摘 要 : 本⽂由社区志愿者邹志业整理,内容来源⾃阿里云实时计算产品经理李佳林(风元)在 7 月 5 日 Flink 峰会(CSDN 云原生系列 )的演讲。主要内容包括:
基于 Flink 构建风控系统
阿里风控实战
大规模风控技术难点
阿里云 FY23 风控演进计划
目前 Flink 基本服务于集团的所有 BU ,在双十一峰值的计算能力达到 40 亿条每秒,计算任务达到了 3 万多个,总共使用 100 万+ Core ;几乎涵盖了集团内的所有具体业务,比如:数据中台、AI 中台、风控中台、实时运维、搜索推荐等。
风控是一个很大的话题,涉及到规则引擎、NoSQL DB、CEP 等等,本章主要讲一些风控的基本概念。在大数据侧,我们把风控划分成 3 × 2 的关系:
2 代表风控要么是基于规则的,要么是基于算法或模型的;
3 代表包括三种风控类型:事先风控、事中风控和事后风控。
1.1 三种风控业务
对于事中风控和事后风控来讲,端上的感知是异步的,对于事先风控来讲,端上的感知是同步的。
对于事先风控这里稍做一些解释,事先风控是把已经训练好的模型或者把已经计算好的数据存在 Redis 、MongoDB 等数据库中;
整体来讲这两种方式的时延都在 200 毫秒左右,可以作为一个同步的 RPC 或 HTTP 请求。 对于 Flink 相关的大数据场景是一个异步的风控请求,它的异步时效性非常低,通常是一秒或者两秒。如果追求超低时延,则可以认为它是一种事中的风控,风控决策过程可以由机器介入处理。 很常见的一种类型是用 Flink SQL 做指标阈值的统计、用 Flink CEP 做行为序列规则分析,还有一种是用 Tensorflow on Flink ,在 Tensorflow 中进行算法描述,然后用 Flink 来执行 Tensorflow 规则的计算。 1.2 Flink 是规则风控最佳选择 目前 Flink 是阿里集团内的风控最佳选择,主要有三个原因:
