


6月 26 号,由示说网主办,上海白玉兰开源开放研究院、云启资本、开源社联合主办的上海开源大数据技术 Meetup 如期举行。Apache Doris 社区受邀参与本次 Meetup ,来自百度的资深研发工程师 张文歆 为大家带来了题为“ 基于 Iceberg 拓展 Doris 数据湖能力的实践 ”的主题分享,以下是分享内容。
非常荣幸今天能在 Meetup 上给大家分享基于 Iceberg 拓展 Doris 数据湖能力的实践。我将从数据湖拓展产生的背景,延伸到需求分析以及组件选型,最后提供核心能力的实现方案以及一个简短的总结。

01 需求背景
首先简单介绍一下 Doris。
Doris 原先在百度内部叫做 Palo,2018 年贡献给了 Apache 社区后改名叫做 Apache Doris 。Doris 是一个 MPP 架构的分析型数据库,有几个特点:第一个特点,简单易用,支持标准 SQL 并且完全兼容 MySQL 协议,产品使用起来非常方便。

第二,它采用了预聚合技术、向量化执行引擎,再加上列式存储,是一个高效查询引擎,能在秒级甚至毫秒级返回海量数据下的查询结果。
第三,它的架构非常简单,只有两组进程:FE 负责管理元数据,并负责解析 SQL 、生成和调度查询计划; BE 负责存储数据以及执行 FE 生成的查询计划。
这个简洁高效的架构使得它运维、部署简单、扩展性强,能够支持大规模的计算。
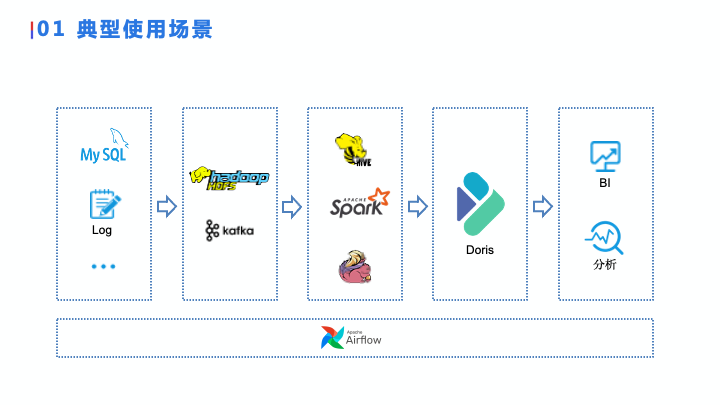
Doris 典型使用场景
通过以上特点的介绍,可以看到 Doris 其实是非常强大的。如果你的数据量比较小,可以在 Doris 里面完成一站式的分析,从 ETL 、到后面的报表分析、再到后面的交互式查询都可以在 Doris 里完成。
那么我们为什么还要在 Doris 上扩展出一个数据湖,就是我们下面要讨论的问题。
当数据量变大的时候, Doris 可能会面临几个问题:第一个,当 ETL 任务和分析任务都在 Doris 里面进行的时候,它们之间会互相影响,ETL 任务可能会影响分析的性能。

第二个问题在于 Doris 。虽然它已经很强大了,但如果在数据量非常大、查询非常复杂的情况下,它可能就无法胜任这份工作了。这个时候势必就会有其他的引擎把 ETL 任务分摊出去,再把 Hive、Spark、Flink 等计算引擎加上,这样就会引入多个模块、跟他们进行交互,用户的部署、运维还有使用就都会变得非常复杂。
我们就这一点进行了思考——既然用户遇到了这些问题,那么我们从用户的需求角度,能不能把这些重新归回到 Doris 当中,在 Doris 核心上加入一些其他的模块,是否能重新简化它的运维和部署?这就是我们所说的 Doris 数据湖能力扩展的需求出发点。
02 需求分析与组件选型
需求简介
下面我们就具体来从需求中分析一下我们需要会产生哪些问题,以及面对这些问题的组件是如何选择。
首先我们的目标是以 Doris 为核心,这点是非常重要的,也就是说我们构建出来的是 Doris 的数据湖扩展,而不是数据湖做完之后,Doris 变成了一个其他的系统,即数据湖占据了主导,同时用户的使用方式也发生了改变,这样是不能接受的。所以我们所谓的 “ Doris 数据湖能力的扩展 ”,它依然是保持了 Doris 的方式,要支持标准 SQL、支持 SQL 访问,同时要支持 MySQL 协议。
