
了解 YARN的容量调度器的基本功能通常是在各种部署中需要处理的一个概念。虽然容量管理涉及共享、扣款和预测等许多方面,但本博客的重点将放在可供平台操作使用的主要功能上。除了基本功能之外,还将复审一些在设计或使用队列时经常遇到的问题。
容量和分层设计
YARN 为其调度的资源定义了最小分配和最大分配:今天的内存和/或CPU核心。每个运行 YARN 工作线程的服务器都有一个 NodeManager,它提供了可用于调度的内存和/或内核的资源分配。来自所有NodeManager的资源集合作为容量调度器可用的所有资源的“根”提供。
容量调度器的基本原理是围绕队列的布局和资源分配方式。队列以分层的方式设计布局,最上面的父级是集群队列的“根”, 叶(子)队列可以从根这里进行分配,也可以从其自身具有叶的分支分配。容量分配给这些队列作为层次结构中父级的最小和最大百分比。最小容量是指如果集群上的所有内容都运行到最大,队列应该可以使用的资源量。最大容量是一种类似弹性的容量,它允许队列利用未用于填充其他队列中的最小容量需求的资源。


上图中的子队列继承其父队列的资源。例如,对于 Preference 分支,Low 叶队列获得 Preference 20% 最小容量的 20%,而 High队列获得 20% 最小容量的 80%。对于父节点下的所有叶子,最小容量总是必须加起来为 100%。
最低用户百分比和用户限制因子
最小用户百分比和用户限制因子是控制如何将资源分配给他们正在使用的队列中的用户的方法。最小用户百分比是对单个用户在请求时应访问的最小资源量的软限制。例如,最小用户百分比为10%意味着 10 个用户将每人获得 10%,假设他们都在请求它;这个值是软的,这意味着如果其中一个用户要求更少的资源,我们可能会将更多用户放在队列中。
用户限制因子是一种控制单个用户可以消耗的最大资源量的方法。用户限制因子设置为队列最小容量的倍数,其中用户限制因子为 1 意味着用户可以消耗队列的整个最小容量。如果用户限制因子大于 1,则用户有可能增长到最大容量,如果该值设置为小于 1,例如 0.5,则用户将只能获得队列最小容量的一半. 如果您希望用户也能够增长到队列的最大容量,设置大于 1 的值将允许最小容量被用户多次超越。
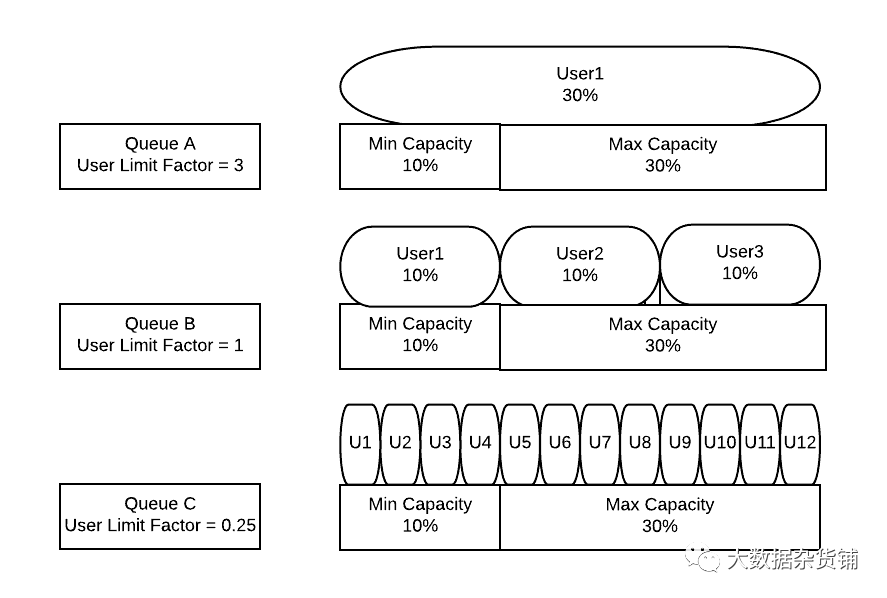
最初可能不直观的一个常见设计点是由工作负载而不是由应用程序创建队列,然后使用用户限制因子通过使用小于 1.0 的值来防止单个用户单独接管队列。该模型通过为每个 LoB 创建一个队列而不是通过按工作负载创建队列以创建可预测的队列行为来允许队列创建螺旋式失控,从而支持更简单的操作。一旦集群被充分利用并且有应用程序队列等待运行较低的用户限制因子将是控制租户之间资源共享的关键。
