源配额和利用率上,根据资源池的历史情况和实时监控,动态调整不同资源池的大小。
-
按需使用的资源,主要针对公共资源环境不满足的情况,业务需要自定义资源环境,考虑到这部分作业的体量不大,直接采用实时扩容的方式,相比预置资源的方式,可以获得更好的资源利用率。
-
外部平台的资源,这些资源的管理平台方比我们更有经验,平台方通过控制向引擎拉取作业的频率和数量,自行管理作业的吞吐情况。
-
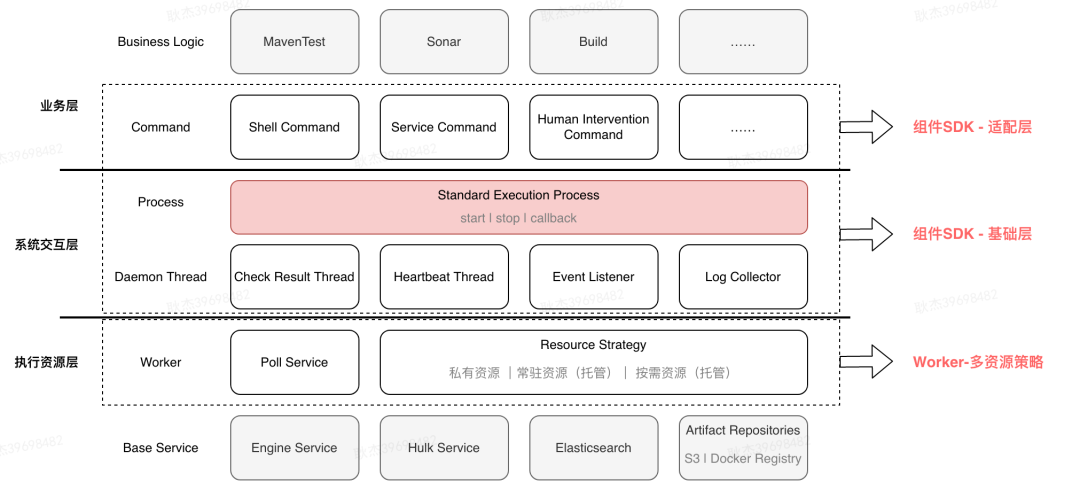
系统交互层,该层相对组件开发者是透明的,根据引擎提供的接口制定统一的流程交互标准,以向引擎屏蔽不同组件的实现差异。
-
执行资源层,主要解决工具运行方式的差异化,通过支持多种组件交付形式(如镜像、插件安装、独立服务)满足工具与引擎的不同集成方式。
-
业务逻辑层,针对业务不同的开发场景,采用多种适配器的选择,来满足业务不同的开发诉求。
3. 整体架构
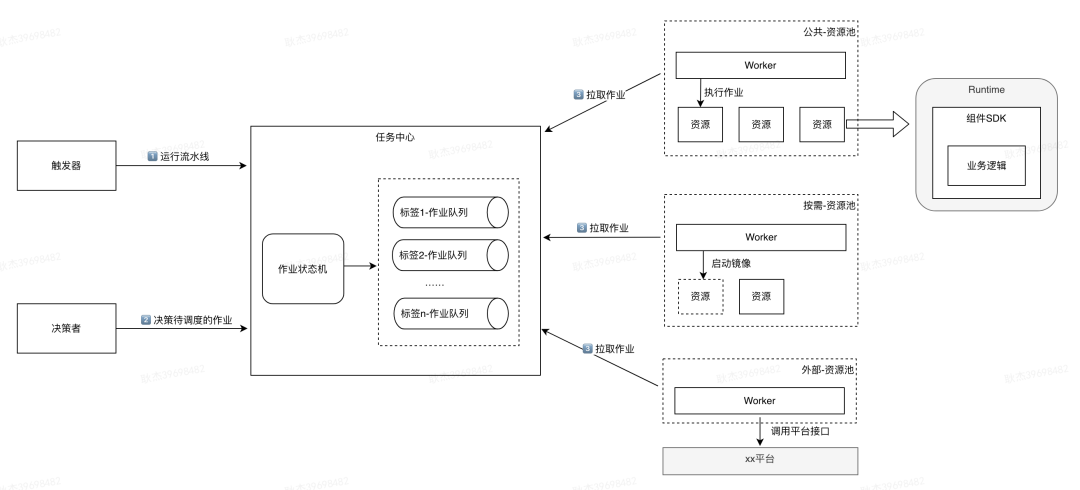
-
触发器:作为流水线的触发入口,管理多种触发源及触发规则(Pull Request、Git Push、API 触发、定时触发等)。
-
任务中心:管理流水线构建过程中的运行实例,提供流水线运行、中止、重试、组件作业结果上报等操作。
-
