
作者:vivo 互联网服务器团队-Tang Shutao
现如今推荐无处不在,例如抖音、淘宝、京东App均能见到推荐系统的身影,其背后涉及许多的技术。
本文以经典的协同过滤为切入点,重点介绍了被工业界广泛使用的矩阵分解算法,从理论与实践两个维度介绍了该算法的原理,通俗易懂,希望能够给大家带来一些启发。
笔者认为要彻底搞懂一篇论文,最好的方式就是动手复现它,复现的过程你会遇到各种各样的疑惑、理论细节。
一、 背景
1.1 引言
在信息爆炸的二十一世纪,人们很容易淹没在知识的海洋中,在该场景下搜索引擎可以帮助我们迅速找到我们想要查找的内容。
在电商场景,如今的社会物质极大丰富,商品琳琅满目,种类繁多。消费者很容易挑花眼,即用户将会面临信息过载的问题。
为了解决该问题,推荐引擎应运而生。例如我们打开淘宝App,JD app,B站视频app,每一个场景下都有推荐的模块。
那么此时有一个幼儿园小朋友突然问你,为什么JD给你推荐这本《程序员颈椎康复指南》?你可能会回答,因为我的职业是程序员。
接着小朋友又问,为什么《Spark大数据分析》这本书排在第6个推荐位,而《Scala编程》排在第2位?这时你可能无法回答这个问题。
为了回答该问题,我们设想下面的场景:
在JD的电商系统中,存在着用户和商品两种角色,并且我们假设用户都会对自己购买的商品打一个0-5之间的分数,分数越高代表越喜欢该商品。
基于此假设,我们将上面的问题转化为用户对《程序员颈椎康复指南》,《Spark大数据分析》,《Scala编程》这三本书打分的话,用户会打多少分(用户之前未购买过这3本书)。因此物品在页面的先后顺序就等价于预测用户对这些物品的评分,并且根据这些评分进行排序的问题。
为了便于预测用户对物品的评分问题,我们将所有三元组(User, Item, Rating),即用户User给自己购买的商品Item的评分为Rating,组织为如下的矩阵形式:
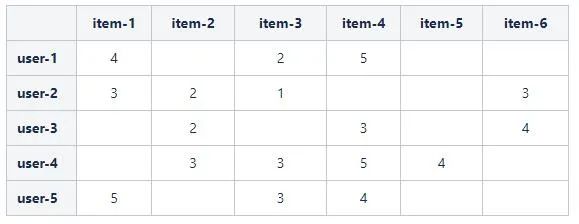

其中,表格包含 m 个用户和n个物品,将表格定义为评分矩阵 ,其中的元素 表示第u个用户对第i个物品的评分。
例如,在上面的表格中,用户user-1购买了物品 item-1, item-3, item-4,并且分别给出了4,2,5的评分。最终,我们将原问题转化为预测白色空格处的数值。
1.2 协同过滤
协同过滤,简单来说是利用与用户兴趣相投、拥有共同经验之群体的喜好来推荐给用户感兴趣的物品。兴趣相投使用数学语言来表达就是相似度 (人与人,物与物)。因此,根据相似度的对象,协同过滤可以分为基于用户的协同过滤和基于物品的协同过滤。
以评分矩阵为例,以行方向观测评分矩阵,每一行代表每个用户的向量表示,例如用户user-1的向量为 [4, 0, 2, 5, 0, 0]。以列方向观测评分矩阵,每一列表示每个物品的向量表示,例如物品item-1的向量为[4, 3, 0, 0, 5]。
基于向量表示,相似度的计算有多种公式,例如余弦相似度,欧氏距离,皮尔森。这里我们以余弦相似度为例,它是我们中学学过的向量夹角 (中学只涉及2维和3维) 的高维推广,余弦相似度公式很容易理解和使用。给定两个向量 和 ,其夹角定义如下:

例如,我们计算user-3和user-4的余弦相似度,二者对应的向量分别为 [0, 2, 0, 3, 0, 4],[0, 3, 3, 5, 4, 0]
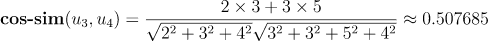
向量夹角的余弦值越接近1代表两个物品方向越接近平行,也就是越相似,反之越接近-1代表两个物品方向越接近反向,表示两个物品相似度接近相反,接近0,表示向量接近垂直/正交,两个物品几乎无关联。显然,这和人的直觉完全一致。
例如,我们在视频App中经常能看到“相关推荐”模块,其背后用到的原理之一就是相似度计算,下图展示了一个具体的例子。
我们用《血族第一部》在向量库 (存储向量的数据库,该系统能够根据输入向量,用相似度公式在库中进行检索,找出TopN的候选向量) 里面进行相似度检索,找到了前7部高相似度的影片,值得注意的是第一部是自己本身,相似度为1.0,其他三部是《血族》的其他3部同系列作品。

