


分享嘉宾:朱凯 明源云 大数据平台首席专家
编辑整理:肖鹏 VIVO
出品平台:DataFunTalk
导读:都说天下武功唯快不破,ClickHouse 从2016年诞生至今就一直快字著称。ClickHouse不仅性能快,其发版速度也快得惊人。仅在2021年就发布了数千个新特性,今天主要分享的内容是对ClickHouse的简单科普以及它在2021年中发布的5个重要的特性。
全文主要介绍以下两点:
-
ClickHouse全貌速览
-
2021年 Top 5 Features
01
ClickHouse全貌速览
1. 为什么叫ClickHouse
ClickHouse的全称由两部分组成,第一个是Click Stream点击流,第二个是数据仓库Data Ware House,把这两个单词的一首一尾合起来就叫ClickHouse。如果大家很了解这个领域的话,只通过这个名字,就可以一眼看出它的初衷,ClickHouse最原本要去解决的问题是如何支撑基于点击流的数据仓库。

2. 背景
ClickHouse最开始是从在Yandex发迹起来的。Yandex是一家来自俄罗斯的互联网公司,以搜索引擎起家,是俄国第一的搜索引擎。除了搜索引擎以外,还有50多种b2b和b2c的产品,体量很大。众所周知,搜索引擎的很大一部分营收是广告流量带来的,所以通常一家搜索引擎公司的背后都会伴生一个流量站点的分析网站。Yandex也有一个自己的流量站点分析工具平台,叫Metrica,它是现在全球第三大网络流量分析工具,每天处理超过30亿个事件,其中分析覆盖数百万网站,每天拥有超过10万分析师用户,而ClickHouse就是在背后去支撑这个平台运转的。
在2021年,ClickHouse的初创团队也独立成立了同名的商业化公司,并在9月获得了5000万美元的A轮投资,同年10月获得了2.5亿美元的B轮投资,公司聚焦在ClickHouse云服务上。
3. 显著特点
①入门简单
是一款OLAP数据库,具备完整的DBMS功能,支持SQL,提供DDL、DML语句。以ROLAP模型为主,同时也支持 MOLAP(特殊的表引擎+物化视图),支持 Projection。
②Everything is table
-
面向表编程,提供数十种表引擎,包含代理访问外部资源(例如Zookeeper,HDFS,文件等)。
-
内置Mysql,PostgreSQL binlog监听。
-
甚至贡献者名单也有专门一张表。
③接口丰富
提供TCP、HTTP底层访问接口,提供JDBC、CLI等封装接口。
兼容 MySQL、Postgres 客户端 支持Java、Python、Nodejs等众多第三方接口,内置数百个函数。