1.3 规则风控三要素 在规则风控里面有三个要素,后面讲的所有内容都是围绕这三者展开的:
事实 Facts: 是指风控事件,可能来自业务方或者日志埋点,是整个风控系统的输入;
规则 Rules: 往往是由业务侧来定义,即这个规则要满足什么样的业务目标;
阈值 Threshold: 规则所对应描述的严重程度。
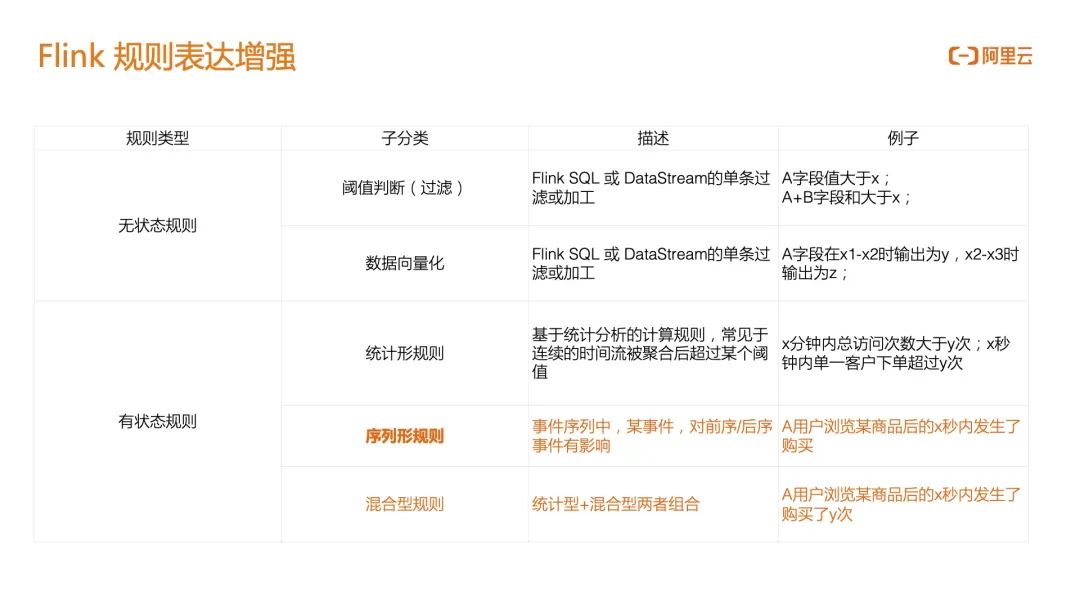
1.4 Flink 规则表达增强 对于 Flink 来说,可以分成无状态规则和有状态规则两类,其中有状态规则是 Flink 风控的核心:
无状态规则: 主要是做数据的 ETL,一种场景是当某个事件的一个字值段大于 X 就触发当前的风控行为;另一种场景是 Flink 任务的下游是一个基于模型或算法的风控,在 Flink 侧不需要做规则判断,只是把数据向量化、归一化,例如多流关联、Case When 判断等把数据变成 0/1 的向量,然后推送到下游的 TensorFlow 做预测。
统计型规则: 基于统计分析的计算规则,比如 5 分钟以内访问次数大于 100 次,则认为触发了风控;
序列型规则: 事件序列中,某事件对前序后序事件有影响,比如点击、加入购物车、删掉三个事件,这种连续的行为序列是一个特殊行为,可能认为这个行为在恶意降低商家商品的评价分数,但这三个事件独立来看并不是一个风控事件;阿里云实时计算 Flink 完善了基于序列的规则能力,为云上和集团内的电商交易场景提供技术护航;