最初,由于使用较小的用户限制来限制用户资源,这可能无法在他们的 Hadoop 平台之旅开始时提供集群利用率,有很多方法,但需要考虑的是,最初允许单个租户使用可能是合理的在一个小集群(比如 10 个节点)上,但在扩展平台占用空间时降低用户限制因子,以便每个租户保持与添加新节点之前相同数量的可分配资源。这让用户可以保留他的初始体验,但在不降低原始用户体验的情况下,随着它的增长为新用户腾出空间以轻松获得分配的容量,因此无法接管整个集群。
原型
设计队列原型来描述队列中租户的有效行为提供了一种衡量更改的方法,以查看它们是否符合或偏离预期。虽然绝不是工作负载行为的完整列表,但下面是一个很好的起点。根据应用程序和最终用户正在执行的模式类型,创建您自己的组织所需队列类型的定义。
-
AD-HOC
-
这是可能运行随机用户查询、未知工作负载和新工作负载的地方,对资源分配行为没有预期,但可以作为初始运行应用程序以了解每个应用程序调整需求的好地方。
-
PERFERENCE
-
这些应用程序应该先获取资源并保留更长时间。这可能是出于多种原因,例如赶上应用程序、紧急运行或其他操作需求。
-
MACHING LEARNING
-
机器学习应用的典型特征是它们的运行时间长和大量或密集的资源需求。通过大大延长持续时间,终止某些机器学习工作负载的任务可能会产生长期影响
-
DASHBOARDING
-
低并发(刷新率),但每天的查询数量很高。仪表板需要在预期时间刷新,但工作负载非常可预测
-
EXPLORATION
-
探索用户需要低延迟查询,并且需要吞吐量来处理非常大的数据集。在用户探索以提供交互式体验的整个过程中,资源可能会被保留以供使用
-
BATCH WORKFLOW
-
旨在为转换和批处理工作负载提供一般计算需求。安装程序最关心的是应用程序的吞吐量,而不是单个应用程序的延迟
-
ALWAYS ON
-
总是在没有完成概念的情况下运行的应用程序。在等待新工作到达时保持资源供应的应用程序。Slider 部署的实例,例如 LLAP/Impala
容器流失
队列中的流失最好描述为新容器的不断存在和启动。这种行为对于拥有一个行为良好的集群非常重要,因为队列可以快速重新平衡到它们的最小容量并公平地平衡其用户之间的队列容量。流失的反模式是长期存在的容器,它分配自己并且从不释放,因为它可以防止资源的适当重新平衡,在某些情况下它可以完全阻止其他应用程序启动或队列恢复其容量。如果队列要增长到弹性空间但从不释放其容器,则如果不使用抢占,则弹性空间将永远不会被返还给已得到保证的队列。