1.2.1 基于用户的协同过滤 (UserCF)
基于用户的协同过滤分为两步
-
找出用户相似度TopN的若干用户。
-
根据TopN用户评分的物品,形成候选物品集合,利用加权平均预估用户u对每个候选物品的评分。

例如,由用户u的相似用户{u1, u3, u5, u9}可得候选物品为
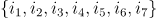
我们现在预测用户u对物品i1的评分,由于物品在两个用户{u1, u5}的购买记录里,因此用户u对物品i1的预测评分为:
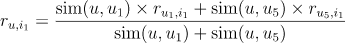
其中 表示用户 u与用户 的相似度。
在推荐时,根据用户u对所有候选物品的预测分进行排序,取TopM的候选物品推荐给用户u即可。
1.2.2 基于物品的协同过滤 (ItemCF)
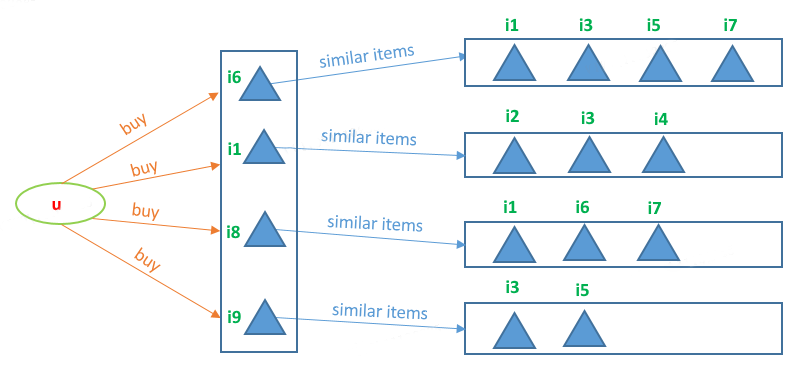
基于物品的协同过滤分为两步
-
在用户u购买的物品集合中,选取与每一个物品TopN相似的物品。
-
TopN相似物品形成候选物品集合,利用加权平均预估用户u对每个候选物品的评分。
例如,我们预测用户u对物品i3的评分,由于物品i3与物品{i6, i1, i9}均相似,因此用户u对物品i3的预测评分为:

其中 表示物品 与物品 的相似度,其他符号同理。
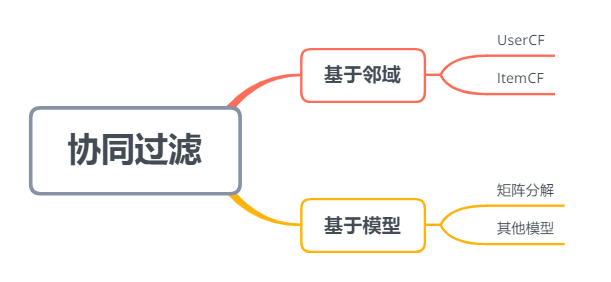
1.2.3 UserCF与ItemCF的比较
我们对ItemCF和UserCF做如下总结:
UserCF主要用于给用户推荐那些与之有共同兴趣爱好的用户喜欢的物品,其推荐结果着重于反映和用户兴趣相似的小群体的热点,更社会化一些,反映了用户所在的小型兴趣群体中物品的热门程度。在实际应用中,UserCF通常被应用于用于新闻推荐。
ItemCF给用户推荐那些和他之前喜欢的物品类似的物品,即ItemCF的推荐结果着重于维系用户的历史兴趣,推荐更加个性化,反应用户自己的兴趣。在实际应用中,图书、电影平台使用ItemCF,比如豆瓣、亚马逊、Netflix等。
除了基于用户和基于物品的协同过滤,还有一类基于模型的协同过滤算法,如上图所示。此外基于用户和基于物品的协同过滤又可以归类为基于邻域 (K-Nearest Neighbor, KNN) 的算法,本质都是在找”TopN邻居”,然后利用邻居和相似度进行预测。
二、矩阵分解
经典的协同过滤算法本身存在一些缺点,其中最明显的就是稀疏性问题。我们知道评分矩阵是一个大型稀疏矩阵,导致在计算相似度时,两个向量的点积等于0 (以余弦相似度为例)。为了更直观的理解这一点,我们举例如下:
rom sklearn.metrics.pairwise import cosine_similaritya = [[],[],[],[]]cosine_similarity(a)
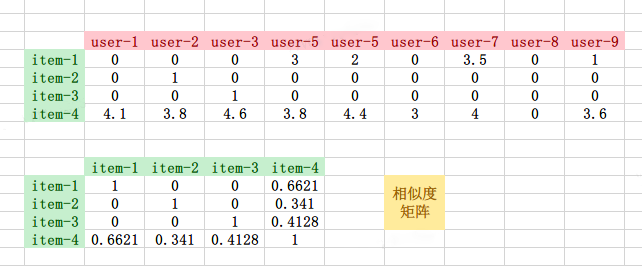
我们从评分矩阵中抽取item1 – item4的向量,并且利用余弦相似度计算它们之间的相似度。
通过相似度矩阵,我们可以看到物品item-1, item-2, item-3的之间的相似度均为0,而且与item-1, item-2, item-3最相似的物品都是item-4,因此在以ItemCF为基础的推荐场景中item-4将会被推荐给用户。
但是,物品item-4与物品item-1, item-2, item-3最相似的原因是item-4是一件热门商品,购买的用户多,而物品item-1, item-2, item-3的相似度均为0的原因仅仅是它们的特征向量非常稀疏,缺乏相似度计算的直接数据。
综上,我们可以看到经典的基于用户/物品的协同过滤算法有天然的缺陷,无法处理稀疏场景。为了解决该问题,矩阵分解被提出。
2.1 显示反馈