决策者:对所有等待调度的作业进行决策,并将决策结果同步给任务中心,由任务中心进行作业状态的变更。
-
Worker:负责向任务中心拉取可执行的作业,并为作业分配具体的执行资源。
-
组件SDK:作为执行组件业务逻辑的壳,负责真正调起组件,完成组件初始化与状态同步的系统交互。
4. 核心设计点
4.1 作业调度设计
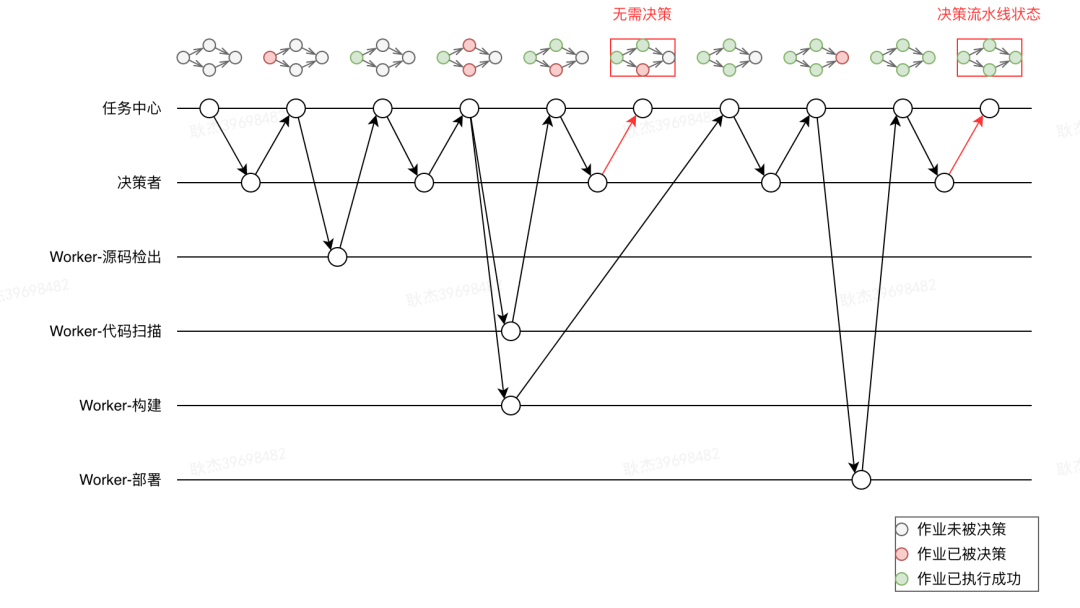
-
当触发流水线构建后,系统会在任务中心创建该编排所要执行的所有组件作业。并且将作业状态的变化以事件方式通知决策者进行决策。
-
决策者接收决策事件,根据决策算法计算出可被调度的作业,向任务中心提交作业的状态变更请求。
-
任务中心接收决策请求,完成作业状态变更(作业状态变更为已决策),同时加入相应的等待队列。
-
Worker 通过长轮询方式拉取到和自己匹配的等待队列的作业,开始执行作业,执行完成后将结果上报给任务中心。
-
任务中心根据Worker上报的作业执行结果变更作业状态,同时向决策者发起下一轮决策。 -
以此反复,直至流水线下所有作业都已执行完成或出现作业失败的情况,对流水线进行最终决策,结束本次执行。
状态机在接收某种状态转移的事件(Event)后,将当前状态转移至下一个状态(Transition),并执行相应的转移动作(Action)。