容量调度器的特性和行为
CPU调度(DRF(Dominant Resource Fairness))
默认情况下不启用 CPU 调度,CPU调度允许在不考虑强制使用或首选分配的情况下超额订阅内核。如果使用 CPU 调度,许多批处理驱动的工作负载可能会降低吞吐量,但可能需要严格的 SLA 保证。一种称为Dominant Resource Faieness (DRF) 的方法用于决定为哪种资源类型将使用率加权:DRF 采用最常用的资源并将您视为使用最高百分比进行调度。
CPU调度有两个主要部分
-
分配和放置
-
执行
只需启用 CPU 调度即可解决分配和放置问题,以便调度器开始使用DRF算法和 VCores 节点管理器的报告。这解决了一些新问题,例如最终用户使用 1 个或 2 个执行器但每个执行器 8 个内核来调度其 Spark 应用程序,然后由于可用内存过多而影响在这些节点上运行的所有其他任务。通过简单的启用CPU 调度,其他任务将不再被配置到服务器上,因为所有内核都被利用并在集群中找到其他首选位置来放置任务。
通过使用 CGroups 来解决强制执行的问题。这允许 YARN 确保如果任务要求单个 vcore,他们不能使用超过请求的资源。可以启用不使用时的 vcore 共享,或者严格执行仅调度的内容。节点管理器还可以配置服务器上的最大 CPU 使用量,它们将允许所有任务总计,这允许内核保证操作系统功能。
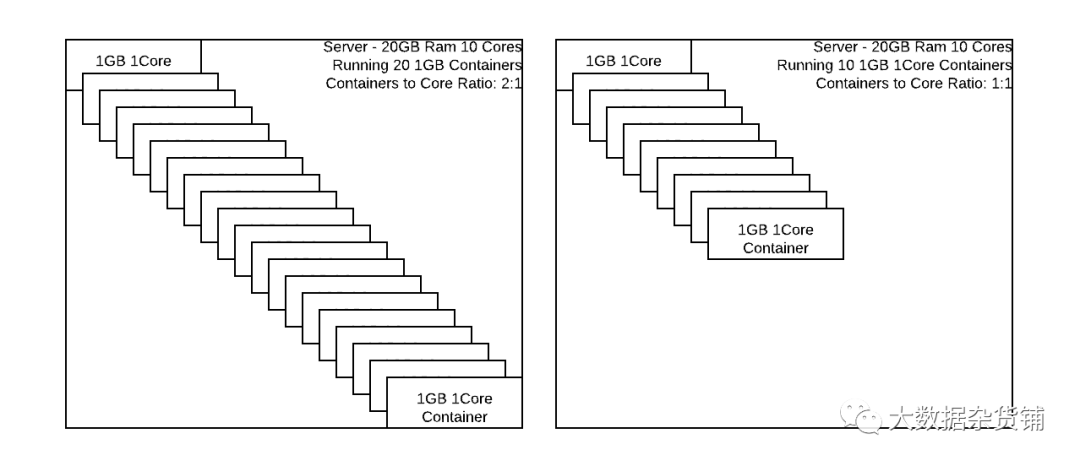
上图显示了如果受限于最小资源(通常是 CPU 内核),并发的容器可以变化的范围。不太可能需要真正的 1:1 的内核与容器比率,但最好留给这方面的调优监控历史系统指标来评估,然后增加或减少调度器可用的 NodeManager 的VCore 数量,以允许给定服务器组上的更多或更少的容器。
抢占
当一个应用程序在其队列中使用弹性容量而另一个应用程序提出要求返回其最小容量(在另一个队列中用作弹性容量)时,传统上应用程序必须等待任务完成才能获得其资源分配. 在启用抢占后,可以回收其他队列中的资源,以将最小容量提供给需要它的队列。抢占会尽量不彻底杀死应用程序,并且会在最后使用reducer,因为如果它们必须重新运行,它们必须重复更多的mapper工作。从排序的角度来看,抢占首先查看最年轻的应用程序和大多数超额订阅的应用程序以进行任务回收。