本章主要介绍阿里在工程上是如何满足上面提到的风控三要素。
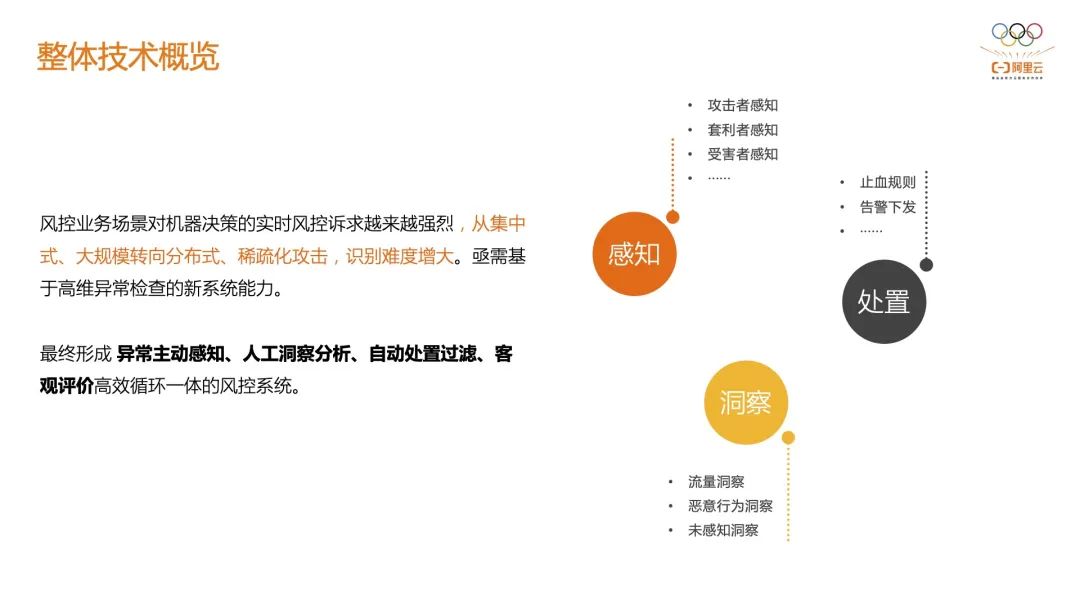
从整体的技术来看,目前分成感知、处置和洞察三个模块:
感知: 目的是感知所有的异常以及提前发现问题,比如捕捉一些与常见数据分布不同的数据类型,并输出这种异常的列表;又比如说某年因为骑行政策的调整头盔销售量升高,连带着就会出现相关产品的点击率、转化率上升,这种情况需要及时被感知捕捉到,因为它是一个正常的行为而非作弊;
处置: 即如何做规则的执行,现在有小时、实时、离线三道防线,相比于之前单条策略的匹配,关联和集成之后的准确性会更高,比如就关联最近一段时间内某些用户的持续行为来进行综合研判;
洞察: 为了发现一些当前没有感知,同时也没有办法直接用规则描述的风控行为,比如风控需要对样本进行高度抽象来进行表示,要先投影到合适的子空间,然后再结合时间维度在高维里面发现一些特征来做新异常的识别。
2.1 阶段一:SQL 实时关联 & 实时统计 在这个阶段有一个基于 SQL 评价风控系统,用简单的 SQL 做一些实时的关联、统计,比如用 SQL 进行聚合操作 SUM(amount) > 50 ,其中规则就是 SUM(amount),规则对应的阈值是 50;假设现在有 10、20、50、100 这 4 种规则同时在线上运行,因为单Flink SQL作业只能执行一种规则,那么就需要为这4个阈值分别申请 4 个 Flink Job。优点是开发逻辑简单,作业隔离性高,但缺点是极大浪费计算资源。
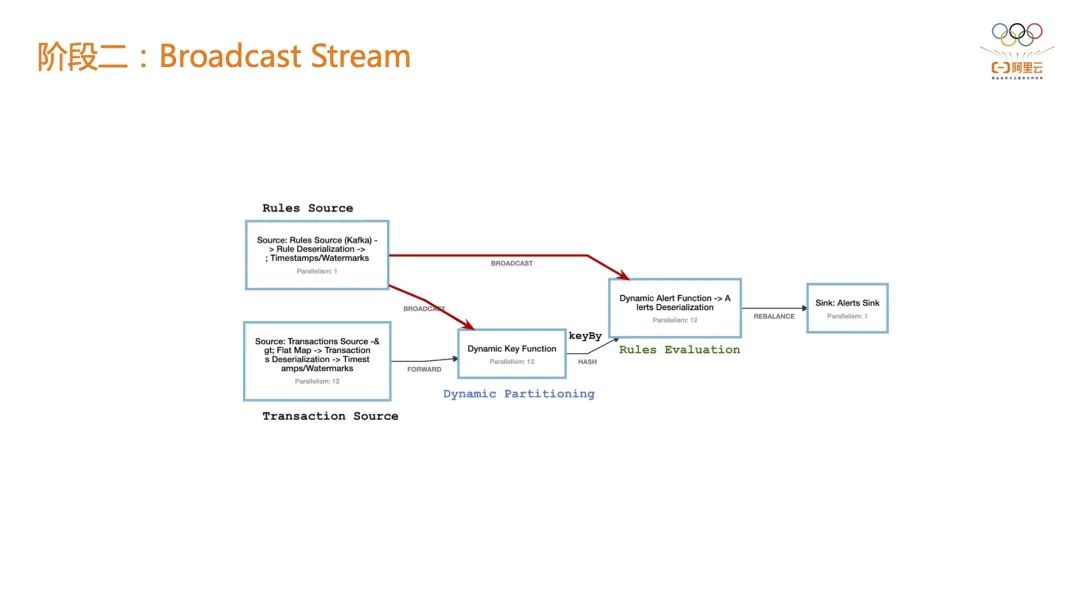
