
今天我们来讨论一个JUC中的集合类CopyOnWriteArrayList。

为什么研究这个类
在很多应用场景中,对于集合的读操作的频率一定会远远大于写操作。由于读操作根本不会修改原有的数据,因此对于每次读取都进行加锁其实是一种资源浪费。我们应该允许多个线程同时访问List的内部数据,毕竟读取操作是线程安全的。
JDK中提供了CopyOnWriteArrayList类,简称COW。为了将读取的性能发挥到极致,CopyOnWriteArrayList读取是完全不用加锁的,并且更厉害的是:写入也不会阻塞读取操作。只有写入和写入之间需要进行同步等待。这样一来,读操作的性能就会大幅度提升。那它是怎么做的呢?来吧,让我们一起研究一下。
设计原理
CopyOnWriteArrayList底层实现是通过Object[]存储元素的,内部的可变操作(add,set 等方法)都是把数据copy到一个新数组里,对新数组进行操作,再把新数组赋值给原来的对象,从而达到修改目的。
这样做的好处是不修改原数组,所以写操作不会影响到读操作。
从 CopyOnWriteArrayList 的名字就能看出CopyOnWriteArrayList 是满足CopyOnWrite 的 ArrayList,所谓CopyOnWrite 也就是说:在计算机,如果你想要对一块内存进行修改时,我们不在原有内存块中进行写操作,而是将内存拷贝一份,在新的内存中进行写操作,写完之后呢,就将指向原来内存指针指向新的内存,原来的内存就可以被回收掉了。
定位
public class CopyOnWriteArrayListE>
implements ListE>, RandomAccess, Cloneable, java.io.Serializable {
}

从类的继承关系来看
-
实现RandomAccess接口,说明可随机访问 -
实现Cloneable接口,说明可克隆 -
实现了List接口,说明是一个列表 -
实现Serializable接口,说明可序列化
接下来让我们研究一下crud。
增
public boolean add(E e);// 新增元素,放在数组尾部
public void add(int index, E element);// 新增元素,放在数组指定位置
public boolean addIfAbsent(E e);// 新增元素,如果存在则返回false,如果不存在则放入末尾返回true
