
作者:唐辉
在日常使用中,我们可以发现在hive元数据库中的TBL_COL_PRIVS,TBL_PRIVS 、PART_COL_STATS表相当大,部分特殊情况下NOTIFICATION_LOG也可能存在问题,如果集群中有关联的操作时会导致元数据库响应慢,从而影响整个Hive的性能,本文的主要目的通过对Hive 的元数据库部分表进行优化,来保障整个Hive 元数据库性能的稳定性。
-
测试环境
1.CDP7.1.6 、启用Kerberos
2.元数据版本 MariaDB-5.5.60
如下图,某生产环境4张表的大小,其中PART_COL_STATS 表超过2000W,TBL_COL_PRIVS 表大小超过3亿,因此存在部分hive 元数据操作性能问题,如表的rename操作慢甚至超时,大批量hive 数据表操作时Hive Metastore Canary时间很长
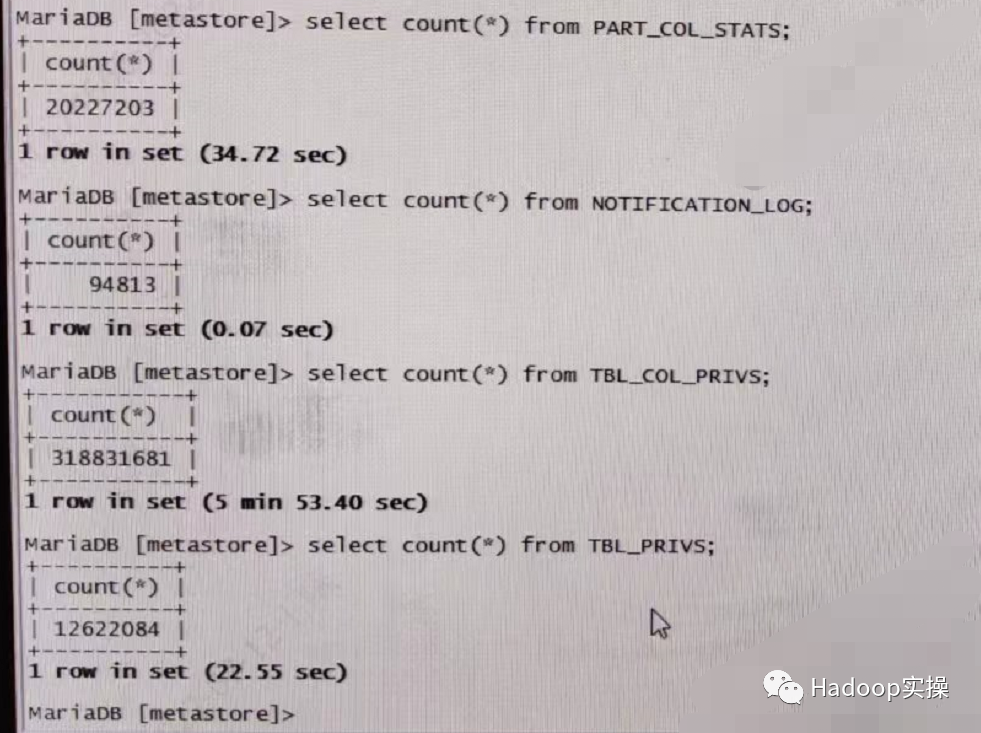

2.1.TBL_COL_PRIVS,TBL_PRIVS表数据量过大
TBL_COL_PRIVS,TBL_PRIVS 表过大,它用于记录了每张表每列每个权限信息,从而允许用户直接通过SQL来查询权限信息,当集群中的表数量和权限数量过多时会影响性能,除非表或者权限被清理则会删除这两个表关联的数据,否则这两个表可能会无限制增长。
具体验证如下:
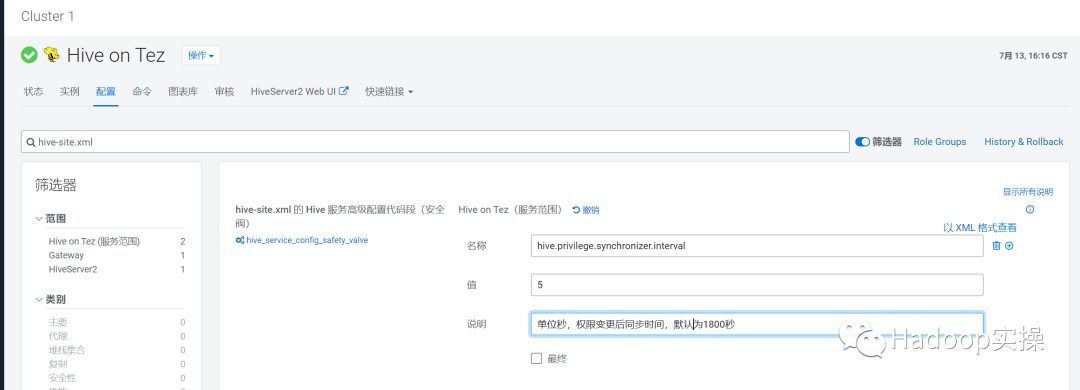
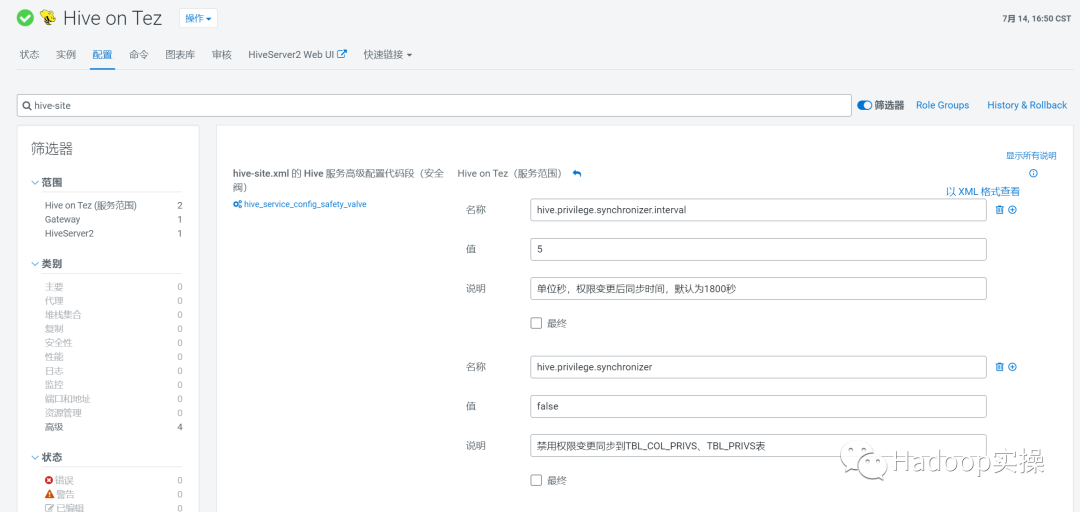
为了快速验证,我们将权限修改后的同步时间修改短一些。通过参数hive.privilege.synchronizer.interval 可以权限变更后的同步间隔时间参数,默认为1800秒,为了快速验证修改为5秒。配置如下
每当我们有表的新建或者表结构变动时以及修改权限都会操作TBL_COL_PRIVS进行变动。如下当我新增一个表时,他的每列每个用户每个权限都会有一条记录,因此这个表会相当的庞大:
--beeline 中执行创建表--
create table testpriv (c1 string ,c2 string);
---元数据库中查看表的TBL_ID,然后关联查询TBL_COL_PRIVS,TBL_PRIVS 对于该表生成的数据条数---
select * from TBLS where TBL_NAME='testpriv';
select count(*) from TBL_COL_PRIVS where TBL_ID='12625';
select count(*) from TBL_PRIVS where TBL_ID='12625';

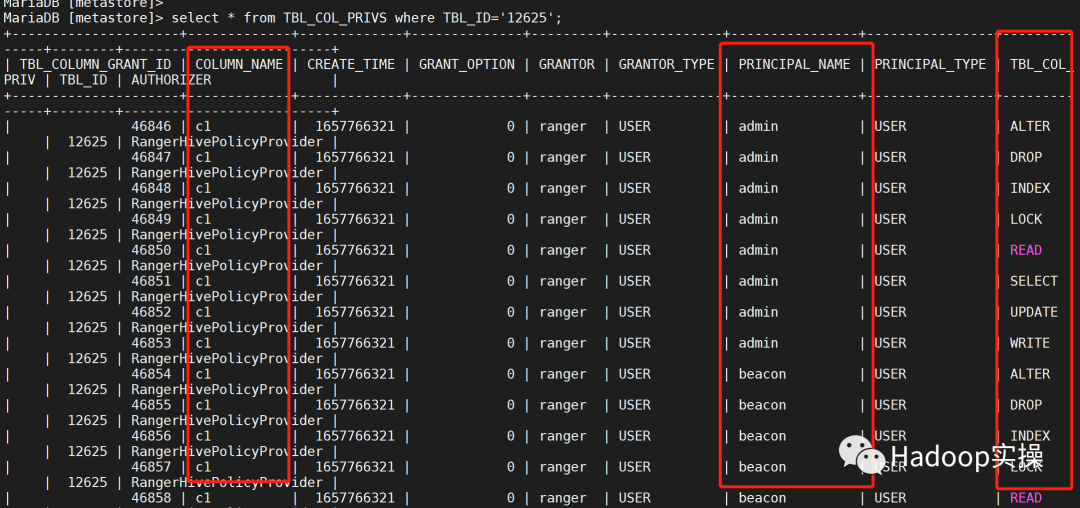
可以查看到TBL_PRIVS中是该表对应的每个用户每个权限一条记录,CDP7.1.6中Ranger默认的All 权限(包括ALTER ,DROP 等)也在内。
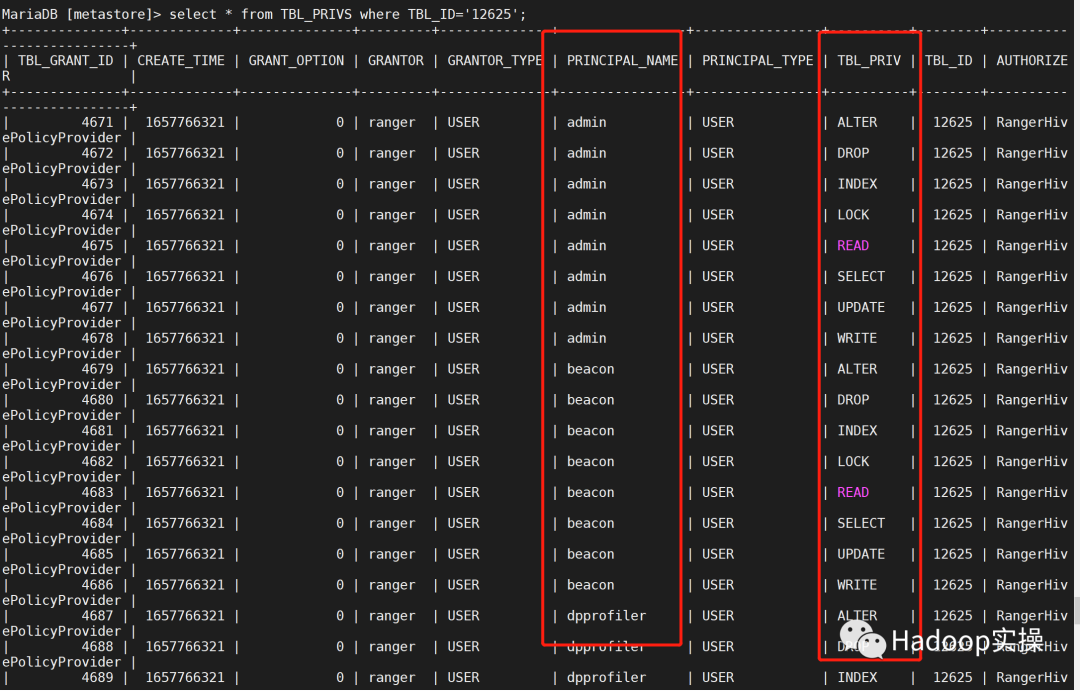
TBL_COL_PRIVS该表中的每个列对应的每个用户每个权限一条记录,所以当表或者列以及用户权限策略多时,该表的数据会成倍的增加。
也可以通过给某个用户添加该表的权限来验证:
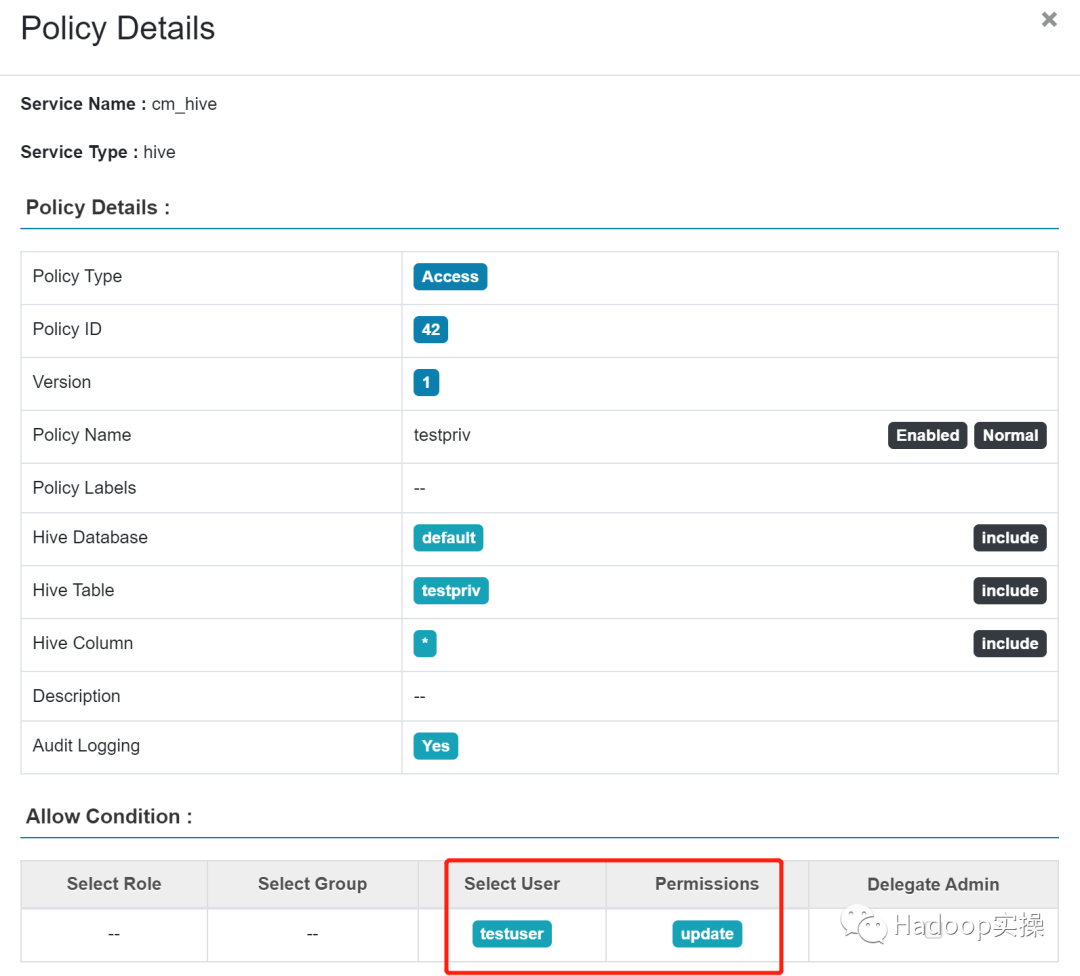
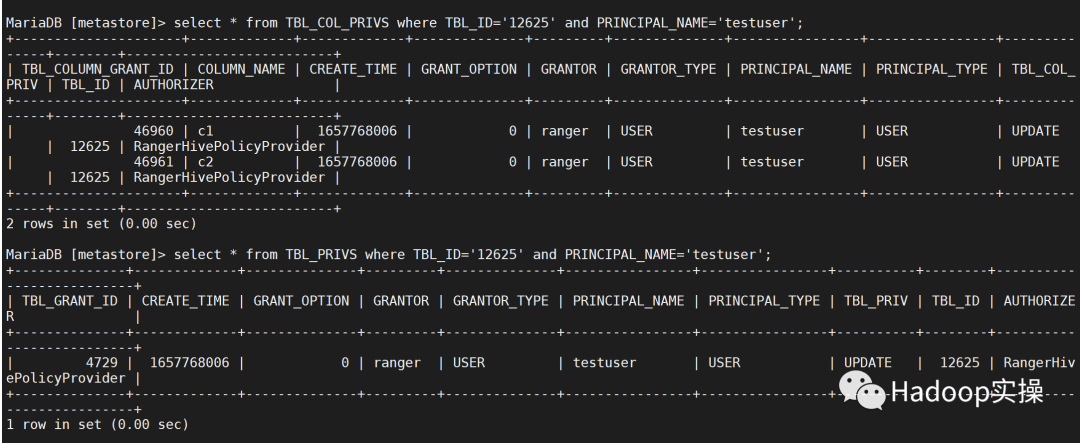
在Ranger Admin WebUI 中给testuser 添加 testpriv 的update 权限,然后查看TBL_COL_PRIVS和TBL_PRIVS 表验证如下:
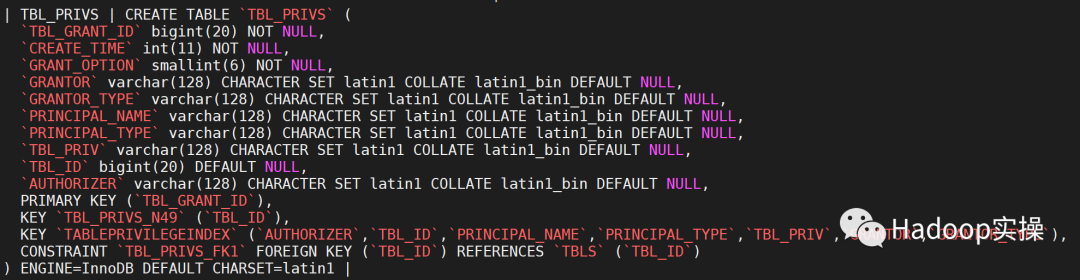
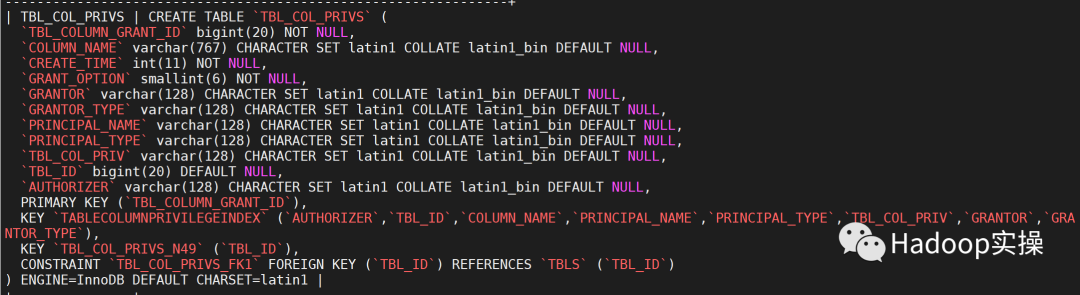