我们将用户对物品的评分行为定义为显示反馈。基于显示反馈的矩阵分解是将评分矩阵Rm×n 用两个矩阵 和Yn×k的乘积近似表示,其数学表示如下:
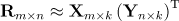
其中, 表示隐性因子,以用户侧来理解, 表示的就是用户的年龄和性别两个属性。此外有个很好的比喻就是物理学的三棱镜,白光在三棱镜的作用下被分解为7种颜色的光,在矩阵分解算法中,分解的作用就类似于”三棱镜”,如下图所示,因此,矩阵分解也被称为隐语义模型。矩阵分解将系统的自由度从 降到了,从而实现了降维的目的。

为了求解矩阵 和Yn×k,需要最小化平方误差损失函数,来尽可能地使得两个矩阵的乘积逼近评分矩阵 ,即
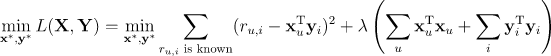
其中, 为惩罚项,λ为惩罚系数/正则化系数,xu表示第u个用户的k维特征向量, 表示第 i 个物品的k维特征向量。
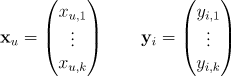
全体用户的特征向量构成了用户矩阵 ,全体物品的特征向量构成了物品矩阵 Yn×k。
我们训练模型的时候,就只需要训练用户矩阵中的m×k个参数和物品矩阵中的n×k个参数。因此,协同过滤就成功转化成了一个优化问题。
2.2 预测评分
通过模型训练 (即求解模型系数的过程),我们得到用户矩阵Xm×k 和物品矩阵 ,全部用户对全部物品的评分预测可以通过 获得。如下图所示。
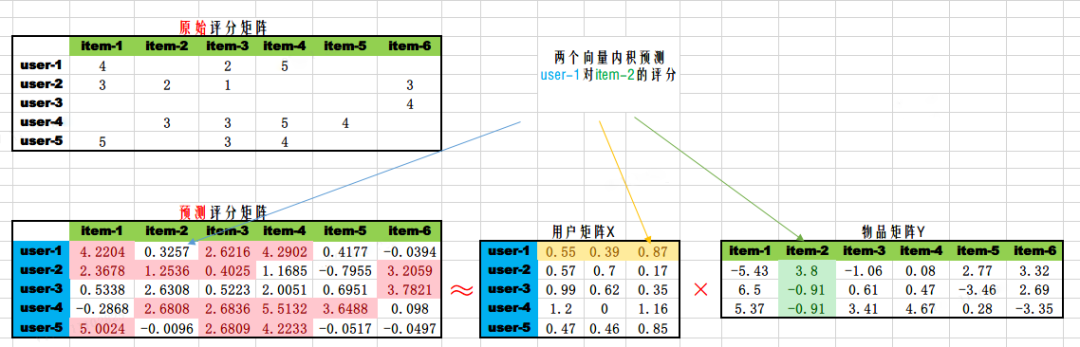
得到全部的评分预测后,我们就可以对每个物品进行择优推荐。需要注意的是,用户矩阵和物品矩阵的乘积,得到的评分预估值,与用户的实际评分不是全等关系,而是近似相等的关系。如上图中两个矩阵粉色部分,用户实际评分和预估评分都是近似的,有一定的误差。
2.3 理论推导
矩阵分解ALS的理论推导网上也有不少,但是很多推导不是那么严谨,在操作向量导数时有的步骤甚至是错误的。有的博主对损失函数的求和项理解解出现错误,例如
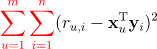
但是评分矩阵是稀疏的,求和并不会贯穿整个用户集和物品集。正确的写法应该是

其中,表示已知的评分项。
我们在本节给出详细的、正确的推导过程,一是当做数学小练习,其次也是对算法有更深层的理解,便于阅读Spark ALS的源码。
将 使用数学语言描述,矩阵分解的损失函数定义如下:
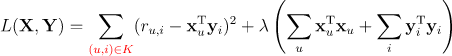
其中 K 为评分矩阵中已知的(u,i) 集合。例如下面的评分矩阵对应的 K为
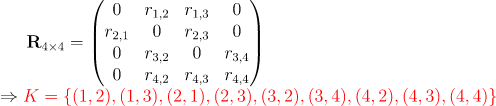
求解上述损失函数存在两种典型的优化方法,分别为
-
交替最小二乘 (Alternating Least Squares, ALS)
-
随机梯度下降 (Stochastic Gradient Descent, SGD)
交替最小二乘,指的是固定其中一个变量,利用最小二乘求解另一个变量,以此交替进行,直至收敛或者到达最大迭代次数,这也是“交替”一词的由来。
随机梯度下降,是优化理论中最常用的一种方式,通过计算梯度,然后更新待求的变量。
在矩阵分解算法中,Spark最终选择了ALS作为官方的唯一实现,原因是ALS很容易实现并行化,任务之间没有依赖。
下面我们动手推导一下整个计算过程,在机器学习理论中,微分的单位一般在向量维度,很少去对向量的分量为偏微分推导。
首先我们固定物品矩阵 Y,将物品矩阵 Y看成常量。不失一般性,我们定义用户u 评分过的物品集合为 ,利用损失函数对向量 求偏导,并且令导数等于0可得:
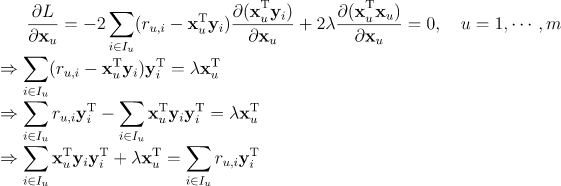
因为向量 与求和符号 无关,所有将其移出求和符号,因为 是矩阵相乘 (不满足交换性),因此 在左边
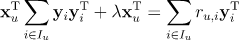