④在线查询
实时应答,无需预处理。也支持立方体预聚合。
⑤分布式架构
MPP架构,支持集群模式,支持数据分区、分片、副本。
⑥高性能
列存、高压缩、向量化引擎,秒杀一切的性能。单机部署,即拥有高性能。
⑦安全可靠
熔断机制,防误删机制。
⑧完善的权限系统
RBAC,客户端接入权限,资源访问权限,操作访问权限,数据行级权限。
⑨开源软件,社区活跃
2016年开源,Apache-2.0协议。
850+ Contributors、21.1K+ Star 、4.1K Forks,发版速度和它的性能一样快。
02
2021年 Top 5 Feature
1. 利用JIT提升数十倍查询性能
ClickHouse同时使用了Vectorize query execution(向量化执行)和Runtime code generation(运行时代码生成)。ClickHouse被大家所熟知的是向量行化执行,除此之外,其实它也用到了代码生成技术,这部分的好处主要是有助于L1和L2缓存重用,更好地利用编译器的优化,其中包括更好地执行分支预测,更好地利用cpu指令集。
JIT,Just-In-Time,即时编译是一种Runtime code generation技术。ClickHouse利用JIT可以获得数倍到数十倍的性能提升。

上图是现在CPU架构中各级储存的耗时,L1,L2缓存相比于内存和磁盘有20倍到200倍的性能提升。如果我们能很好的利用L1,L2缓存命中,从硬件角度会有非常大的提升。
从21.6版本开始就可以使用这个新特性了。JIT的基准编译时间在15ms左右,随着代码增长它会线性增长。第一种是在select里面有的表达式运算,ClickHouse会利用JIT去提升性能,普遍有1.5到3倍提升,特殊情况下能达到20倍。第二种是在聚合函数阶段去优化,普遍也有1到2倍提升。
2. 支持基于Lambda的UDF
ClickHouse已经从21.10版本就开始支持了基于Lambda的UDF。虽然不是一个直接的性能提升,但是从应用性角度来说,也是一个性能的提升。目前虽然这个udf相对来讲还比较简单,但其实也能解决很多问题了。

当前是基于一个Lambda表达式的方式去做这个自定义函数Create Function的方式去定义,用Lambda表达式去定义很多自定义函数,然后就可以在查询语句里面去调用。现在ClickHouse存储目录上面会多一个user_defined的数据文件夹,它会把所有的自定义的函数保存在里面。目前这个制定函数也支持嵌套去调用,比较方便。
3. 开窗函数