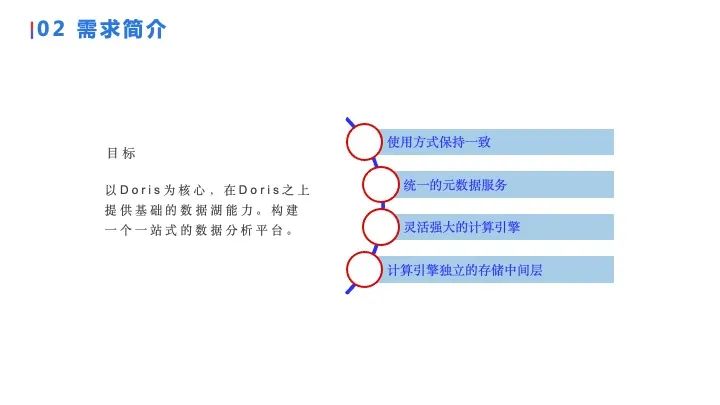
第二点也很重要,因为毕竟要扩展一个数据湖,我们要思考在这个数据湖需要什么,能让 Doris 数据湖变成一个统一的一站式数据分析平台。我们思考出来最重要的三点:
-
第一,我们需要有统一的元数据服务。因为有数据服务、结构化数据、非结构化数据等,还有一些比如像 Workflow 等元数据都需要存储,所以需要一个统一而强大的数据服务。
-
第二,刚才也提到 Doris 面对极其复杂任务的时候可能会出现一些问题,所以我们需要一个能够 Cover 住这些问题的 计算引擎。
-
第三,因为我们现在已经有两个引擎了,一个是 Doris 的 BE,一个是我们需要新加入的引擎,同时我们可能还会有一些其他引擎引入,而数据湖是一个比较灵活的东西,不像数仓,它的数据是多变的,所以我们在计算引擎和存储中间要有一个存储中间层用来描述这些表格的格式。
下面我们就从三点来分别介绍一下我们是怎么分析这个需求,同时进行组件选型的。
元数据服务选型
第一个,元数据服务。可以看到我们元数据主要有这三类,第一种结构化数据,包括导入到数据库中的表,以及一些外部表,诸如 Hive 之类;然后有一些半结构化数据,比如 Json、 Parquet 等存储在 HDFS 中的数据,以及 Kafka 中流式的数据;最后我们有一些控制流元数据如 Workflow 、MySQL 、CDC 之类。

OLAP技术选型
我们很高兴地发现,Doris 的 FE 是一个设计得非常好的元数据服务,首先它表的类型可扩展且比较通用,所以我们结构化数据和非结构化数据都可以用表格的方式展现,只需要扩展表的类型。
诸如 Hive 这种,虽然现在可能开源版还不支持数据库类型的扩展,但是这个很容易在 FE 上面去实现,去拓展一下数据库类型,然后用不同的数据库类型去代表不同的外部数据源。第三个是 Doris 的 FE 中本来就有一些数据流控制,比如 Load 任务这些,我们可以进行类似的拓展,去满足我们控制流元数据的存储。所以 Doris FE 就完全满足了我们对元数据服务的需求,我们在这一点上不用引入任何新的组件就可以了。
存储中间层选型
第二个要考虑的是存储空间层面,即数据湖表格格式的选型。
我们对于数据湖的表格模式主要有5点上面的思考:
-
第一,是要能够并发控制,因为这个数据湖是一个比较灵活的东西,大家可能进行探索、开发,在各种数据流上跑任务,所以如果你的中间表格是不支持并发写或并发读,在任务的编排上就会产生非常大的局限性。
-
第二点和第三点就是数据的可变和元数据的可变,这个也非常重要。因为我们在上面做一些探索的开发的时候,数据是经常被更新的,来支持我们业务人员来进行数据的探索。不只是数据的更新,元数据也会有更新,比如会增加列、改变列的类型,最后完成一个固定下来的数据流,所以这个两点是非常重要的。
-
第四,要方便迁移到多个计算引擎上。因为我们可以看到现在已经有 BE ,将来还会有一个新的引擎引进,还可能会把两个引擎合成一个或者引入第三个引擎,这种事情都有可能发生——如果数据湖的表格格式不支持多种类型,或者很难再迁移到其他引擎上的话,就会对我们造成非常大的困难。