抢占有一些非常具体的行为,其中一些不能按用户预期的方式运行。最常见的预期行为是队列在自身内部抢占以平衡所有用户的资源。这种假设是错误的,因为目前抢占仅适用于队列,用户之间队列内的资源不平衡需要寻找其他方法来控制这一点,例如用户限制因子、改进的队列流失和队列的 FIFO/FAIR 策略。

抢占的另一种行为是,如果抢占无法提供足够的资源来满足另一个的资源分配请求,则它不会抢占资源。虽然通常情况下这对于大型集群来说不是问题,但对于具有大量最大容器大小的小型集群可能会遇到这样一种情况,即抢占未配置为回收最大可能大小的容器,因此根本不会执行任何操作。用于控制此行为的主要属性是 Total Preemption Per Round 和 Natural Termination Factor。Total Preemption Per Round 是集群上可以立即被抢占的资源百分比,Natural Termination Factor 是请求的总集群 (100%) 中将被抢占到每轮总抢占的资源百分比。
最后一个误解是抢占将重新平衡希望增长到其中的队列之间的最大(弹性)容量使用。最大容量仅以先到先得的方式提供。如果单个队列已经接管了所有集群容量,并且另一个应用程序在需要返回其最小容量的队列中启动,则只有最小容量将被抢占,并且其他队列正在使用的所有最大容量将一直保留到容器自然释放。
有关配置抢占的更多详细信息,请参阅此处的博客https://hortonworks.com/blog/better-slas-via-resource-preemption-in-yarns-capacityscheduler/
队列排序策略
目前,Capacity Scheduler 支持两种类型的排序策略:FIFO 和 FAIR。队列开始的默认值是 FIFO,根据我的经验,这不是客户期望从他们的队列中获得的行为。通过在 Queue Leaf 级别在 FIFO 和 FAIR 之间进行配置,您可以创建导致吞吐量驱动处理或在运行的应用程序之间共享公平处理的行为。关于排序策略需要了解的一件重要事情是,它们在队列中的应用程序级别运行,而不关心哪个用户拥有应用程序。
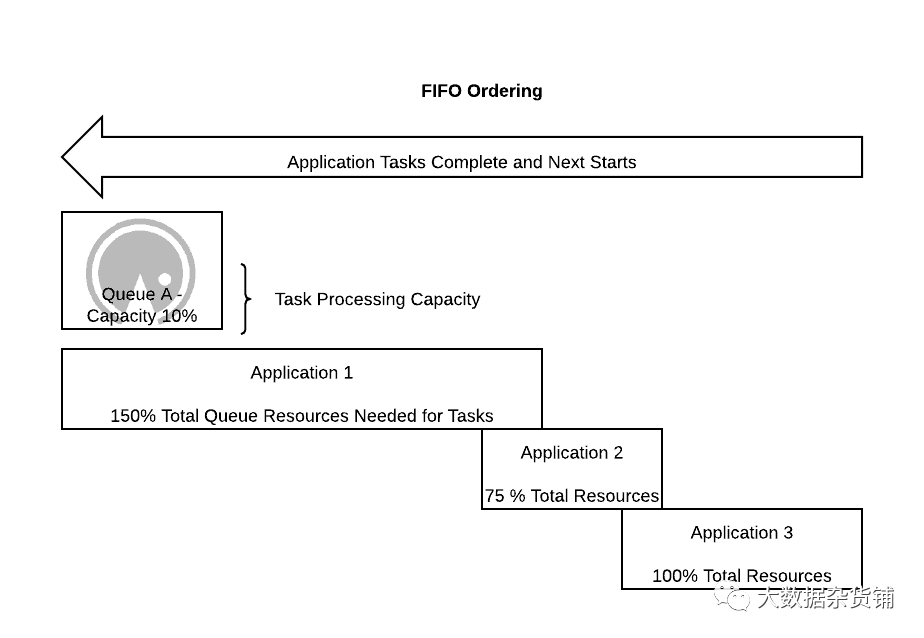
使用 FIFO 策略,应用程序按从旧到新的顺序评估资源分配。如果应用程序有未完成的资源请求,它们会立即得到满足,先到先得。这样做的结果是,如果一个应用程序有足够多的未完成请求,他们将在完成之前多次消耗整个队列,他们将阻止其他应用程序启动,同时作为最旧的应用程序首次分配资源。正是这种行为对用户来说是最出乎意料的,并造成了最大的不满,因为用户甚至可以用自己的应用程序阻止自己的应用程序!