2.2 阶段二:Broadcast Stream 阶段一的风控规则主要问题是规则和阈值不可变,在 Flink 社区目前会有一些解决方案,比如基于 BroadcastStream 来实现,在下面的图中 Transaction Source 负责事件的接入,Rule Source 则是一个BroadcastStream,当有新的阈值时可以通过 BroadcastStream 广播到各个算子。
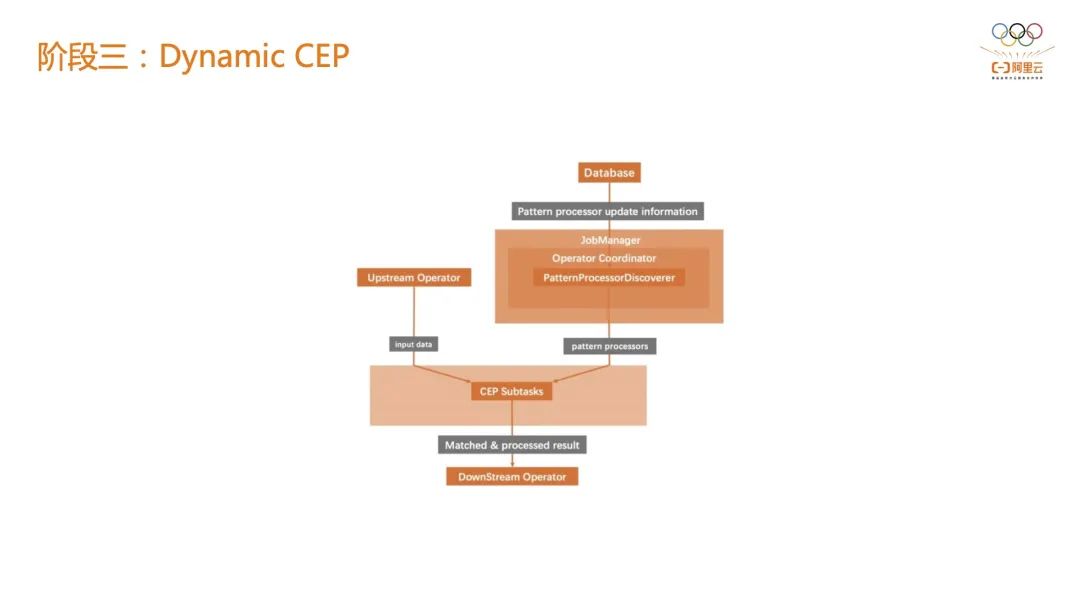
举个例子,判断在一分钟以内连续访问超过 10 次的风控对象,但是在 618 或双 11 可能要把它变成 20 或 30 次,才会被风控系统下游的在线系统感知到。 如果在第一阶段的话,只有两种选择:第一种是所有的作业全量在线上跑;第二种是在某一刻停止掉一个Flink作业,新拉起一个基于新指标的作业。 如果是基于 BroadcastStream 就可以实现规则指标阈值的下发,直接修改线上指标阈值而不需要作业重启。 2.3 阶段三:Dynamic CEP 阶段二的主要问题是只能做到指标阈值的更新,虽然它极大的方便了个业务系统,但实际上很难满足上层业务。诉求主要有两个:结合 CEP 以实现行为序列的感知;结合 CEP 后依然能做到动态修改阈值甚至是规则本身。 阶段三,阿里云 Flink 做了 CEP 相关的高度抽象,解耦了 CEP 规则和 CEP 执行节点,也就是说规则可以存在 RDS、Hologres 等外部第三方存储里,CEP 作业发布上去之后,就可以加载数据库中的 CEP 规则来做到动态替换,因此作业的表达能力会增强。 其次是作业的灵活性会增强,比如想看到某一个 APP 下面的一些行为并对这个行为的指标阈值做更新,可以通过第三方存储更新 CEP 规则而非 Flink 本身。 