
本文翻译自《Tweaking the BookKeeper Protocol – Unbounded Ledgers》,作者 Jack Vanlightly,Apache BookKeeper Committer。StreamNative 校对并整理。
译者简介
朱哲,现就职于Shopee Engineering Infra团队,初次接触 Pulsar 开源社区 目前正在参与社区文档的翻译工作,期望早日全面了解社区并期待能贡献代码~
在上一篇文章[1]中,我描述了必要的协议更改用于确保关闭的 ledger 中所有的 entry 都能够达到 Write Quorum (WQ),即写入的 ledger 超过 Ack Quorum,并且打开(OPEN)的 ledger 中除最后一个 fragment 之外的 entry 全部达到 Write Quorum。
在这篇文章中,我们将研究对协议的另一项调整,允许 ledger 无界,支持多个客户端在其生命周期内对 ledger 写入数据。
为什么选择无界的 ledger
目前,ledger 是有界的。如果要创建无界日志,则需要创建一组有界的 ledger 日志(形成日志的日志)。例如,Pulsar Topic 实际上是一个有序的 ledger 流。核心的 BookKeeper 协议不支持开箱即用的无界日志协议。如果想使用,必须在 BookKeeper 顶层封装该逻辑,但这并非易事。
据我所知,log-of-ledgers 的实现由 Apache Pulsar 中的 Managed Ledger 模块和 BookKeeper 仓库中的一部分分布式日志库(Distributed Log library)组成。这两个模块本身就相当复杂。
但是 ledger 是否需要有界?难道我们不能只允许单个 ledger 成为无界流并使其包含在核心协议中吗(即使用单个 ledger 存储所有消息)?UnboundedLedgerHandle(无界的 ledger 处理器)可能是比现有替代方案更简单的流 API(极大地降低代码量)。
日志的日志
使用 BookKeeper 进行日志存储的好处在于它的动态特性。例如,当横向扩展 bookie 节点时,它们会很快开始自动负载均衡。原因之一是随着新 ledger 的增加,新的 bookie 能用来托管这些 ledger。Ledger 是更大日志中的日志段,每个日志段可以托管在一组不同的 bookie 上。
但是单个 ledger 已经是日志段(即 fragment)的日志。每次写入失败时,系统会给已有 ledger 追加新的 fragment,从而导致系统发生 ensemble change。每个 ledger 都包含一个或多个 fragment,每个 fragment 都共享同一个 bookie ensemble。出于这个原因,从日志直接对应到 ledger 并不是获得这种良好扩展能力的唯一方法。
在当前的协议下,Fragment 会在写入失败时新建。但对于无界的 ledger,我们还可以设置每个 fragment 的最大容量,一旦当前 fragment 达到该容量,将会触发 ensemble change。


图 1. 从 fragment 的角度看无界与有界 ledger 的对比
在无界 ledger 中,一个流(例如 Pulsar topic)是一个单独的 ledger,由跨 bookie 集群存储的 fragment 日志组成。
无界 ledger 的协议更改
将当前协议修改为无界 ledger 所需的变动比较小,毕竟大部分协议及代码已经存在。

更改此协议的核心是要将 ledger fencing 从 boolean 类型(即“是否为 fenced”) 改为整数 term,当新客户端接管数据写入时此 term 的值会增加。
我们从一个 ledger 只能由创建它的客户端写入的模型转变为一个 ledger 可以被任意客户端写入,但一次只能由一个客户端写入的模型。就像在常规的 BookKeeper 协议中一样,假设协议外部的客户端存在 leader 选举,那么在正常情况下,应该只有一个客户端尝试写入 ledger。即便有两个或多个客户端争夺控制权,该协议仍然适用。