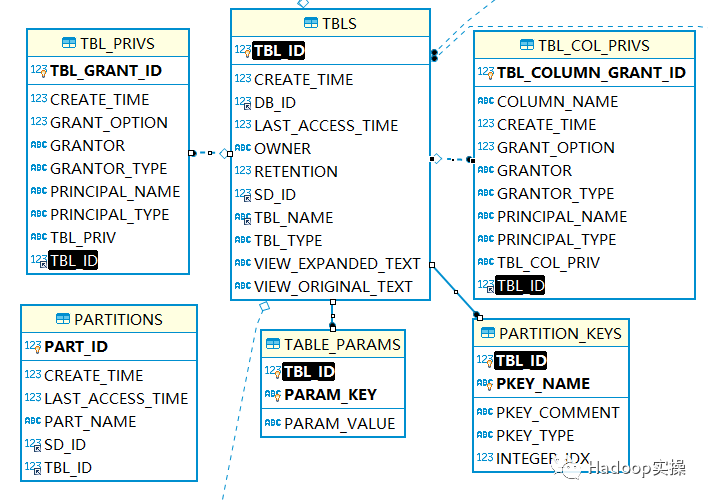
下图是TBL_COL_PRIVS,TBL_PRIVS表结构以及关系信息,相比开源的Hive 中,CDP7.1.6 的这两个表中多了AUTHORIZER 字段,它的值通常是
RangerHivePolicyProvider,用于标记生成的权限是来自Ranger中Hive 权限策略
2.2 PART_COL_STATS 表数据量过大
在每个Hive分区表都有写入数据的情况下,通常来说这个表的数据量约为 库*表*分区数*列 。并且每当有分区更新时会写该表或者Hive 启用CBO时会查询该表,如果该表数据量过大,可能会出现超时问题
测试如下:每当有新建表写入数据或者新建分区写入数据以及列改动时都会写入数据到该表
--hive中执行--
create table testpar (s1 string ,s2 string ) partitioned by (dat string);
insert into testpar values ("aaa","0101","2022-06-22");
insert into testpar values ("bbb","0102","2022-06-23");
create table testpar2 (p1 string ,p2 string ) partitioned by (pdat string);
insert into testpar2 values ("bbb","0103","2022-06-22");
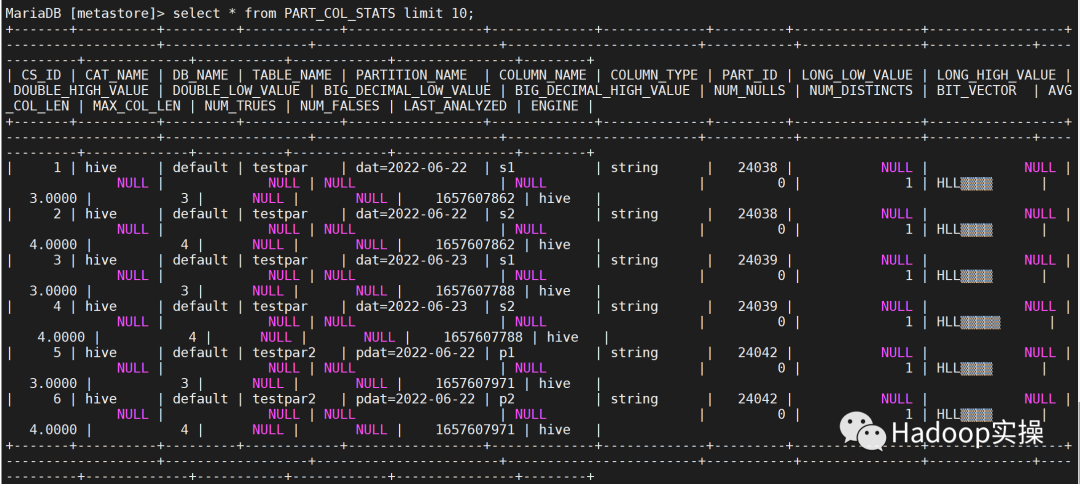
--元数据库中执行--
select * from metastore.PART_COL_STATS limit 10;
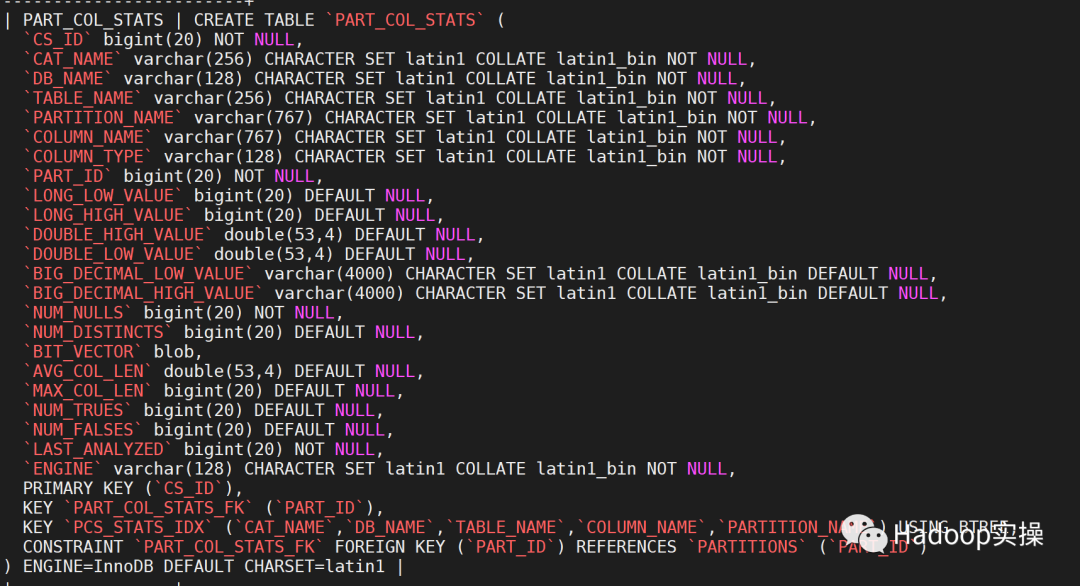
PART_COL_STATS 表结构如下:
2.3 NOTIFICATION_LOG 未及时清理
如果在测试环境没有操作的情况下查看该表默认可以看到很多最近该表的记录中有很多关于cloudera_manager_metastore_canary_test_catalog_hive_hivemetastore_xxxx 的操作,这是CM Hive Metastore 操作是否成功的运行状况检查,也就是Hive Metastore Canary 运行状况检查。默认为每5分钟进行一次测试库、表、分区的创建和删除操作,并记录耗时用于Hive Metastore性能检查。如下图表所示,该时间越长表明Hive Metastore 的性能越糟糕。
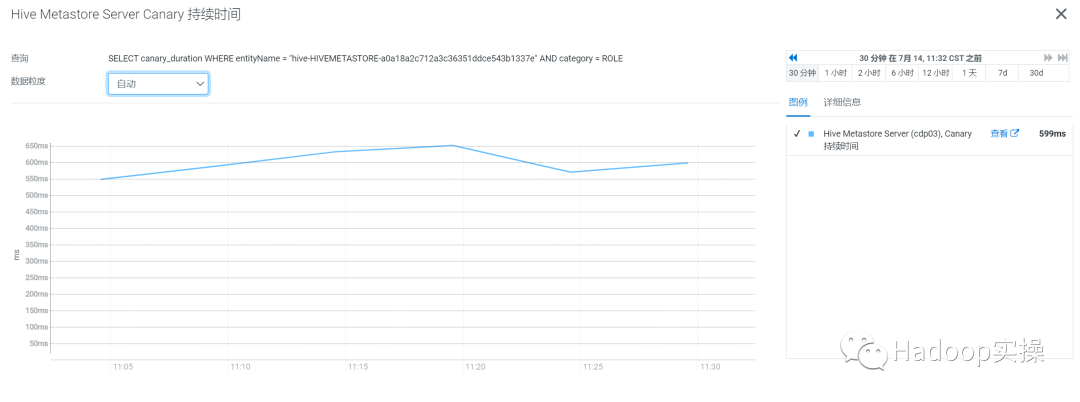
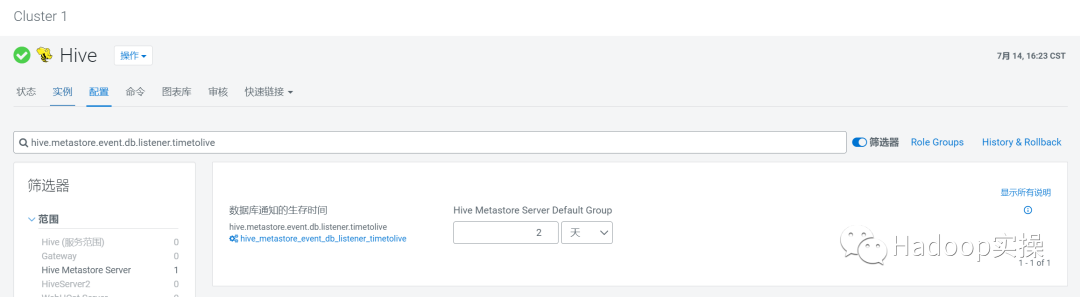
默认情况下NOTIFICATION_LOG 表中保存的数据为2天,具体控制参数如下:
hive.metastore.event.db.listener.timetolive:2 (单位天)
用于从数据库侦听器队列进行数据清理,每次运行间隔时间操作参数如下:
hive.metastore.event.db.listener.clean.interval:7200 (单位秒)
验证数据写入如下,凡是表、分区的变动都会记录在该表中,impala 的Catalog元数据自动刷新功能也是从该表中读取数据来进行元数据的更新操作:
--beeline中执行--
create testnotification (n1 string ,n2 string) partitioned by (ndate sting);
insert into testnotification values ("bbb","0102","2022-06-23");
--hive 元数据中执行—