以前,ClickHouse没有原生的开窗函数,像一些传统数据库,包括hive里面都是有开窗函数的,从那些技术转过来可能会不方便。比如左图,以前要去写一个类似的开窗,可能写很多SQL,可能要用数组JOIN的方式,或者很多数组函数,实践起来很麻烦。从21.3版本以后,有了原生的开窗函数,包括分析函数都已经内置了。现在去在ClickHouse上面想做一些同比环比分析,会比以前方便很多。

4. 支持S3和HDFS存储的零拷贝复制
ClickHouse现在是云原生的,支持分层存储。如果你关注它,会看到它的一条演进轨迹。最开始是单机的,单机即可实现很多高性能查询;然后演进到分布式,利用了比如复制表、分布式表,巧妙地变成了一个分布式架构;再往后,大家在讲云原生,也是可以分层存储、存算分离,有一些存储可以放到S3上,也可以放到HDFS上面去;后来也支持了OSS,目前也是通过原生的分层存储方式向云原生再迈进了一步。在此之前,虽然ClickHouse支持把一些冷数据,或者是部分的数据放到像S3这样的对象存储上面去,但是它的实现比较粗暴。
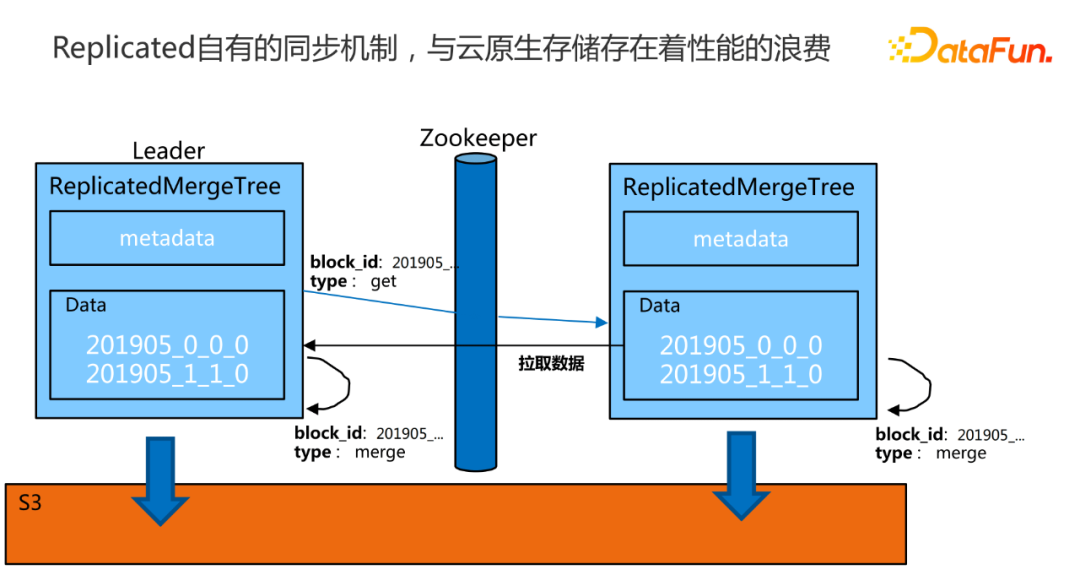
这里简单画了一个图,ClickHouse的副本机制其实是这样的一个过程。两个副本,有一个主副本是leader。当往这个副本去写入一些数据的时候,它在自己写完以后,会通过ZooKeeper去发布一些命令,比如写了左边的一个分区,下面data有比如201905这样一个分区写完了以后,它会通过ZooKeeper去发布一条命令给到另外一个副本,另外一个副本收到这个命令以后,是一个get类型的,就知道要去主副本拉数据,以实现这两个副本之间的同步。ClickHouse的从副本会通过ZooKeeper传递这个指令以后,点对点地直接去找这个Leader,从Leader下载这个分区的数据给到自己。这就是比较简单的,传统的ClickHouse的副本同步机制。目前ClickHouse把它的数据真正放到S3上去了以后,这里就会有一个冲突,S3自己内部已经处理好了数据之间的同步复制,但是这个replica也有一套同步机制, 这两套同步机制在同时运行,就存在着性能浪费,ClickHouse它自己就可以不用再同步了,只是做原数据同步,而把真正的数据同步就交给像S3这样的云原生就可以了。
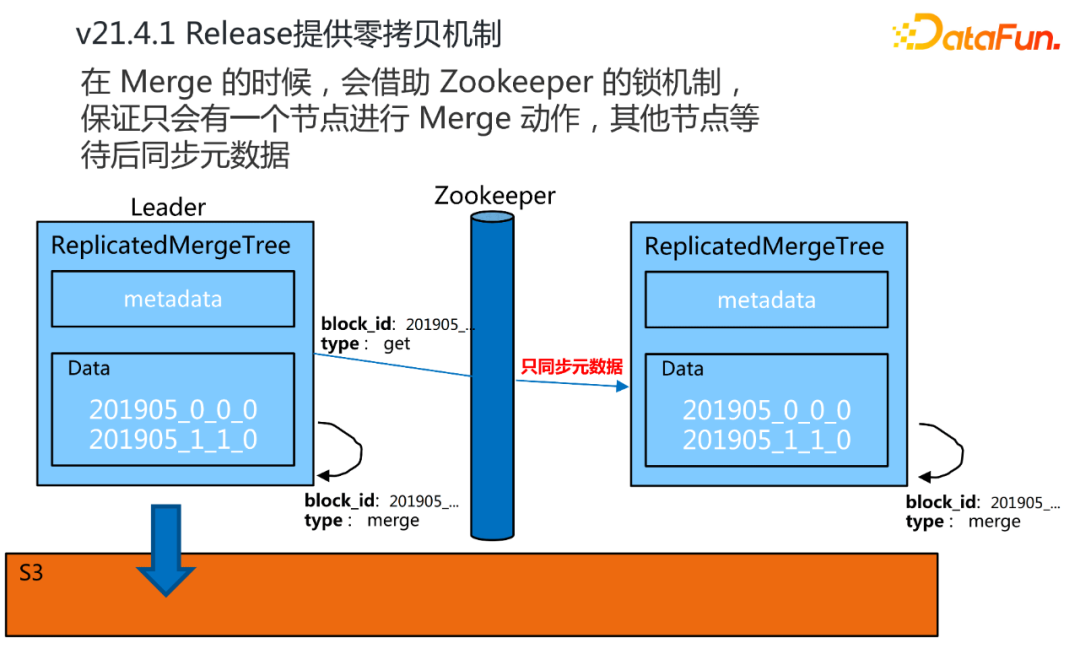