等式两边取转置,我们有
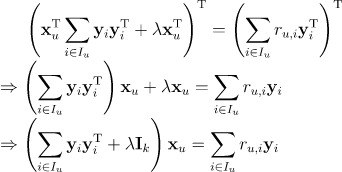
为了化简 与
,我们将 展开。
假设Iu={ic1,⋯,icN} , 其中N表示用户u评分过的物品数量,表示第 个物品对应的索引/序号,借助于 ,我们有

其中,
为以 为行号在物品矩阵 Y 中选取的N个行向量形成的子矩阵
Ru,Iu为以Iu={ic1,⋯icN} 为索引,在评分矩阵 R的第u 行的行向量中选取的N 个元素,形成的子行向量
因此,我们有
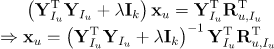
网上的博客,许多博主给出类似下面形式的结论不是很严谨,主要是损失函数的理解不到位导致的。

同理,我们定义物品 i 被评分的用户集合为
根据对称性可得

其中,
为以 为行号在用户矩阵X中选取的M个行向量形成的子矩阵
为以 为索引,在评分矩阵 R的第i列的列向量中选取的 M个元素,形成的子列向量
此外, 为单位矩阵
如果读者感觉上述的推导还是很抽象,我们也给一个具体实例来体会一下中间过程
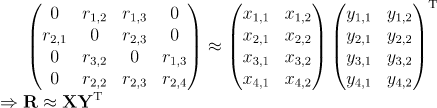
注意到损失函数是一个标量,这里我们只展开涉及到的项,如下所示
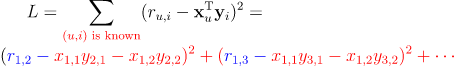
让损失函数对 分别求偏导数可以得到
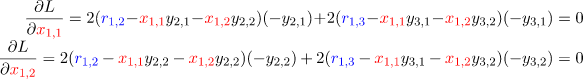
写成矩阵形式可得
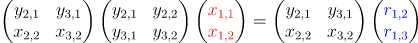
利用我们上述的规则,很容易检验我们导出的结论。
总结来说,ALS的整个算法过程只有两步,涉及2个循环,如下图所示:

算法使用RMSE(root-mean-square error)评估误差。
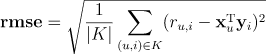
当RMSE值变化很小时或者到达最大迭代步骤时,满足收敛条件,停止迭代。
“Talk is cheap. Show me the code.” 作为小练习,我们给出上述伪代码的Python实现。
import numpy as npfrom scipy.linalg import solve as linear_solve# 评分矩阵 5 x 6R = np.array([[4, 0, 2, 5, 0, 0], [3, 2, 1, 0, 0, 3], [0, 2, 0, 3, 0, 4], [0, 3, 3,5, 4, 0], [5, 0, 3, 4, 0, 0]])m = 5 # 用户数n = 6 # 物品数k = 3 # 隐向量的维度_lambda = 0.01 # 正则化系数# 随机初始化用户矩阵, 物品矩阵X = np.random.rand(m, k)Y = np.random.rand(n, k)# 每个用户打分的物品集合X_idx_dict = {1: [1, 3, 4], 2: [1, 2, 3, 6], 3: [2, 4, 6], 4: [2, 3, 4, 5], 5: [1, 3, 4]}# 每个物品被打分的用户集合Y_idx_dict = {1: [1, 2, 5], 2: [2, 3, 4], 3: [1, 2, 4, 5], 4: [1, 3, 4, 5], 5: [4], 6: [2, 3]}
# 迭代10次for iter in range(10):for u in range(1, m+1):Iu = np.array(X_idx_dict[u])YIu = Y[Iu-1]YIuT = YIu.TRuIu = R[u-1, Iu-1]xu = linear_solve(YIuT.dot(YIu) + _lambda * np.eye(k), YIuT.dot(RuIu))= xufor i in range(1, n+1):Ui = np.array(Y_idx_dict[i])XUi = X[Ui-1]XUiT = XUi.TRiUi = R.T[i-1, Ui-1]yi = linear_solve(XUiT.dot(XUi) + _lambda * np.eye(k), XUiT.dot(RiUi))= yi
最终,我们打印用户矩阵,物品矩阵,预测的评分矩阵如下,可以看到预测的评分矩阵非常逼近原始评分矩阵。