Fencing 保证了 BookKeeper 只有一个编写器(Pulsar Broker)可以写入 Ledger,此机制在协议修改后将会被 term 机制替代。当多个客户端协调后将会选举出一个写入 ledger 的客户端,同时会在元数据和最后一个 fragment 所在的 bookie 中记录该 ledger。恢复流程会在 term 的开始执行,而非只在 ledger 关闭时。
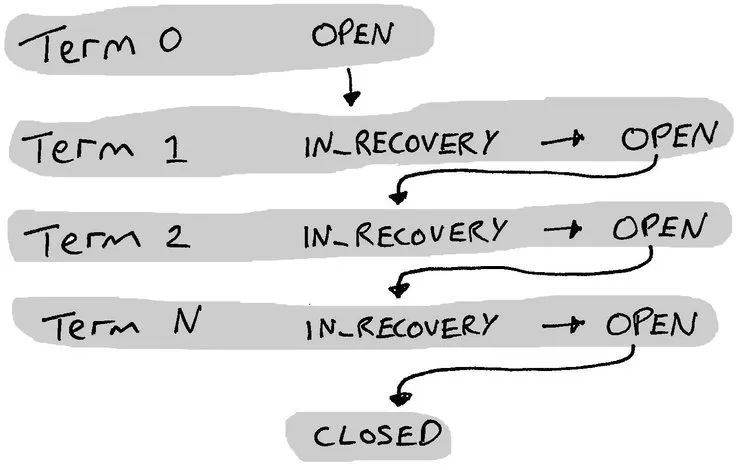
图 2. Ledger 的生命周期的状态及 term
每个 fragment 都没有绑定到任何特定的 term,term 只是一种 fencing 机制,防止之前的 leader 进行写入操作,从而影响集群数据。
所下图所示,使用 term 机制时,元数据会新增一个字段。由于 ledger 长期存储的特性,ensemble 列表(即 fragments)可能会变得非常大,所以现有的 ensemble 字段需要修改。为了执行数据保留策略,使用 BookKeeper 的系统需要能够删除 fragment,而不是 ledger。

图 3. 元数据获新增了一个 item 字段。需要重新考虑数据过期的最小纬度,因为 fragment 列表可能会变得非常大。
Term 机制与 fencing 机制非常相似。当一个新客户端想要对 ledger 进行写入时,首先会在 ledger 元数据中增加 term 的值(也就是前文协议中新增的字段),然后执行 ledger 恢复操作。客户端像往常一样将 LAC 请求发送到当前 fragment,但和之前不同的是使用新的 term 机制,而不是 fencing 标志。
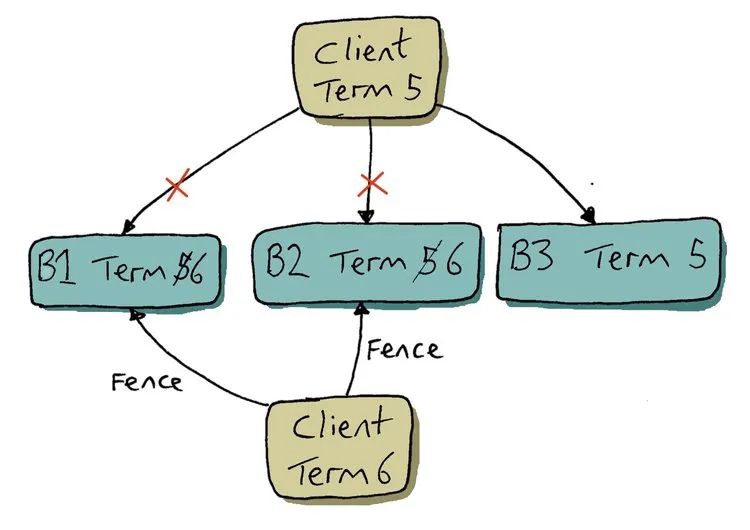
图 4. Fencing 过程包含新的 term,而不是 fencing 标志。
以下请求需要包含客户端当前的 term 信息:
-
• normal adds
-
• recovery adds
-
• recovery LAC reads
-
• recovery reads
正常的读取数据与 term 无关,唯一相关的仍然是 LAC (Last Add Confirmed),即最后一个写成功的消息 ID。
如果 bookie 的 ledger term 小于或等于请求的 ledger term,它会接受该请求并更新当前的 ledger term。如果 bookie 有更高的 ledger term,它会以 InvalidTerm 响应拒绝请求。
当客户端收到 InvalidTerm 响应时,它应该退出,停止继续写入数据。它可以检查它是否仍然是假定的 leader(存在于此协议外部),如果仍然是,则会先刷新其 ledger 元数据以重新接入。
对 ledger 恢复流程的一个额外修改是,恢复时必须删除最后一个 fragment 中前一个 term 的所有脏数据(dirty entry),实现方法是在恢复期间写回的最后一个 entry 中包含一个新的 “truncate”(截断)标志。我们必须保证最后一个 entry 被写入最后一个 fragment 的所有 bookie,因此我们必须利用“确保 Write Quorum”中的一些逻辑来实现这一点。
Term 的使用范畴
到目前为止,我想到了两种主要的设计,每一种都以不同的方式使用 term。
仅将 term 用于 fencing
本文所谈及的 term 并未将其作为 entry 标识符或 fragment 标识符的一部分,它仅用于 fencing。然而准确来说,这里所谈到的 term 设计还至少需要以下二点:第一,上一篇文章[2]中详述的“确保 Write Quorum”更改的一部分内容;第二,一个最终的截断 no-op entry 作为恢复期间要写回的最后一条 entry。请查看以下内容以了解原因:
-
• 客户端 c1 写入两条 entry {Id: 0, value: A} 和 {Id: 1, value: B} 到 bookie b1、b2 和 b3。
-