这样做还有一个优势是可以把规则给暴露给上层业务方,来让业务真真正正的撰写风控规则,我们成为一个真正的规则中台,这就是动态 CEP 能力所带来的好处。在阿里云的服务中,动态 CEP 能力已经被集成在最新版本中,阿里云全托管 Flink 服务极大的简化了风控场景的开发周期。
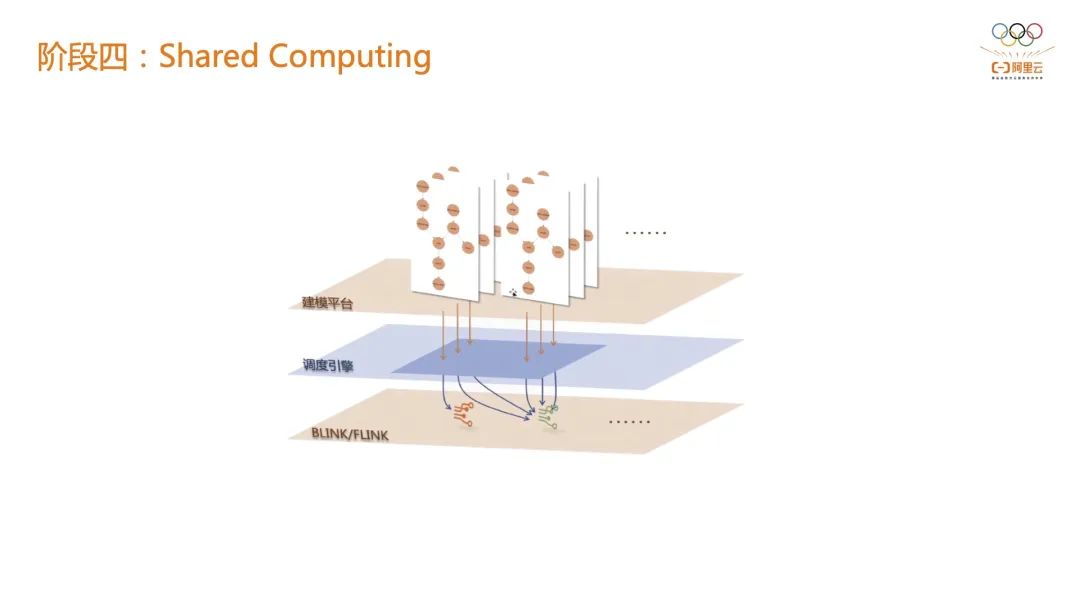
2.4 阶段四:Shared Computing 在阶段三的基础上再往前一步,阿里云实践出 “共享计算” 的解决方案。这套共享计算的方案中,CEP 规则完全可以被建模平台来描述,暴露给上层客户或业务方一个非常友好的规则描述平台,可以通过类似拖拉拽或者其他的方式进行耦合,然后在调度引擎上选择事件接入源来运行规则。比如现在两个建模都是服务于淘宝 APP,完全可以落到同一个 Fact 的 Flink CEP 作业上,这样就可以把业务方、执行层和引擎层完全解耦。当前阿里云共享计算的解决方案已经非常成熟,有丰富的客户落地实践。
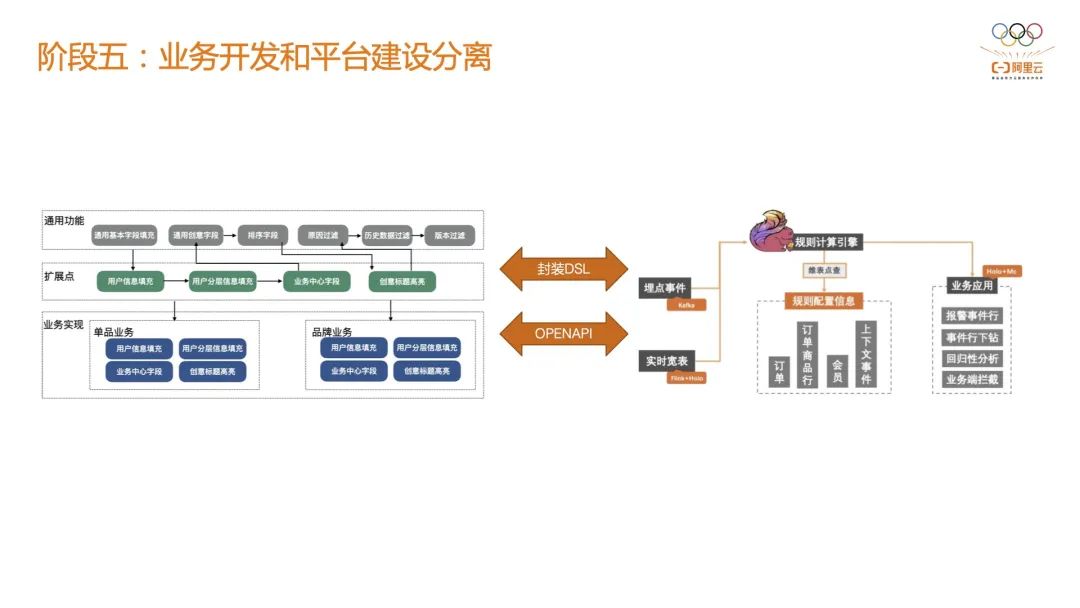
2.5 阶段五:业务开发和平台建设分离 在引擎侧、平台侧和业务侧三方之间,阶段四可以做到引擎侧和平台侧之间的解耦,但是对业务侧来讲依然是高度绑定的。两者的工作模式依然是甲方和乙方的协同关系,即 业务侧掌握着业务规则,平台侧接受业务团队的风控需求,从而进行风控规则的开发。但平台团队通常人员优先,而业务团队随着业务发展会越来越壮大。 这个时候业务侧本身可以抽象出来一些基本概念,沉淀出一些业务共性的规范,并组装成一个比较友好的 DSL ,然后通过阿里云完全解耦的 Open API 实现作业的提交。 