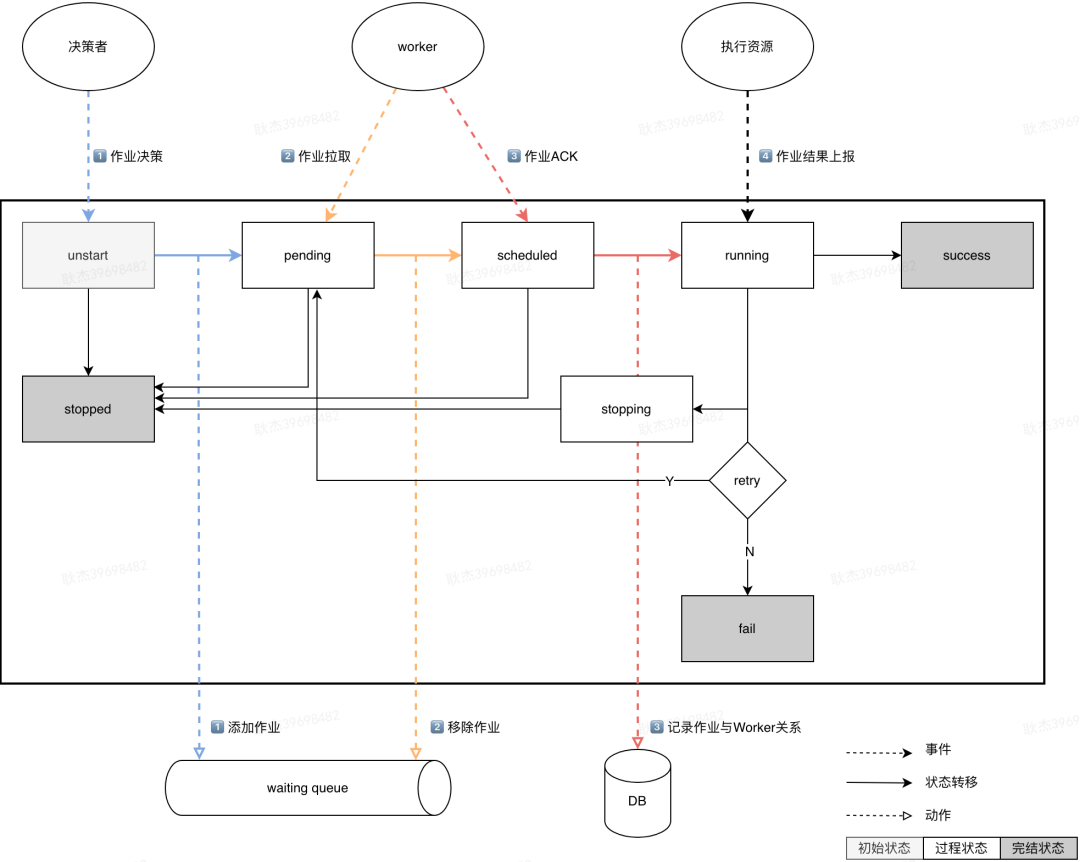
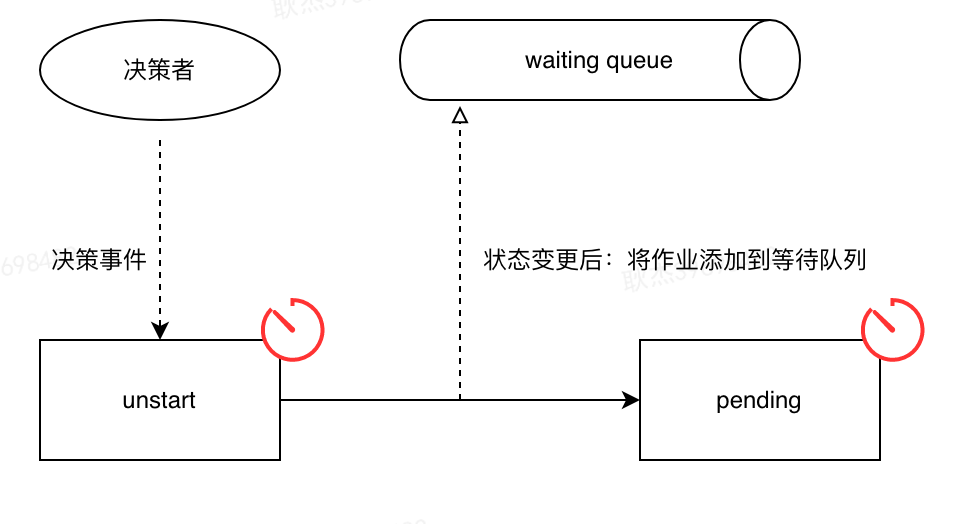
-
未收到决策事件:由于决策者服务自身的问题或网络原因,导致决策事件的请求失败,作业长时间处于未调度状态。 -
解决方案:引入定时监测的机制,对于无过程状态作业且处于未完结状态的流水线进行重新决策,避免决策服务短时间异常导致决策失败。 -
重复决策:由于网络延迟、消息重试现象可能出现多个决策者同时决策同一个作业,产生作业转移的并发问题。 -
解决方案:增加pending的状态表示作业已被决策到,并通过数据库乐观锁机制进行状态变更,保证仅有一个决策会真正生效。 -
状态变更过程异常:由于存在异构数据库,状态变更和加入队列可能存在数据不一致,导致作业无法被正常调度。 -
解决方案:采用最终一致性的方案,允许调度的短暂延迟。采用先变更数据库,再加入队列的操作顺序。利用补偿机制,定时监测队列队首的作业信息,若pending状态下的作业有早于队首作业的,进行重新入队操作。
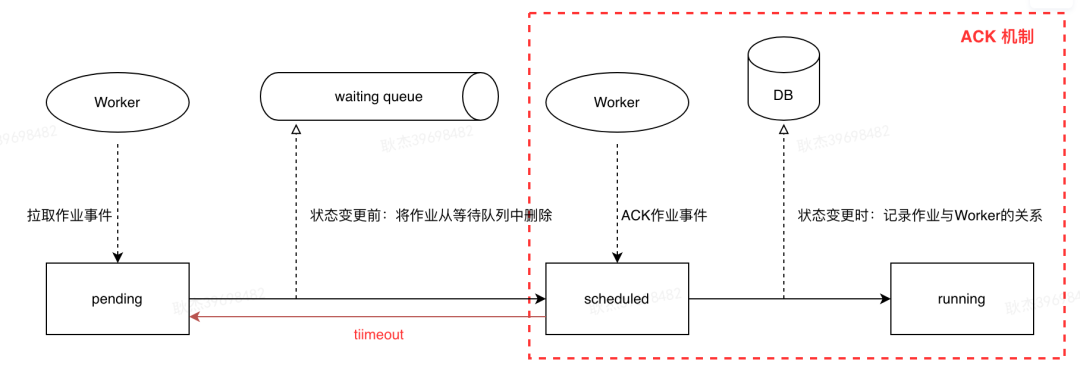
-
作业丢失问题:这里存在两种情况,①作业从队列中移除,但在状态将要变更时异常了;②作业从队列中移除,也正确变更了状态。但由于poll请求连接超时,未正常返回给Worker。 -