-
最后一点就是需要支持多种存储后端。因为我们部署的场景比较复杂,有可能部署在公司内部,比如HDFS,也有可能部署在云上,是对象存储等等。这些都有可能,同时也要去支持很多场景。
存储中间层对比
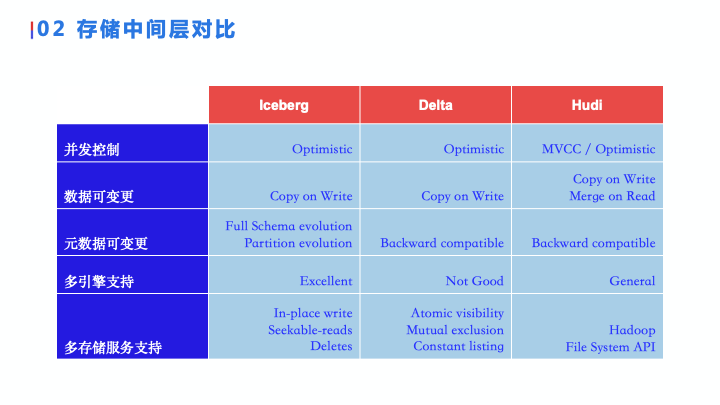
现在比较流行的三个数据湖组件是 Iceberg、Delta Lake 和 Hudi 。我们从 5 个方面来对比了这 3 个组件。
存储中间层对比
首先我们可以看到并发控制方面三个引擎都做得很好,都支持乐观锁。
第二, 在数据可变更层面上,Iceberg 、Delta 、Hudi 都支持 Copy On Write, Hudi 相比于另外两个支持了 Merge on Read。这点非常好的,他能够很好的应对流式的场景,能够减少写放大的发生。
第三,在元数据可变更上, Iceberg 很有优势,因为 Iceberg 有一个完整的、抽象的、独立于引擎的 Schema 层,它能够进行 Full Schema Evolution,即可以任意地改变列的位置、类型。它还额外提供 Partition Evolution ,能够帮助更好地管理数据。
而另外两个引擎,像 Delta 只能和 Spark 结合,直接利用了 SparkSQL 的 Schema ;而 Hudi 同样是直接使用 SparkSQL 或者 FlinkSQL 的 Schema。这样,他们在 Schema E
volution 上就比较弱,只支持在最后新增列。
第四,对于多引擎的支持方面,Iceberg 因为原生设计的时候就是为了支持多引擎,所以它分层设计的很好,当想增加一个新的引擎的时候就很简单;而 Delta 因为都是 Databricks 的产品,和 Spark 绑定的比较深,但是要移植到别的引擎还是比较困难的;而 Hudi 是可以支持多个引擎的,但如果支持别的引擎的话,增加代码会比较多,需要从底层开始往上垒代码。
最后一个,是对于后端存储的支持。Iceberg 对于后端存储支持,只要求三点,而这三点都是比较简单的,大多数的存储不管是分布式存储还是对象存储都是可以支持的。
Delta 相比于 Iceberg,他的 Constant Listing 是比较严格的要求,像有些对象存储可能满足不了。而 Hudi 并没有对存储有什么具体要求,但只要你能够在你的存储系统上实现一个Hadoop FileSystem API,就可以把 Hudi 跑在上面。
通过对比这 5 点,再结合我们的需求,我们最终选择了 Iceberg 。这并不是说 Iceberg 比其他两个绝对的好。比如说搭建一个系统的时候,如果是完全围绕 Spark 生态的话,Delta 可能会是一个更好的选择;如果更注重流式处理的话,Hudi 会是更好的选择,所以大家在选择系统的时候,要从自己的需求出发,再决定组件到底是怎么选择。
计算引擎选型
后面再说一下计算引擎的选择,其实也没有太多的选择。现在主流使用 Hive 或 Spark 做批量计算以及使用 Flink 做流式计算,这三个对于我们来讲,首先我们是一个批任务优先的系统,我们团队又很熟悉 Spark ,同时 Spark 的性能也不错,扩展性非常好,所以我们就直接选择了 Spark ,并没有太多考虑。