# Xarray([[1.30678487, 2.03300876, 3.70447639],[4.96150381, 1.03500693, 1.62261161],[6.37691007, 2.4290095 , 1.03465981],[0.41680155, 3.31805612, 3.24755801],[1.26803845, 3.57580564, 2.08450113]])# Yarray([[ 0.24891282, 1.07434519, 0.40258993],[ 0.12832662, 0.17923216, 0.72376732],[-0.00149517, 0.77412863, 0.12191856],[ 0.12398438, 0.46163336, 1.05188691],[ 0.07668894, 0.61050204, 0.59753081],[ 0.53437855, 0.20862131, 0.08185176]])# X.dot(Y.T) 预测评分array([[4.00081359, 3.2132548 , 2.02350084, 4.9972158 , 3.55491072, 1.42566466],[3.00018371, 1.99659282, 0.99163666, 2.79974661, 1.98192672, 3.00005934],[4.61343295, 2.00253692, 1.99697545, 3.00029418, 2.59019481, 3.99911584],[4.97591903, 2.99866546, 2.96391664, 4.99946603, 3.99816006, 1.18076534],[4.99647978, 2.31231627, 3.02037696, 4.0005876 , 3.5258348 , 1.59422188]])# 原始评分矩阵array([[4, 0, 2, 5, 0, 0],[3, 2, 1, 0, 0, 3],[0, 2, 0, 3, 0, 4],[0, 3, 3, 5, 4, 0],[5, 0, 3, 4, 0, 0]])
三、Spark ALS应用
Spark的内部实现并不是我们上面所列的算法,但是核心原理是完全一样的,Spark实现的是上述伪代码的分布式版本,具体算法参考Large-scale Parallel Collaborative Filtering for the Netflix Prize。其次,查阅Spark的官方文档,我们也注意到,Spark使用的惩罚函数与我们上文的有细微的差别。
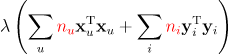
其中 分别表示用户u打分的物品数量和物品 i 被打分的用户数量。即

本小节通过两个案例来了解Spark ALS的具体使用,以及在面对互联网实际工程场景下的应用。
3.1 Demo案例
以第一节给出的数据为例,将三元组(User, Item, Rating)组织为als-demo-data.csv,该demo数据集涉及5个用户和6个物品。
userId,itemId,rating1,1,41,3,21,4,52,1,32,2,22,3,12,6,33,2,23,4,33,6,44,2,34,3,34,4,54,5,45,1,55,3,35,4,4
使用Spark的ALS类使用非常简单,只需将三元组(User, Item, Rating)数据输入模型进行训练。