解决方案:前者通过作业决策环节中对pending状态的作业补偿机制,重新加入队列;后者对于状态已变更的情况,已调度的作业增加ACK机制,若超时未确认,状态会流转回pending状态,等待被重新拉取。 -
作业被多个Worker拉取:Worker在接收到作业后,遇到长时间的GC,导致状态流转回pending状态,在Worker恢复后,可能出现作业已分配到另一个Worker上。 -
解决方案:通过数据库乐观锁机制保证仅有一个Worker更新成功,并记录作业与Worker的关系,便于对作业进行中止以及Worker故障后的恢复操作。
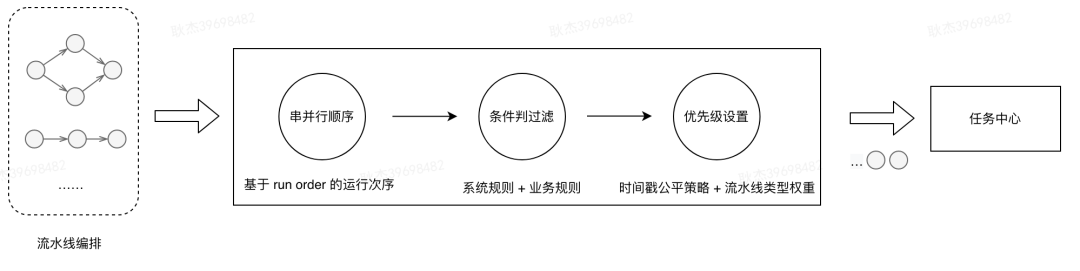
-
串并行顺序:相对于DAG中复杂的寻路场景,流水线场景比较明确,是将代码逐步加工验证,通过开发、测试、集成、上线等一系列阶段的过程。阶段间是严格串行的,阶段内出于执行效率的考虑,会存在串并行执行的情况。这里通过模型设计,将DAG的调度问题转变成作业的先后次序问题,引入run order概念,为每个组件作业设置具体的执行次序,根据当前已执行作业的次序,快速筛选出下一批次序仅大于当前的作业,若并行执行,仅需将作业的次序设置成相同即可。

-