由于要同时支持集团内接近 100 个 BU,没有办法为每一个 BU 都做定制化的支持,只能把引擎的能力尽可能的开放出去,然后业务侧通过 DSL 的封装提交到平台上,真正做到了只暴露一个中台给客户。
本章主要介绍一些大规模风控的技术难点,以及阿里云在全托管 Flink 商业化产品中如何突破这些技术难点。 3.1 细粒度资源调整 在流计算系统中,数据源往往不是阻塞的节点。上游的数据读取节点由于没有计算逻辑不存在性能问题,下游的数据处理节点才是整个任务的性能瓶颈。 由于 Flink 的作业是以 Slot 来做资源划分的,默认 Source 节点和工作节点具有相同的并发度。在这种情况下我们希望可以单独调整 Source 节点和 CEP 工作节点的并发度,比如在下图中可以看到某个作业的 CEP 工作节点并发度可以达到 2000,而 Source 节点则只需要 2 个并行度,这样可以极大的提升 CEP 节点的工作性能。
另外是对 CEP 工作节点所在的 TM 内存、CPU 资源的划分,在开源 Flink 中 TM 整体同构的,也就是说 Source 节点和工作节点是完全相同的规格。从节省资源的角度考虑,真实生产环境下 Source 节点并不需要 CEP 节点一样多的内存、CPU 资源, Source 节点只需要较小的 CPU 和内存就已经能够满足数据抓取。 阿里云全托管 Flink 可以实现让 Source 节点和 CEP 节点运行在异构的 TM 上,即 CEP 工作节点 TM 资源显著大于 Source 节点 TM 资源,CEP 工作执行效率会变得更高。考虑细粒度资源调整带来的优化,云上全托管服务相比自建 IDC Flink 可节约 20% 成本。 