通过使用 FAIR 排序策略,这种行为在今天很容易解决。当在叶子队列上使用 FAIR 排序策略时,应用程序首先评估资源分配请求,应用程序首先使用最少的资源,最后使用最多的资源。这样,进入队列且没有资源进行处理的新应用程序将首先被要求为其所需的分配开始。一旦队列中的所有应用程序都拥有资源,它们就会在所有请求资源的用户之间得到公平的平衡。
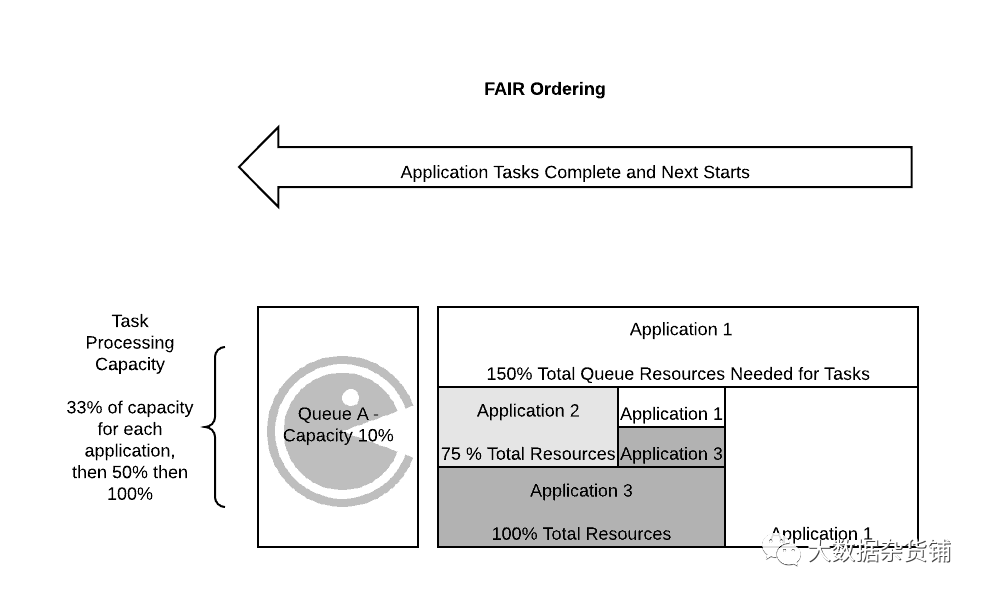
请务必注意,仅当队列中有良好的容器流失时才会发生此行为。因为队列内部不存在抢占,资源不能在其中强制重新分配,并且 FAIR 排序策略只关注新的资源分配,而不是当前的资源分配;这是什么意思?如果队列当前用于从未完成或长时间运行而不允许队列中发生容器搅动的任务,则将保留资源并仍然阻止应用程序执行。
用户名和应用程序驱动的计算
尝试提供分配时,容量调度器中的计算会查看两个主要属性:用户名和应用程序 ID。当涉及到在队列方面的用户之间共享资源时,例如最小用户百分比和用户限制因子,都查看用户名本身;如果您为多个用户使用服务帐户来运行作业,这显然会导致一些冲突的问题,因为只有 1 个用户将出现在容量调度器中。在一个队列中,哪个应用程序获得资源分配是由叶队列排序策略驱动的:FIFO 或 FAIR,它们只关心应用程序而不关心运行它的用户。在 FIFO 中,资源首先分配给队列中最旧的应用程序,只有当它不再需要任何资源时,下一个应用程序才会获得分配。对于使用最少资源的 FAIR 应用程序,首先询问它们是否有未决的分配,如果有,则检查下一个资源最少的应用程序;这有助于与通常使用它们的应用程序平均共享队列。
默认的队列映射
通常,为了针对特定队列,用户提供一些配置信息,告诉客户端工具请求什么队列。但通常用户使用难以将配置传递到下游以针对特定队列的工具。使用默认的队列映射,我们可以通过其用户名或所属组将实体路由到特定队列中。请注意,默认队列路由配置匹配首先出现的路由属性。因此,如果在与用户匹配的用户映射之前提供了组映射,则他将被路由到该组的队列。