select count(*) from NOTIFICATION_LOG where TBL_NAME='testnotification';
select * from NOTIFICATION_LOG where TBL_NAME='testnotification' order by EVENT_TIME asc limit 20;
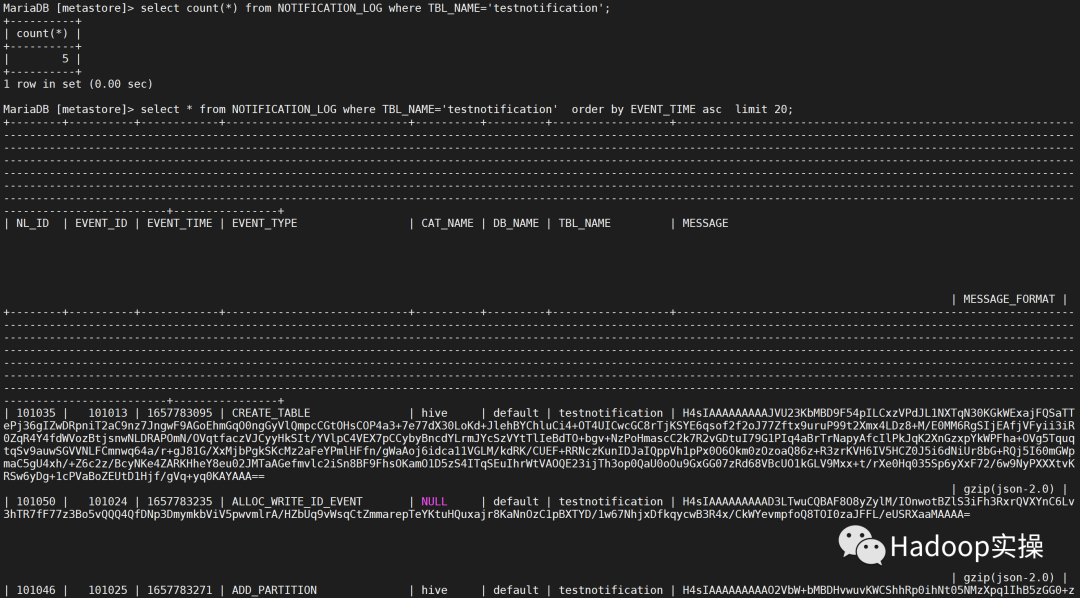
NOTIFICATION_LOG 表结构如下:
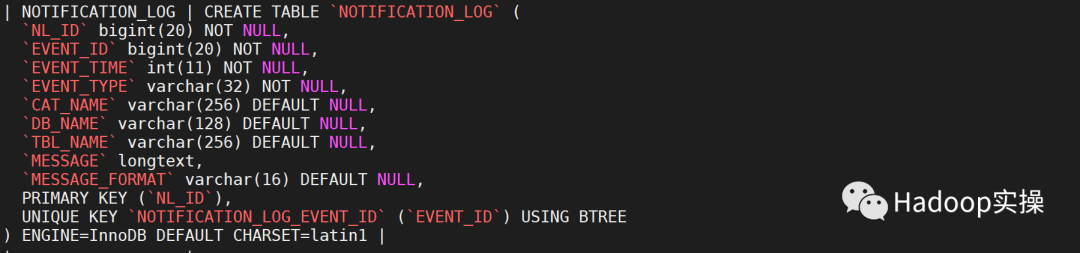
3.1 禁用权限同步至TBL_COL_PRIVS,TBL_PRIVS
hive.privilege.synchronizer 参数在CDP7.1.6中为true,即每当有权限变动或者表结构时,PrivilegeSynchronizer 将获取 Hive 表上的所有 Ranger 权限并将它们插入到 Hive 后端表TBL_COL_PRIVS以及TBL_PRIVS中(默认同步间隔半小时),这是一项新功能,允许用户通过 SQL 检查 Hive 权限。
设置hive.privilege.synchronizer=false,hive.privilege.synchronizer.interval 参数会失效。它的影响是无法使用beeline较为方便的查询到table/column的权限信息。
配置如下,重启Hiveserver2 并更新配置生效:
注意:如果元数据库中这两个表已经非常大了对性能有影响了,建议做好备份后进行truncate TBL_COL_PRIVS 以及TBL_PRIVS 两个表
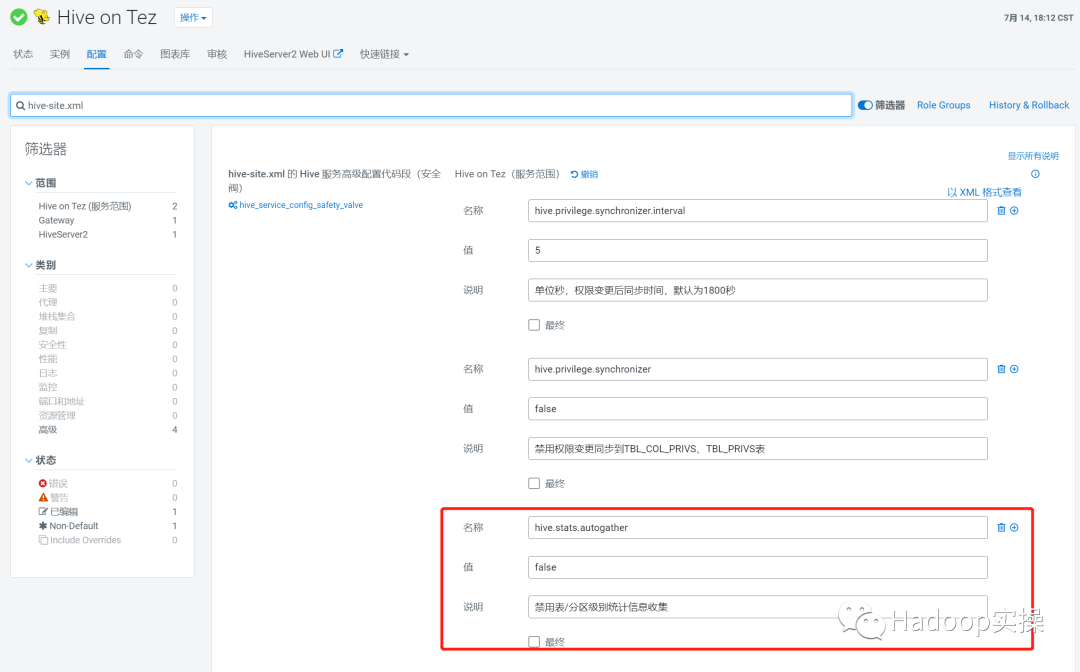
3.2 PART_COL_STATS按需统计
如果你的Hive 中不需要启用CBO进行查询优化,那么可以设置如下参数进行禁用:
hive.stats.autogather:false (默认 true ,开启/禁用表、分区级别统计信息收集)