• entry0 成功写入 b1、b2 和 b3,而 entry1 只成功写入 b1。
-
• 客户端 c2 此时接管并成为 leader。执行数据恢复时,检测到最后一个可恢复的数据是 entry0,于是将 entry0 写回 b1、b2 和 b3,并更新 ledger 状态为打开(OPEN),允许新数据写入。
-
• 客户端 c2 写入一条 entry {id: 1, value: C} 到 b1、b2 和 b3。
-
• b2 和 b3 回复 ack 确认成功写入该消息,b1 此时暂无响应。由于已写入 entry 的 bookie 数目超过 Ack Quorum,因此客户端 c2 认为写入成功并忽略 b1 的超时。
-
• 此时,日志会产生差异,不同 bookie 上 entry1 所对应的值不同,即 {Id: 1, value: B} 和 {id: 1, value: C}。
要避免这种情况,可以添加一个带有 “truncate”(截断)标志的 no-op entry 作为要恢复的最后一个 entry。当 bookie 收到带有 truncate 标志的 entry 时,它会删除所有具有更高 id 的 entry。借助 truncate 标志并确保达到 Write Quorum,可以确保最后一个 fragment 中的任何 bookie 都没有截断任何脏数据。这意味着 BookKeeper 客户端需要知道这些 no-op entry 并丢弃它们。
这种方法的好处是 term 只是 ledger 元数据中的一个额外字段,并且 bookie 只需要将 term 存储在 ledger 索引中,就像现在使用 fencing 一样。term 不需要与每个具体的 entry 一起存储。
缺点则是引入了 no-op entry。
在恢复写入时,我们只需要确保 Write Quorum,因此正常写入可以继续使用现有行为。
将 term 作为 entry 标识符
另一种解决方案是使 term 更深入地集成在协议中,将 term 作为 entry 标识符的一部分写入,这可以防止上述日志差异的情况。c1 写入的未提交 entry 1 不会与 c2 写入的 entry 1 混淆,因为它们具有不同的 term。
此时元数据需要包括每个 term 的 entry 范围,以便客户端在读取给定 entry 时可以包含正确的 term。
我们不需要 fragment 和 term 进行关联,这样做的原因是会使元数据更加紧凑。
这种方法的好处是我们不需要在恢复写入时确保 Write Quorum,缺点则是 term 必须与每个 entry 一起存储。
之后,我可能会构建一个无界 ledger 的设计,其中包括将 term 作为 entry 标识符的一部分。
正式验证
基于需要确保 Write Quorum 的规范,我已经通过 TLA+ 验证了无界 ledger 协议的更改。
请参考我的 GitHub 仓库 BookKeeper TLA+[3] 查看相关规范验证。
最后的思考
目前上文提到的相关问题只是对于这种架构的预想,因为 Splunk 现在没有对无界 ledger 的迫切需求。但我确实认为它可以在未来成为对 BookKeeper 的重要补充,并且可能适用于新的场景。
从修改后的 LedgerHandle 接口中生成流 API 的协议更改不是太大,但实际上有许多次要影响,例如会影响自动恢复和垃圾收集。因此,协议的变更绝非无足轻重。
无论如何,探索协议的变化很有趣。它揭示了协议为何如此的一些原因以及所做出的权衡决策,表明了 TLA+ 对这类系统的价值,因为它让我们能轻而易举地验证各种想法。
此外,还可能有一些不同的设计可供我们选择与探索。
更新 1:我的原始设计不包括截断(truncation)。当使用更大的模型时,TLA+ 规范发现了日志差异的反例。为了避免这种情况,在新 term 的恢复阶段恢复的最后一个 entry 需要一个新的 “truncation” 标志。
本文转载自 Jack&朱哲 StreamNative,原文链接:https://mp.weixin.qq.com/s/gzSe3AdJEwvWixpNc3qJ0g。