3.2 流批一体 & 自适应 Batch Scheduler 流引擎和批引擎如果没有采用相同一套执行模式往往会遇到数据口径不一致的情况,出现这种问题的原因是流规则在批规则下很难真正的完全描述出来;比如在 Flink 中有一个特殊的 UDF,但是在 Spark 引擎中却并没有对应的 UDF。当这种数据口径不一致的时候,选择哪一方面的数据口径就成为了一个非常重要的问题。 在 Flink 流批一体的基础上,用流模式描述的 CEP 规则,完全可以在批模式下以相同的口径再跑一次并得到一样的结果,这样就不需要再去开发批模式相关的 CEP 作业。
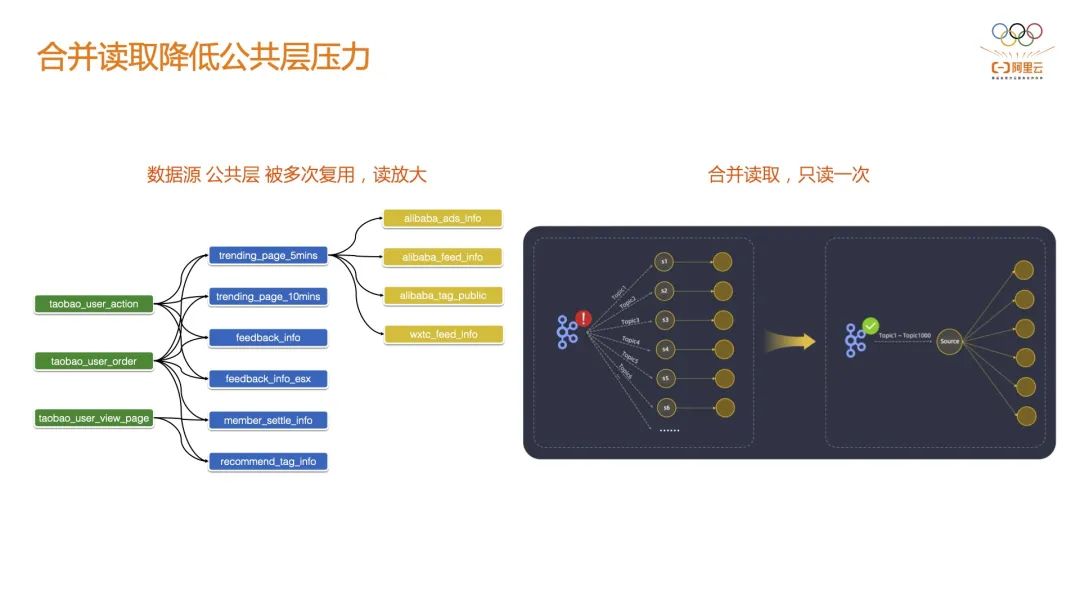
在此之上,阿里实现了自适应的 Batch Scheduler。其实 CEP 规则每天的效果产出并不一定是均衡的,比如说今天的行为序列中并没有任何异常行为,下游只有很少的数据输入,此时会为批分析预留一个弹性的集群;当 CEP 的结果很少时,下游的批分析只需要很小的资源,甚至每个批分析工作节点的并行度都不需要在一开始的时候就指定,工作节点可以根据上游数据的输出以及任务负载来自动调整批模式下的并行度,真正做到了弹性批分析,这是阿里云 Flink 流批一体 Batch Scheduler 的独特优势。 3.3 合并读取降低公共层压力 这是在实践中遇到的问题,当前的开发模式基本都是基于数据中台的,比如实时数仓。在实时数仓的场景下,数据源可能不会很多,但是中间层 DWD 会变得很多,中间层可能会被演化成很多 DWS 层,甚至也会演变成很多数据集市给到各个部门来使用,这种情况下单表的读取压力会很大。 