注意:如果PART_COL_STATS表对你当前的集群性能有影响较大了,建议做好备份后进行truncate PART_COL_STATS 。但是这可能会对CBO优化器选择优化方案造成一定影响,后续依然可以通过执行ANALYSE TABLE或者开启autogather在执行INSERT OVERWRITE操作时自动收集表的统计信息。
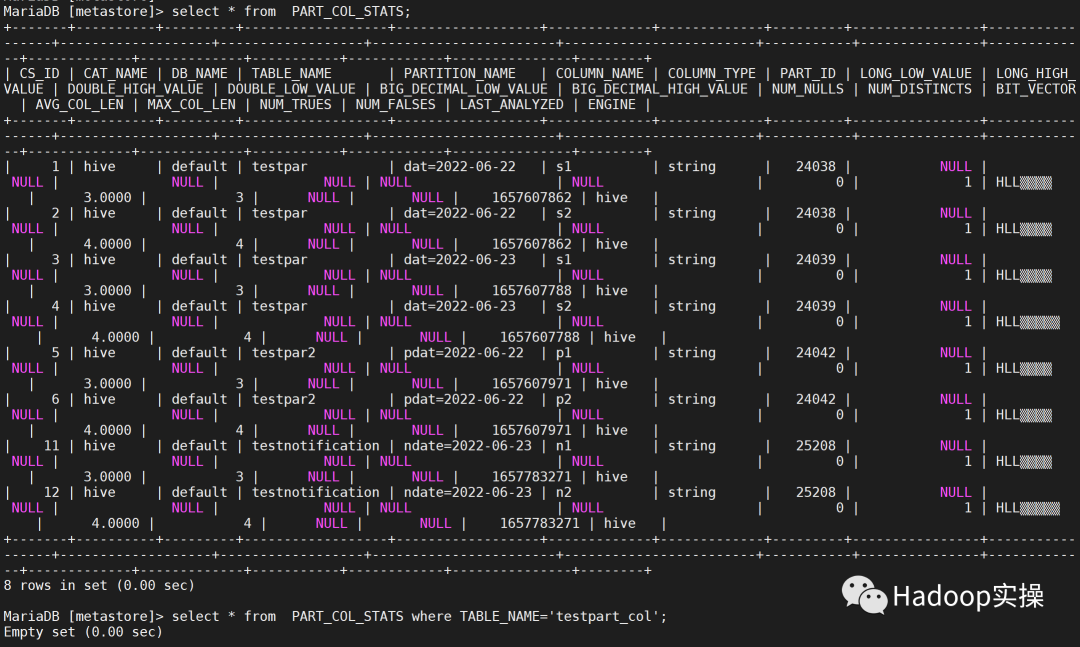
验证如下:
进行表创建以及分区数据写入,PART_COL_STATS不再更新

重新set hive.stats.autogather=true; 后恢复
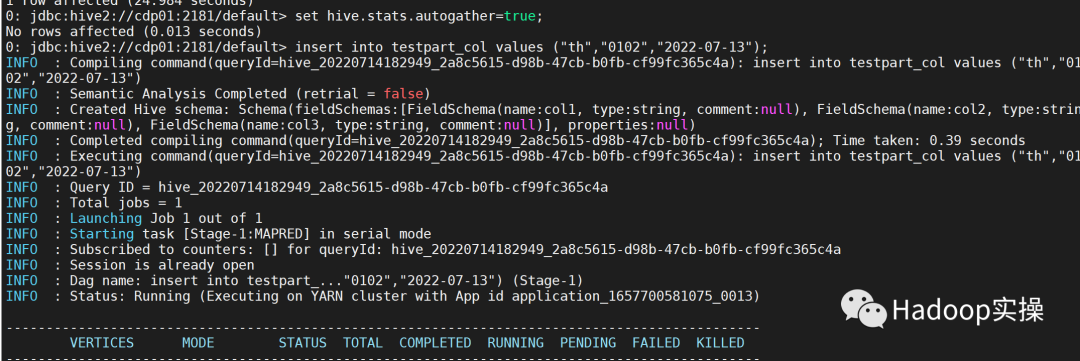
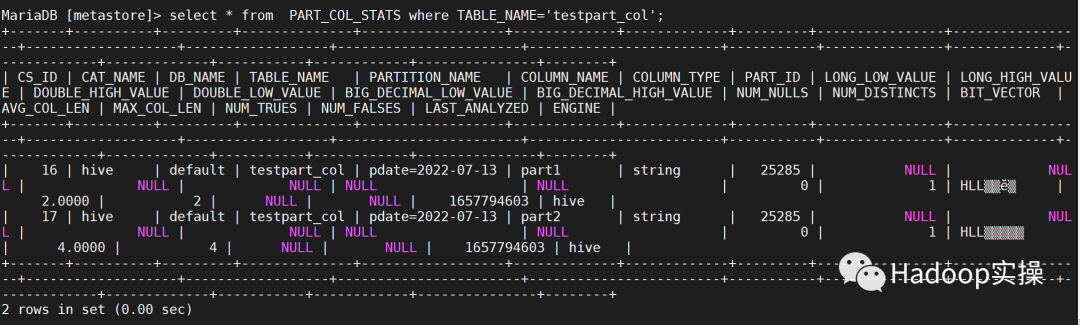
3.3 调整notifcation 清理周期
如果NOTIFICATION_LOG 表的最早的EVENT_TIME 时间已经超过了2天+ 默认2个小时间隔时间,那么说明期间的元数据变更事件太多自动清理程序处理不过来导致,如果集群一直比较繁忙,这个数值会累积到很高的情况。该情况下建议手动进行delete 数据操作,详细可以查看文末参考文档[8]。
如果不需要impala 的自动更新元数据操作可以禁用notification,取消勾选并保存重启生效即可
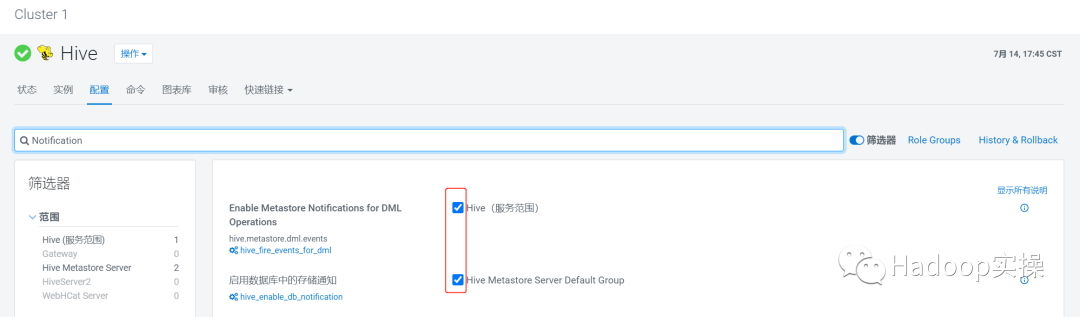
Disable Hive Metastore Canary (Optional) 如果不需要Canary监控信息,可以禁用该选项,可以减少很多事件的产生。
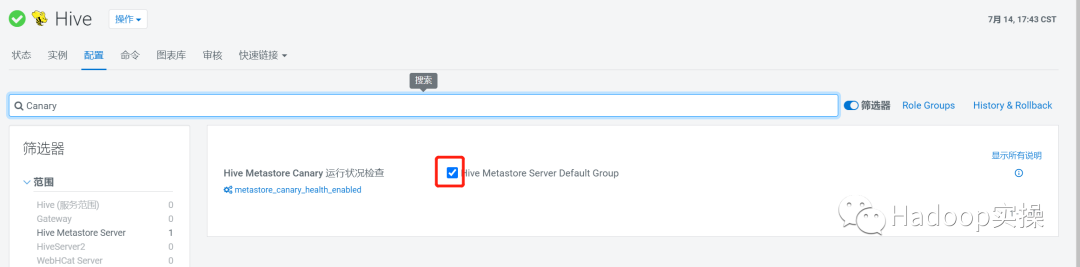
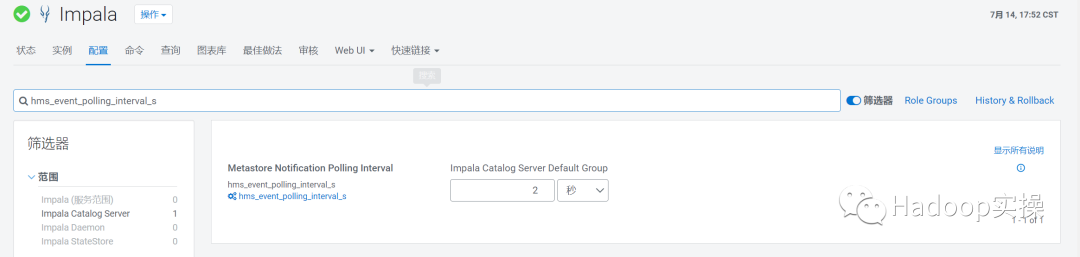