条件过滤:随着业务场景扩展,不是所有的作业都需要调度资源,进行真正的执行。如某类耗时的组件,在代码和组件参数都不变的情况下,可以直接复用上一次的执行结果,或者在系统层面针对某类工具异常时进行组件跳过的降级操作。针对这类情况,在作业真正提交给任务中心之前,会增加一层条件判断(条件分为全局设置的系统条件以及用户条件),这些条件以责任链形式进行依次匹配过滤,根据匹配到的条件单独向任务中心提交决策。 -
优先级设置:从系统全局考虑,在作业出现积压时,业务更关心核心场景下整条流水线是否能尽早执行完成,而不是单个作业的排队情况。所以,在优先级设置上除了基于时间戳的相对公平策略外,引入流水线类型的权重值(如发布流水线>自测流水线;人工触发>定时执行),保证核心场景流水线相关作业能够尽早被调度到。
4.2 资源池划分设计
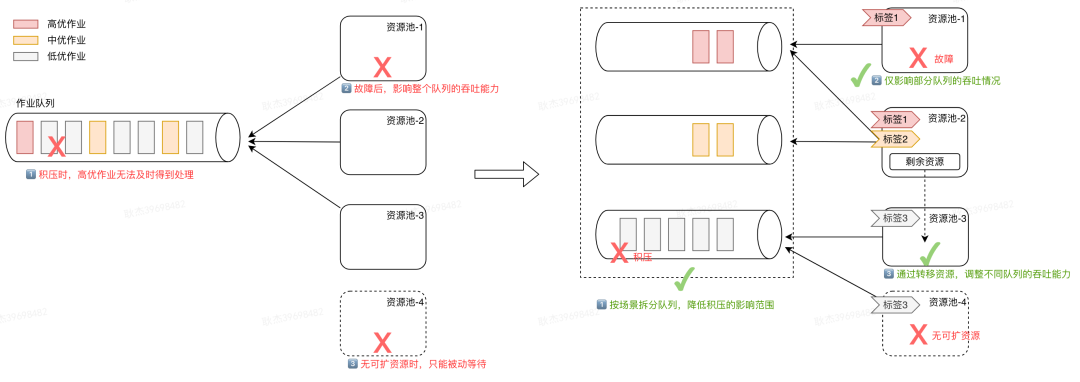
-
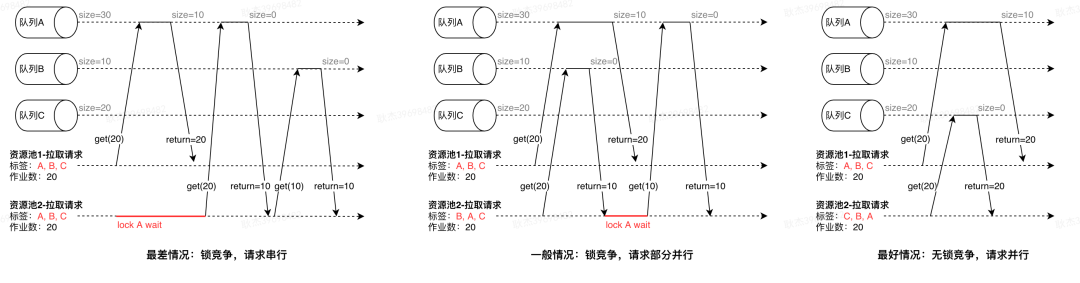
当队列积压时,能快速定位到某个标签没资源了。
-
标签资源不足时,也能快速判断影响的具体队列情况。
-
对于一些作业量较少的队列,单独分配一个资源池会造成大部分时间资源是空闲状态,资源利用率低。我们通过给资源池打多标签的方式,既保证了队列有一定的资源配额,同时也能处理其他标签的作业,提高资源的利用率。
-
对于核心场景的队列,通常标签资源会分配到多个资源池上,保证资源的一定冗余,同时也降低单个资源池整体故障带来的影响。