通常多个源表彼此关联(打宽)从而形成一个 DWD 层 ,从单个源表的视角看,它会被多个 DWD 表依赖。DWD 层也会被多个不同业务域的作业消费形成 DWS。基于这种情况阿里实现了基于 Source 的合并,只需要读一次 DWD 在 Flink 侧会帮你加工成多张业务域的 DWS 表,可以非常大的减缓对公共层的执行压力。
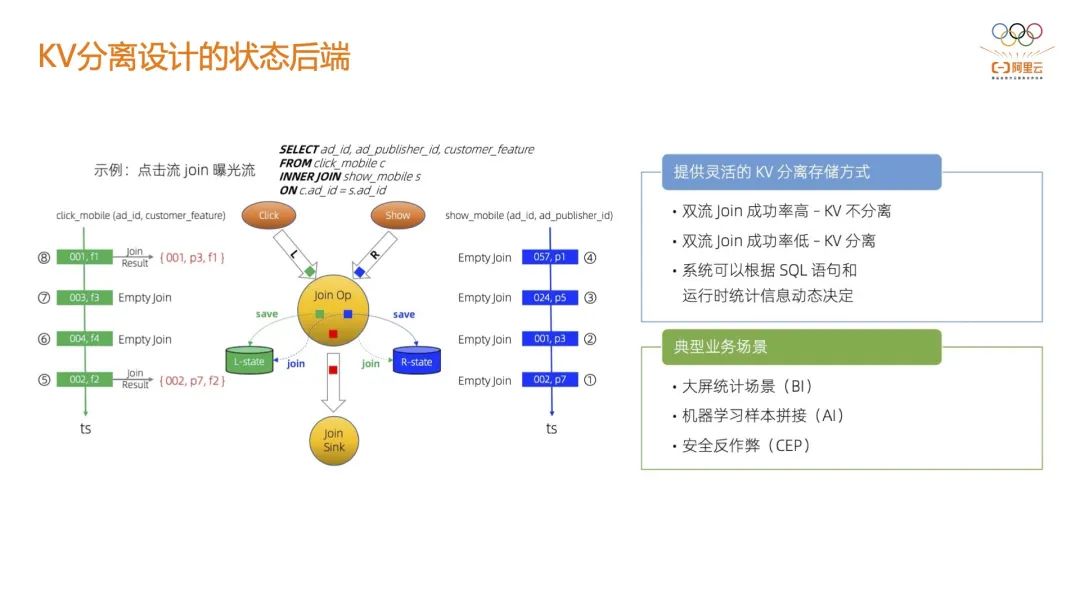
3.4 KV 分离设计的状态后端 CEP 节点在执行的时候,会涉及到非常大规模的本地数据读取,尤其是在行为序列的计算模式下,因为需要缓存前面所有的数据或者是一定时间内的行为序列。 在这种情况下,比较大的一个问题是对后端状态存储(比如:RocksDB)有非常大的性能开销,进而会影响 CEP 节点的性能。目前阿里实现了 KV 分离设计的状态后端,阿里云 Flink 默认使用 Gemini 作为状态后段,CEP 场景下实测性能至少有 100% 的提升。
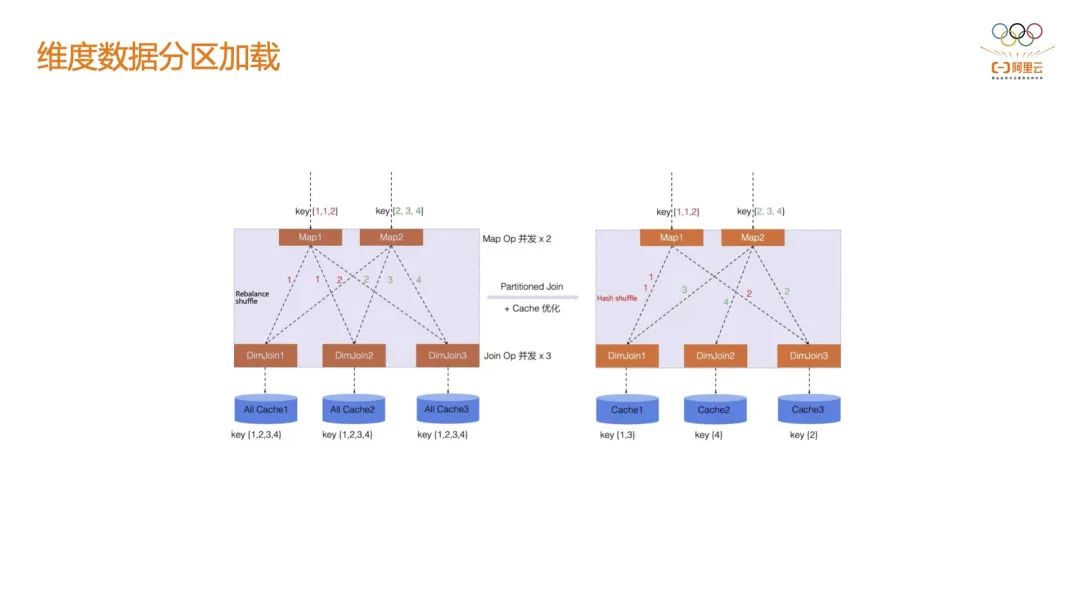
3.5 维度数据分区加载 风控在很多情况下是要基于历史行为来做分析的,历史的行为数据一般都会存在 Hive 或 ODPS 表里,这个表的规模可能是 TB 级别的。开源的 Flink 默认需要在每一个维表节点上加载这个超级大的维度表,这种方式实际上是不现实的。阿里云实现了基于 Shuffle 来做内存数据的分割,维表节点只会加载属于当前这个 Shuffle 分区的数据。
本文为从大数据到人工智能博主「jetty」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/9165/