import org.apache.spark.sql.SparkSessionimport org.apache.spark.ml.recommendation.ALSval spark = SparkSession.builder().appName("als-demo").master("local[*]").getOrCreate()val rating = spark.read.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true")).csv("./data/als-demo-data.csv")// 展示前5条评分记录rating.show(5)val als = new ALS().setMaxIter(10) // 迭代次数,用于最小二乘交替迭代的次数.setRank(3) // 隐向量的维度.setRegParam(0.01) // 惩罚系数.setUserCol("userId") // user_id.setItemCol("itemId") // item_id.setRatingCol("rating") // 评分列val model = als.fit(rating) // 训练模型// 打印用户向量和物品向量model.userFactors.show(truncate = false)model.itemFactors.show(truncate = false)// 给所有用户推荐2个物品model.recommendForAllUsers(2).show()
上述代码在控制台输出结果如下:
+------+------+------+|userId|itemId|rating|+------+------+------+| 1| 1| 4|| 1| 3| 2|| 1| 4| 5|| 2| 1| 3|| 2| 2| 2|+------+------+------+only showing top 5 rows+---+------------------------------------+|id |features |+---+------------------------------------+|1 |[-0.17339179, 1.3144133, 0.04453602]||2 |[-0.3189066, 1.0291641, 0.12700711] ||3 |[-0.6425665, 1.2283803, 0.26179287] ||4 |[0.5160747, 0.81320006, -0.57953185]||5 |[0.645193, 0.26639006, 0.68648624] |+---+------------------------------------++---+-----------------------------------+|id |features |+---+-----------------------------------+|1 |[2.609607, 3.2668495, 3.554771] ||2 |[0.85432494, 2.3137972, -1.1198239]||3 |[3.280517, 1.9563107, 0.51483333] ||4 |[3.7446978, 4.259611, 0.6640027] ||5 |[1.6036265, 2.5602736, -1.8897828] ||6 |[-1.2651576, 2.4723763, 0.51556784]|+---+-----------------------------------++------+--------------------------------+|userId|recommendations |+------+--------------------------------+|1 |[[4, 4.9791617], [1, 3.9998217]]| // 对应物品的序号和预测评分|2 |[[4, 3.273963], [6, 3.0134287]] ||3 |[[6, 3.9849386], [1, 3.2667015]]||4 |[[4, 5.011649], [5, 4.004795]] ||5 |[[1, 4.994258], [4, 4.0065994]] |+------+--------------------------------+