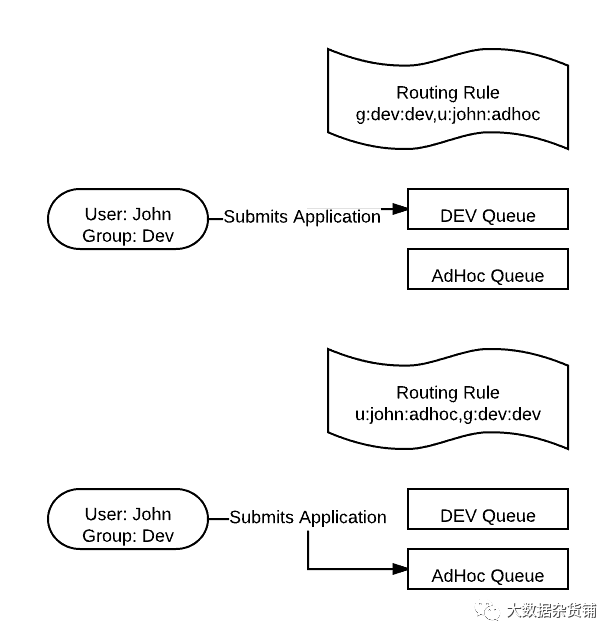
优先级
当资源分配到多个队列时,相对容量最低的队列首先获得资源。如果您希望有一个高优先级队列在其他人之前接收资源,那么更改为更高优先级是一种简单的方法。如今,将队列优先级与 LLAP 和 Tez 结合使用可以实现更多的交互式工作负载,因为可以为这些队列分配更高优先级的资源,以减少最终用户可能遇到的最终延迟。
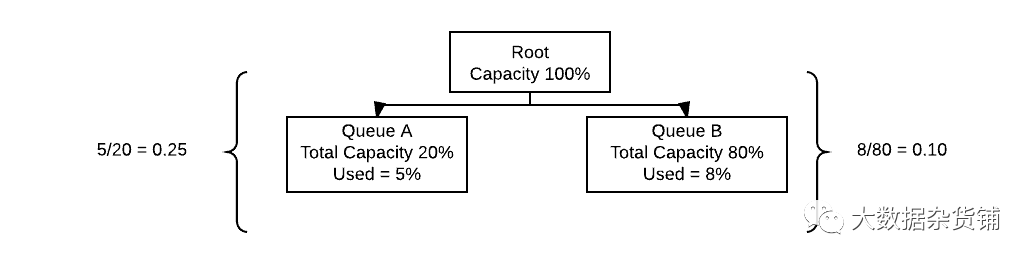
上面的两个队列提供了一个示例,说明如何在不被队列优先级修改的情况下使用相对容量。在这种情况下,即使队列 A 比队列 B 小,并且当队列 B 使用更多绝对资源时,它也被选为首先继续接收它们,因为它的相对容量低于队列 A。如果所需的行为要求队列 A 始终首先接收资源分配,队列优先级应高于队列 B。分配优先级时,较高的值表示较高的优先级。
标签
标签更好地描述为集群的分区。所有集群都以一个默认标签或分区开始,这是独占的,因为当新的标签分区添加到集群时,它们不会与原始默认集群分区共享。标签在创建时被定义为独占或共享,并且节点只能分配一个标签。标签的更常见用途是针对集群中的 GPU 硬件或仅针对集群的特定子集部署许可软件。如今,LLAP 还使用标签来利用专用主机来处理长时间运行的进程。
共享标签允许其他标记分区(例如默认集群)中的应用程序增长到其中,并在没有特定应用程序请求标签的情况下利用硬件。如果出现一个专门针对标签的应用程序,那么正在使用它的其他应用程序将被标记节点抢占,以便需要它的应用程序可以使用它。专属标签就是这样,专属的,不会被任何人分享;只有专门针对标签的应用程序才会单独在它们上运行。为叶队列提供对标记分区的访问,因此能够提交给它们的用户能够以标签为目标。如果您希望将用户自动路由到标签,请创建一个自动使用 GPU 标签的 GPU 队列,这是可能的。
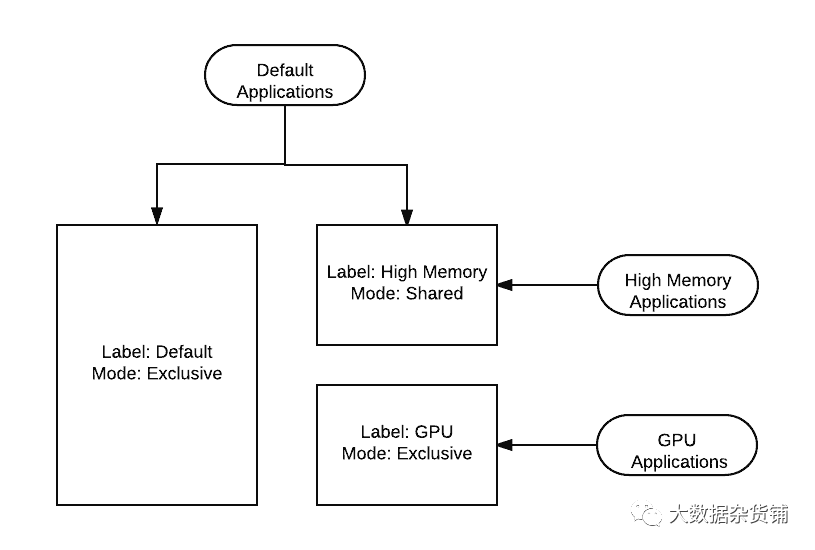
队列名称