如果有使用impala 的元数据自动更新操作,可以通过调整impala 自动更新元数据的周期减少对NOTIFICATION_LOG表的查询频率来达到调优的目的,代价是impala元数据更新周期会变长。
hms_event_polling_interval_s: 30 (单位:秒,默认2秒,impala元数据更新周期)
也建议通过如下参数进行调优:
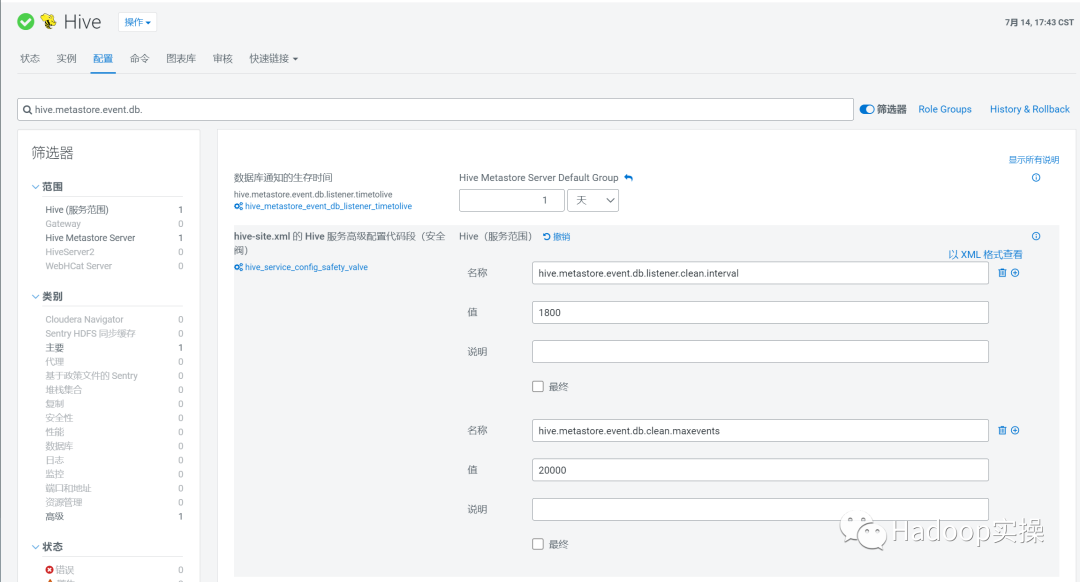
hive.metastore.event.db.listener.timetolive: 1 (单位:天,事件生存周期,默认2天)
hive.metastore.event.db.listener.clean.interval: 1800(单位:秒,事件清理间隔周期,默认7200秒)
hive.metastore.event.db.clean.maxevents : 20000 (默认10000,周期清理最大事件数)
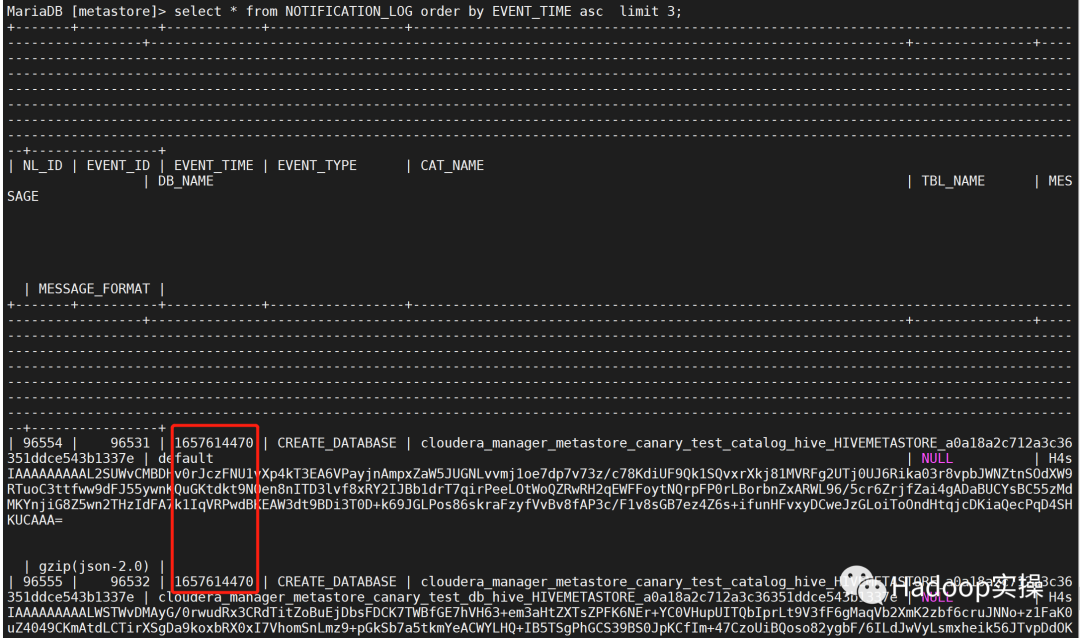
调整前的保留时间为7.12日的数据:
date –date=’@1657614470′ 转化Tue Jul 12 16:27:50 CST 2022
修改配置重启自动后,保留最早的时间只有7.13号的:
date –date=’@1657705168′ Wed Jul 13 17:39:28 CST 2022
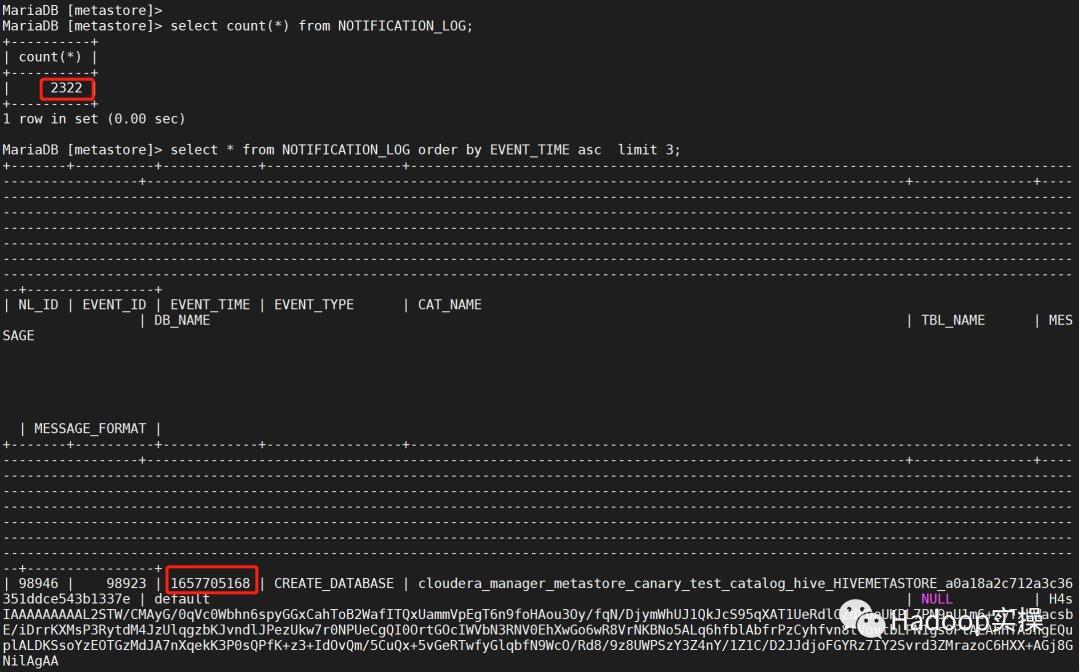
通过对如上的元数据表进行调优后,基本可以避免元数据库的性能而导致的问题
TBL_COL_PRIVS,TBL_PRIVS 相关:
[] https://cwiki.apache.org/confluence/display/Hive/AuthDev[] https://my.cloudera.com/knowledge/Hive-Metastore-database-table-TBLCOLPRIVS-grows-exponentially?id=281222[] https://my.cloudera.com/knowledge/Hive-PrivilegeSynchroniser-can-impact-Hive-metastore-RDBMS?id=328065[] https://my.cloudera.com/knowledge/How-to-change-the-value-of-hiveprivilegesynchronizer-and?id=333414
PART_COL_STATS 相关:
[] https://cwiki.apache.org/confluence/display/hive/statsdev[] https://cwiki.apache.org/confluence/display/Hive/Column+Statistics+in+Hive
NOTIFICATIONLOG 相关:
[] https://my.cloudera.com/knowledge/How-to-speed-up-the-cleanup-process-for-Hive-NOTIFICATIONLOG?id=310681[] https://my.cloudera.com/knowledge/Cleaning-NOTIFICATIONLOG-table-in-CDP?id=332678[] https://cwiki.apache.org/confluence/display/Hive/Replication[] https://cwiki.apache.org/confluence/display/Hive/HCatalog+Notification
本文为从大数据到人工智能博主「bajiebajie2333」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/9108/