-
第一维度:组件维度,对资源做通用划分。结合组件的业务覆盖情况、作业执行量、对机器和环境的特殊要求(如SSD、Dev环境等),对需要独立资源的组件进行打标,划分出不同的公共资源池(每个公共资源池执行一类或多类组件作业),在引擎层面统一分配,保证所有作业都有可正常运行。
-
第二维度:流水线维度,根据业务场景进行划分。结合业务对资源隔离/作业积压敏感度的诉求,按需进行划分。有些希望资源完全独立的业务,会从所有的公共资源池进行切分;有些仅对部分核心场景下的资源需要保障,根据链路上涉及的组件,选择性地从部分公共资源池进行划分,实现业务隔离和资源利用率的平衡。
注:每个维度都会设一个other的默认值用来兜底,用于处理无资源划分需求的场景。

-
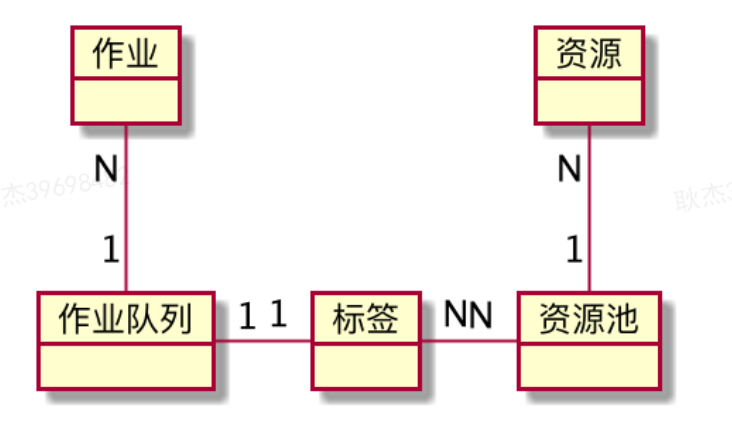
入队过程:通过计算作业在组件和流水线两个维度的属性值,来确定作业对应的标签。结合模型关系中标签与队列(1对1)的关系,为每个标签按需创建一个队列,存储该标签作业,不同队列间作业做排他处理,简化出队的实现复杂度。
-
出队过程:队列拆分后,因为标签和资源池(多对多)的关系,资源池的一次作业拉取请求往往会涉及多个队列。出于拉取效率的考虑,采用轮询的方式依次对单队列进行出队操作,直到达到该次请求的作业数上限或所有可选队列为空时返回结果。该方式可以避免同时对多个队列加锁,并且在前置环节会对多标签进行随机排序,降低多个请求同时操作一个队列的竞争概率。