队列叶名称对于容量调度器必须是唯一的。例如,如果您在容量调度器中创建了一个队列作为 root.adhoc.dev。dev 将必须作为所有队列名称的叶子是唯一的,并且您不能拥有 root.workflow.dev 队列,因为它不再是唯一的。这与仅使用叶名称而不是整个复合队列名称来指定提交队列的方式是一致的。叶子的父母永远不会直接提交,也不需要是唯一的,因此您可以毫无问题地拥有 root.adhoc.dev 和 root.adhoc.qa,因为 dev 和 qa 都是唯一的叶子名称。
限制每个队列的应用程序
通过将许多应用程序启动到队列中来产生队列,这样没有一个应用程序可以有效地完成,这可能会产生瓶颈并影响 SLA。在最坏的情况下,整个队列会陷入僵局,如果没有管理员物理地杀死作业以释放资源用于计算任务,则无法处理任何事情。这很容易通过限制叶队列中允许运行的应用程序总数来防止,或者可以控制应用程序主机可以使用的叶资源百分比。默认情况下,此值通常相当大,超过 10,000 个应用程序(或叶资源的 20%),并且可以根据需要为每个叶配置,否则该值从叶的先前父队列继承。
容器规格
许多使用容量调度器的人都不知道容器的大小是最小分配的倍数。例如,如果您的每个容器的最小调度器的内存大小是 1GB,并且您请求了一个 4.5GB 大小的容器,那么调度器会将这个请求四舍五入到 5GB。如果最小值非常高,这可能会造成很大的资源浪费问题,例如,如果我们要求 5GB,我们将获得 8GB 的最低 4GB,从而为我们提供 3GB 的额外 GB,而我们甚至从未计划使用这些资源!配置最小和最大容器大小时,最大值应能被最小值整除。

原文作者:Joseph Niemiec
原文链接:https://blog.cloudera.com/yarn-capacity-scheduler/
本文为从大数据到人工智能博主「bajiebajie2333」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/7851/