从21.4.1版本之后ClickHouse社区提供了这种零拷贝的机制。简单来讲就是ClickHouse只做元数据同步。在我们向某一个副本去写数据,或者是某一个副本在做合并的时候,它会借助ZooKeeper的锁机制,保证只有一个节点会去做这样的一个动作,然后其他的节点,不会去真正同步数据,或者去合并分区,只是作为一个元数据的同步,而把真正的数据之间的同步复制交给云存储本身。通过这样的一个零拷贝机制,去掉了无谓的性能开销。有了这个特性以后,ClickHouse的可用性变得更强了。
5. Projection
Projection主要是解决了ClickHouse的两个痛点。

第一个痛点是,它的组件只支持一种排序规则。ClickHouse的索引架构是:首先我们通过建表的时候给它指定一个Order By键,它会通过这个排序键去建立稀疏索引,也就是primary.idx。这个稀疏索引是根据组件的排序规则来排序的,它会有一个映射文件以及对应的数据压缩块,通过这种方式去做查询加速。由于只有一种排序规则,如果在数据量很大的情况下,通过组件的这个顺序去做一些过滤和查询,性能是非常好的。但是查询业务往往是千变万化的,不可能所有的查询场景都是通过一套排序规则能把它覆盖到。如果查询的条件不是组件的顺序,那性能就会有所下降。
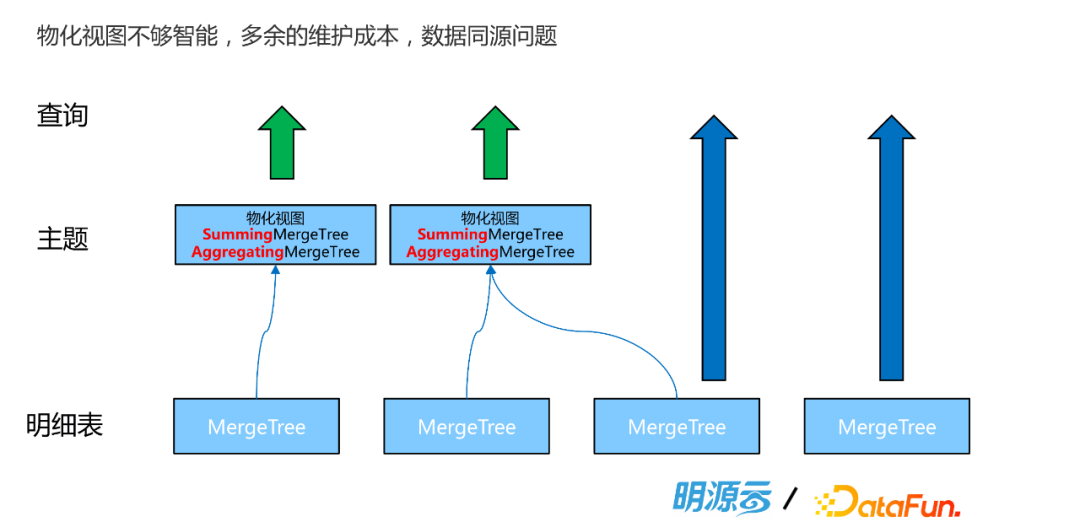
第二个痛点就是物化视图不是那么智能。我们面向一些特定的主题,也是可以利用物化视图。这是因为物化视图是有表引擎的,我们可以通过一些预聚合的表引擎去建Cube,然后让这些数据物化提升查询性能。这样一套架构也是传统数仓的做法,很多数据库也会通过这种物化视图去分层。但物化视图在ClickHouse里是独立的表,因此加上原表就有很多个表,维护成本会很高。而且由于不是同一张表,会存在数据从原表向物化视图的一个流向的过程,这时如果原表发生数据的删除、修改和更新,那么从数据质量的角度也可能存在问题。
为了解决这两个问题提出了Projection,简单来说可以理解成更加智能的物化视图。它有几个特点,第一是Part Level存储,ClickHouse有一张图会看到分区目录的物理布局,数据的物理布局是按分区目录去布局的。普通的物化视图是独立的一张表,而这个Projection是在分区级别,在一张表的分区里面有一个独立的存储,这是一个Part Level的存储。第二是正因为它和原表分区在一起,所以说它的数据是同源的。如果原表的数据变了,那么Projection也会发生变化。第三,Projection的使用是无感的,它更像是原表的一个智能的索引,在查询时会去自动匹配表。对一张表可以创建很多个Projection,查询时直接查这个原表,会根据算法去匹配这个Projection,如果能匹配上,就用一个最优的Projection提供查询加速,如果没有命中还是查原表。有了这个特性以后,会比使用物化视图方便非常多。