4.3 组件分层设计
-
业务层:引入适配层,满足组件开发中多样化的需求场景,同时避免上层差异污染到下层。
-
系统交互层:设立统一的流程标准,保证引擎和组件交互过程的一致性,便于统一处理非功能性的系统优化。
-
执行资源层:提供多种资源策略,向上层屏蔽不同资源类型的差异。
init()、run()、queryResult()、uploadArtifacts() 等必要方法供业务实现,整个交互流程则由系统统一处理,业务无需关心。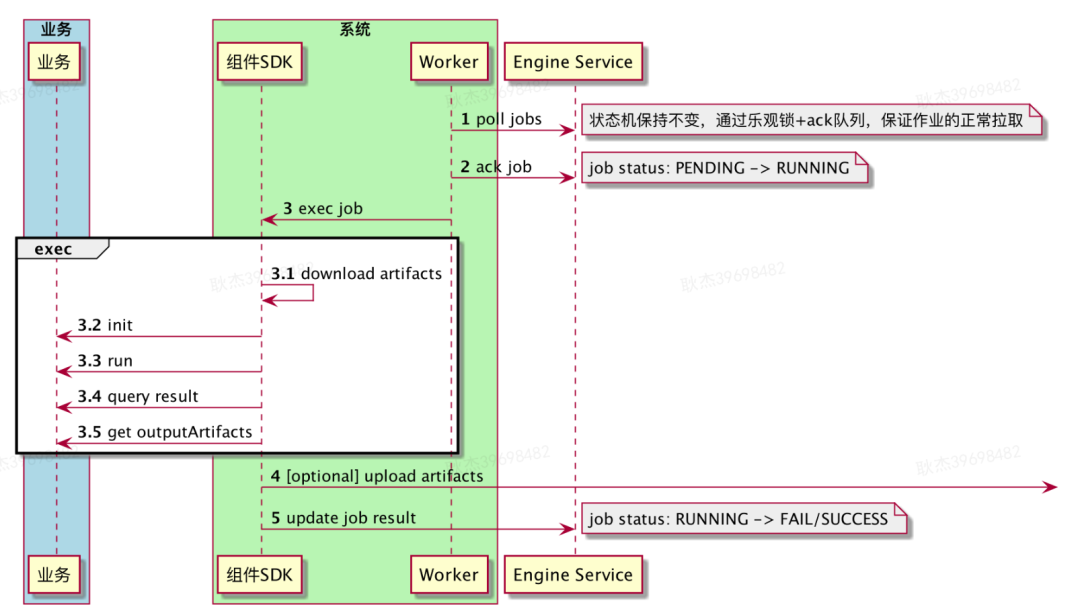



5. 后续规划
-
借助Serverless等云原生技术,探索更轻量、高效的资源管理方案,提供更精细化的资源策略,从资源的弹性、启动加速、环境隔离三个方面为业务提供更优的资源托管能力。
-
面向组件开发者,提供从开发、上线到运营的一站式开发管理平台,降低组件开发、运营成本,使更多工具方、个人开发者能参与其中,共同打造丰富多样的业务场景,形成良性的组件运营生态。
6. 本文作者
本文转载自耿杰 春晖 志远 美团技术团队,原文链接:https://mp.weixin.qq.com/s/dqsejshVzU7v79BuTSb8RA。