public int addAllAbsent(Collection extends E> c);// 批量新增元素,将指定集合中尚未包含在此列表中的所有元素附加到此列表的末尾,返回添加的个数
public boolean addAll(Collection extends E> c);// 将指定集合中的所有元素附加到此列表的末尾。
public boolean addAll(int index, Collection extends E> c);// 从指定位置开始,将当前位于该位置的元素(如果有)和任何后续元素向右移动(增加它们的索引)。新元素将按照指定集合的迭代器返回的顺序出现在此列表中。
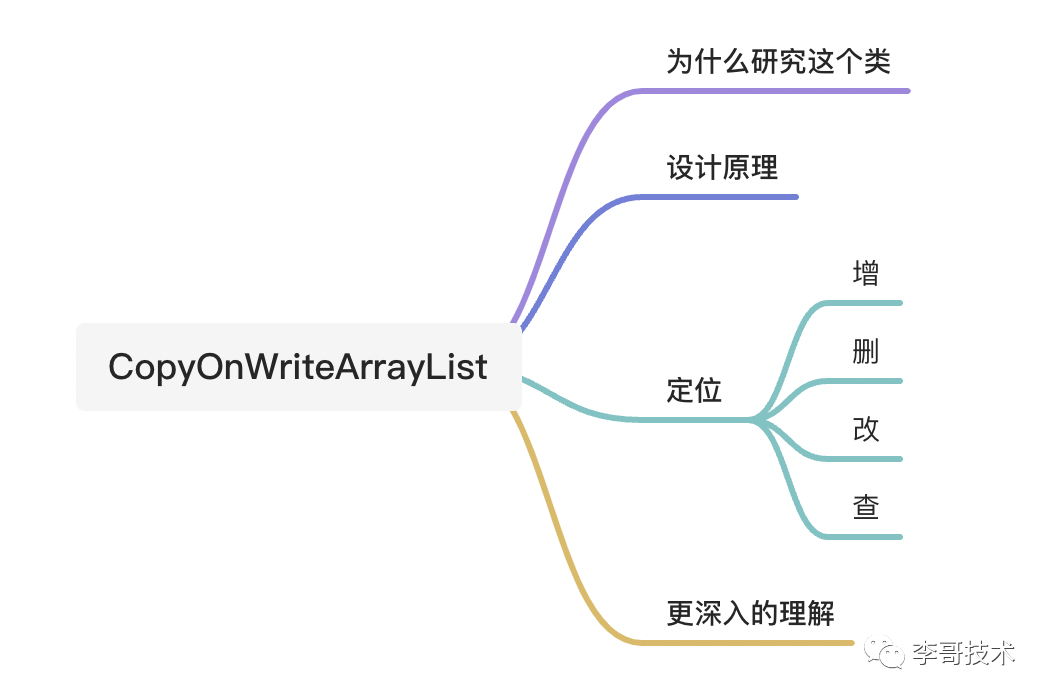
此函数用于将指定元素添加到此列表的尾部,处理流程如下:
-
获取锁(保证线程安全) -
根据Object数组复制一个长度为length+1的Object数组为newElements(此时,newElements[length]为null) -
将下标为length的数组元素newElements[length]设置为元素e,再设置当前Object[]为newElements,释放锁,返回。这样就完成了元素的添加。
删
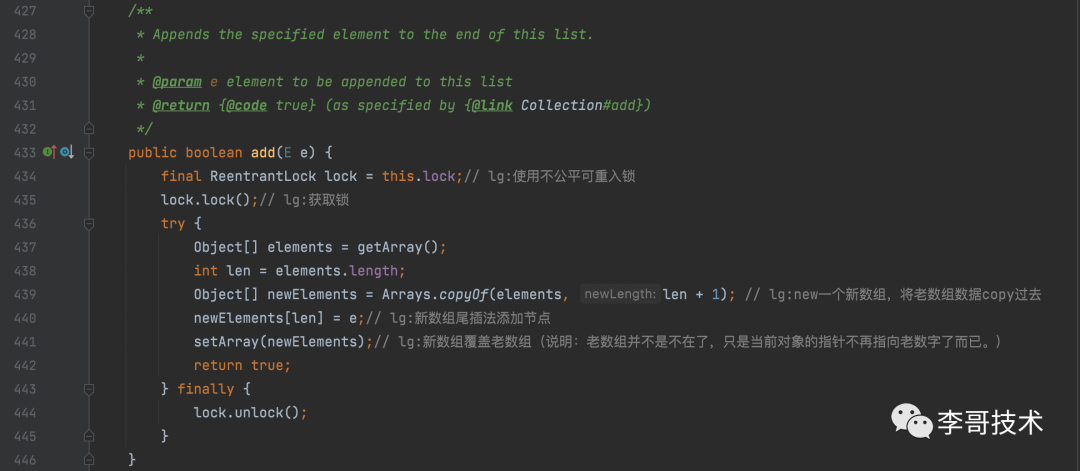
public E remove(int index);// 移除指定位置的元素,有可能抛出数组越界异常
public boolean remove(Object o);// 移除对象,如果不存在则返回false,存在则移除后返回true
public boolean removeAll(Collection> c);// 批量移除指定集合元素,这是一个非常消耗内存的方法,因为内部会额外指定一个临时数组用来存放需要保留的元素,一共涉及4个数组(老数组、传入数组、临时数组、结果数组)
public boolean removeIf(Predicate super E> filter);// 和removeAll类似,内部实现需要有临时数组,也是代价昂贵的方法,请谨慎使用
指定位置删除的逻辑如下:
-
获取锁 -
获取数组,数组长度 -
获取指定位置的元素(可能抛出数组越界异常) -
计算指定位置的元素是否是当前数组的最后一个 -
如果是最后一个->不需要挪数据,只需要创建数组,copy数据到数组即可(少copy最后一个),设置数组并返回即可 -
如果不是最后一个->创建数组,copy 0~index的数据到新数组,再copy (index+1)的数据到新数组,设置数组并返回即可