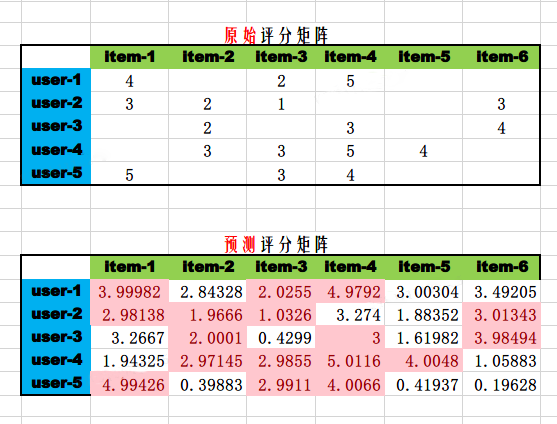
我们使用numpy来验证Spark的结果,并且用Excel可视化评分矩阵。
import numpy as npX = np.array([[-0.17339179, 1.3144133, 0.04453602],[],[],[],[]])Y = np.array([[2.609607, 3.2668495, 3.554771],[],[],[],[],[]])R_predict = X.dot(Y.T)R_predict
输出预测的评分矩阵如下:
array([[3.99982136, 2.84328038, 2.02551472, 4.97916153, 3.0030386, 3.49205357],[2.98138452, 1.96660155, 1.03257371, 3.27396294, 1.88351875, 3.01342882],[3.26670123, 2.0001004 , 0.42992289, 3.00003605, 1.61982132, 3.98493822],[1.94325135, 2.97144913, 2.98550149, 5.011649 , 4.00479503, 1.05883274],[4.99425778, 0.39883335, 2.99113433, 4.00659955, 0.41937014, 0.19627587]])
从Excel可视化的评分矩阵可以观察到预测的评分矩阵非常逼近原始的评分矩阵,以user-3为例,Spark推荐的物品是item-6和item-1, [[6, 3.9849386], [1, 3.2667015]],这和Excel展示的预测评分矩阵完全一致。
从Spark函数recommendForAllUsers()给出的结果来看,Spark内部并没有去除用户已经购买的物品。
3.2 工程应用
在互联网场景,用户数 m(千万~亿级别) 和物品数 n (10万~100万级别) 规模很大,App的埋点数据一般会保存在HDFS中,以互联网的长视频场景为例,用户的埋点信息最终聚合为用户行为表 t_user_behavior。
行为表包含用户的imei,物品的content-id,但是没有直接的用户评分,实践中我们的解决方案是利用用户的其他行为进行加权得出用户对物品的评分。即
rating = w1 * play_time (播放时长) + w2 * finsh_play_cnt (完成的播放次数) + w3 * praise_cnt (点赞次数) + w4 * share_cnt (分享次数) + 其他适合于你业务逻辑的指标
其中, wi为每个指标对应的权重。

如下的代码块演示了工程实践中对大规模用户和商品场景进行推荐的流程。
import org.apache.spark.ml.feature.{IndexToString, StringIndexer}// 从hive加载数据,并利用权重公式计算用户对物品的评分val rating_df = spark.sql("select imei, content_id, 权重公式计算评分 as rating from t_user_behavior group by imei, content_id")// 将imei和content_id转换为序号,Spark ALS入参要求userId, itemId为整数// 使用org.apache.spark.ml.feature.StringIndexerval imeiIndexer = new