比如建一张MergeTree,可以看原表的排序是Order By 4个字段。如果基于这个顺序去查表,比如用CounterID去做条件,性能会很好,但如果换一个字段,比如用EventTime去查,性能就可能会下降。现在可以针对这个原表,去创建一个Projection,把想要的顺序写成一段select语句,即把想要查的列以及排序规则在这里面写好,那么它就会基于这个sql去创建一个Projection。这是在明细查询的角度,如果在聚合分析的角度也是可以的。比如想针对某个group by的场景,去做这种特定主题的加速,那么也创建一个这样的Projection就可以了。在后面查询的时候,就查原表,按sql去查。它只要能匹配上定义的这个sql的范围,就会通过Projection里面的数据去做查询返回,这样的性能将会有很大的提升。
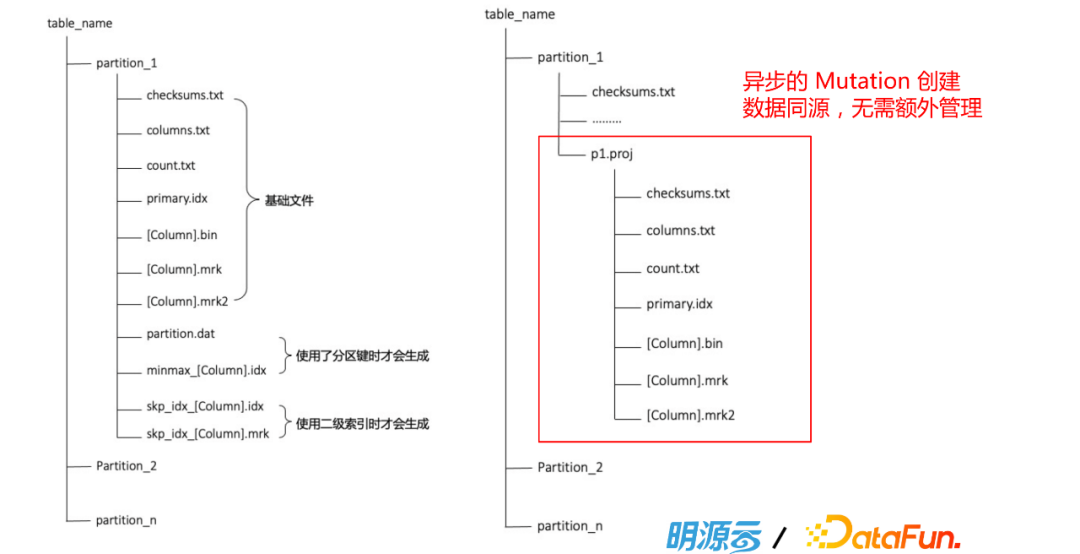
上图就是表内文件存储结构。数据和索引文件会按照不同表不同Part去分隔,且在每个Part文件夹中又会包含许多个文件,其中有元数据(columns.txt),有列相关的索引和数据文件(Column.bin, Column.mrk2,Column.bin),主键索引(primary.idx)等。
右边是一个正常的Projection,和Part目录一一对应。每当我们给表创建Projection时,会在Part文件夹下创建子目录用于记录Projection信息。它和整张表共用同一份元数据,所以它自己是没有这个表的元数据的。然后它会通过一个motivation的异步操作,在分区下面去再生成一个子目录,这个子分区跟我们的分区是一样的。这个子目录存的就是基于一个新的索引的规则和预处理好的数据。当在查询中,能匹配到的Projection时,就会使用部分预处理好的数据直接返回,这也正是加速的本质。具备了这个武器以后,ClickHouse又变强了。比如上图左边是直接去查明细表,可以直接做实时查询,现在有了右边的Projection以后,但是查询速度提升了。但目前Projection不支持跨表,所以对于有跨表的预聚合的场景,还是要利用物化视图。Projection和物化视图可以搭配使用。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
01/分享嘉宾

本文转载自朱凯 DataFunTalk,原文链接:https://mp.weixin.qq.com/s/jUa7wc2PwP-tC8APs9WuJg。