改

set方法,修改操作有可能数组越界,这一点需要注意。修改操作也是基于copy的,将数据copy到新数组,对新数组进行替换后再设置数组,从而达到set的目的。
查
public E get(int index);// 直接从数组中获取,可能抛出数组越界异常
public Spliterator spliterator() ;
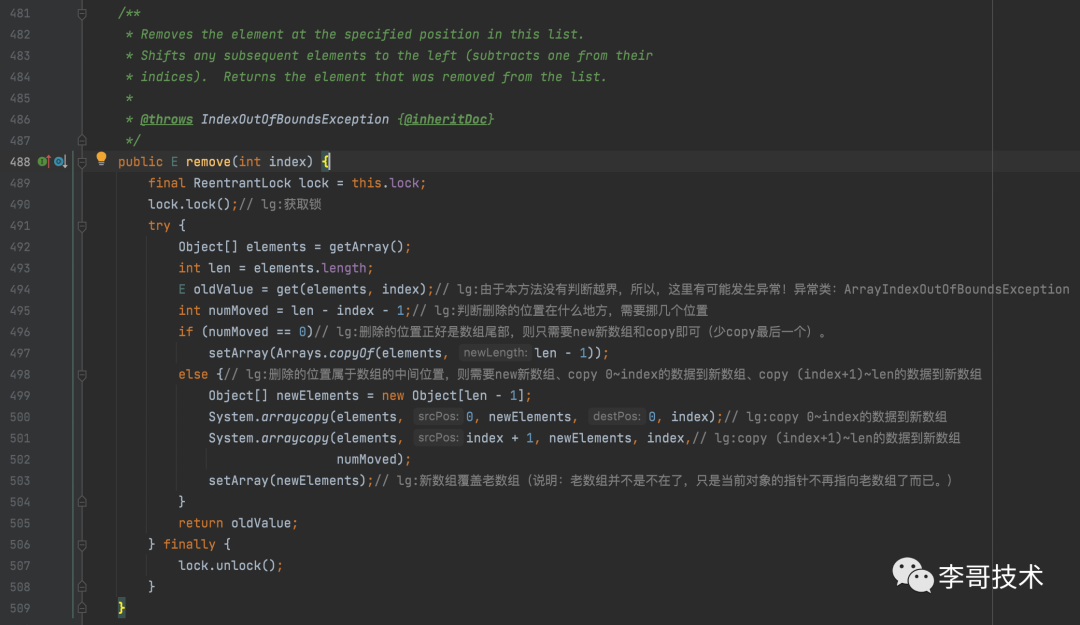
public Iterator iterator() ;// 获取数组的迭代器,它的实现类是COWIterator,内部拥有一个快照的数组属性
public ListIterator listIterator() ;// 获取listIterator迭代器,它的实现类是COWIterator,内部拥有一个快照的数组属性
public ListIterator listIterator(int index) ;// 获取listIterator迭代器,index的作用是设置迭代器当前迭代的位置
先来看一个内部类COWIterator:
COWIterator表示一个迭代器,其也有一个Object类型的数组作为CopyOnWriteArrayList数组的快照,这种快照风格的迭代器方法在创建迭代器时使用了对当时数组状态的引用。此数组在迭代器的生存期内不会更改,因此不可能发生冲突,并且迭代器保证不会抛出 ConcurrentModificationException。在创建迭代器以后,迭代器就不会反映列表的添加、移除或者更改,因为在迭代器上进行的元素更改操作(remove、set 和 add)不受支持。这些方法将抛出 UnsupportedOperationException。
更深入的理解
CopyOnWriteArrayList每次写操作都会申请新内存空间,如果数据量较大的话,很容易触发young gc或者full gc,并且拷贝也会比较消耗内存,虽然适合读多写少的应用场景,在互联网应用中,数据量稍微有点多再操作add或set,非常容易引起故障,还是要谨慎使用。
再谈读,迭代读的时候是读取快照数据,只要生成了迭代器,迭代内的快照内容将保证不会发生改变,所以不适合用于实时读场景。

深入浅出分布式系统中的缓存架构
缓存系列:缓存穿透的解决思路
本文转载自 李哥技术,原文链接:https://mp.weixin.qq.com/s/6MYz13euLRWYySEdj2v0pw。