StringIndexer().setInputCol("imei").setOutputCol("userId").fit(rating_df)val contentIndexer = new StringIndexer().setInputCol("content_id").setOutputCol("itemId").fit(rating_df)val ratings = contentIndexer.transform(imeiIndexer.transform(rating_df))// 其他code,类似于上述demoval model = als.fit(ratings)// 给每个用户推荐100个物品val _userRecs = model.recommendForAllUsers(100)// 将userId, itemId转换为原来的imei和content_idval imeiConverter = new IndexToString().setInputCol("userId").setOutputCol("imei").setLabels(imeiIndexer.labels)val contentConverter = new IndexToString().setInputCol("itemId").setOutputCol("content_id").setLabels(contentIndexer.labels)val userRecs = imeiConverter.transform(_userRecs)// 离线保存供线上调用userRecs.foreachPartition {// contentConverter 将itemId转换为content_id// 保存redis逻辑}
值得注意的是,上述的工程场景还有一种解决方案,即隐式反馈。用户给商品评分很单一,在实际的场景中,用户未必会给物品打分,但是大量的用户行为,同样能够间接反映用户的喜好,比如用户的购买记录、搜索关键字,加入购物车,单曲循环播放同一首歌。我们将这些间接用户行为称之为隐式反馈,以区别于评分对应的显式反馈。胡一凡等人在论文Collaborative filtering for implicit feedback datasets中针对隐式反馈场景提出了ALS-WR模型 (ALS with Weighted-λ-Regularization),并且Spark官方也实现了该模型,我们将在以后的文章中介绍该模型。
四、总结
本文从推荐的场景出发,引出了协同过滤这一经典的推荐算法,并且由此讲解了被Spark唯一实现和维护的矩阵分解算法,详细推导了显示反馈下矩阵分解的理论原理,并且给出了Python版本的单机实现,能够让读者更好的理解矩阵这一算法,最后我们以demo和工程实践两个实例讲解了Spark ALS的使用,能够让没有接触过推荐算法的同学有个直观的理解,用理论与实践的形式明白矩阵分解这一推荐算法背后的原理。
参考文献:
-
王喆, 深度学习推荐系统
-
Hu, Yifan, Yehuda Koren, and Chris Volinsky. “Collaborative filtering for implicit feedback datasets.” 2008 Eighth IEEE International Conference on Data Mining. IEEE, 2008.
-
Zhou, Yunhong, et al. “Large-scale parallel collaborative filtering for the Netflix prize.” International conference on algorithmic applications in management. Springer, Berlin, Heidelberg, 2008.
本文转载自Tang Shutao vivo互联网技术,原文链接:https://mp.weixin.qq.com/s/PQol3h0KmqmElYRJ1Pu2Mw。