03 系统框架
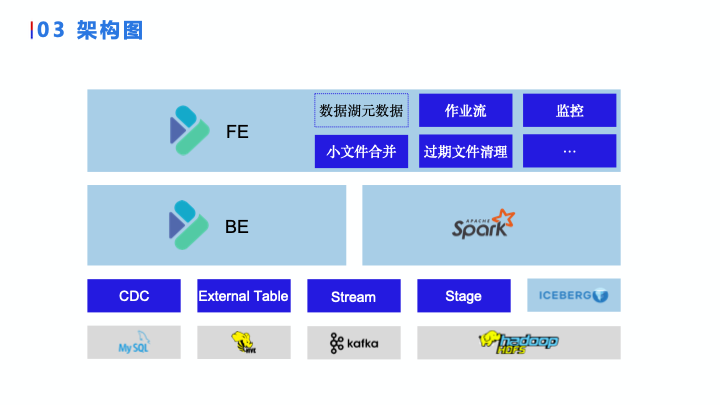
上面讲了我们是如何选择元数据服务以及计算引擎和存储中间层的。经过三个组件的选择,我们的 Doris 从原来只有一个 FE、BE ,拓展成了现在这样一个数据湖基础框架。最底层的灰色部分是外部系统的HDFS或者对象存储,上面有 Iceberg,Iceberg 上面有两个引擎 —— BE 和 Spark ,最上面有统一的元数据服务 FE 。这个框架搭建好了,我们还需要把一些功能实现在上面,才能成为一个完整的数据湖。

下面我们就看一下它的功能都有哪些。
首先,因为我们本身是以 Doris 为核心的,所以我们数据都要导入到 Doris BE 的 OLAP Table 里帮助用户去做分析。
导入到 BE 的时候有两种方案,第一种是 Doris Broker 方案,即 Doris Broker 直接去读取 Iceberg 表,把数据做一些简单的过滤变换,最后导入到 Doris BE 的 OLAP Table 里。
第二种方案是 Spark Doris Sink,这个方案就是用 Spark 直接对接不同的数据源进行计算,计算完后直接写入 BE 的 OLAP 表。
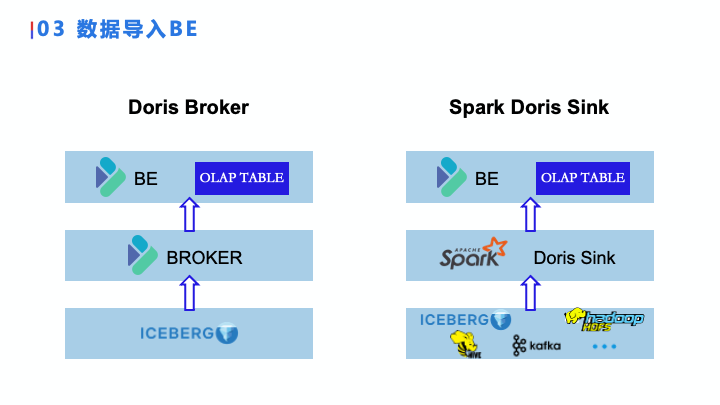
这两种导入BE的方式有什么区别呢?
最主要的区别是第一种 Doris Broker 不会消耗 Spark 的计算资源,但是增加 Iceberg 的存储消耗,也就是说当我们从 Iceberg 存储导入到 BE 的时候,这张表是几乎没有什么变化的,等于又存储了一份一样的。而 Spark 消耗了计算资源,减少了存储的使用,这一个计算资源和存储资源的平衡,在不同的业务场景会使用不同的方式。
这个数据现在已经从数据湖导到了BE里面,而数据怎么导入数据湖呢?我后面要介绍几种,在不同的场景下把数据导入到数据湖的方式。
1. STAGE
第一个是 Stage,它是用来把在 DFS 上的半结构化数据导入到数据湖的一种方式,我们 Stage 在 FE 里面的元数据存储的主要有几个,一个是 HDFS 或者对象存储就是 URL ,第二个是 URL对应里面的文件的 FileFormat 。第三个是访问存储的方式,比如说 HDFS 是否开了 HA ,或者是我们的对象结构里面是否有一个 AKSK 。然后第二个 StorageOption 里边描述了一些 FileFormat ,比如说 CSV 的分隔符等。
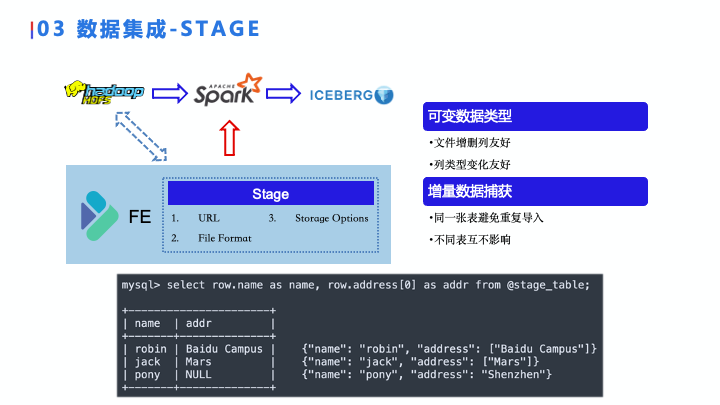
Stage 上主要有两个我认为比较好的功能,第一种是可变数据类型,不管半结构化数据里面数据有几列,在我们看来这个数据都只有一列,里面具体 Schema 列是这里面的子结构。如图,右下边的 JSON 是我们存储中的数据,可以看到第一行和第二行数据的 address 是一个数组的结构,第三行是一个字符串结构,在 SQL 里面访问 address 的时候采用了下标访问,也就是说我们认为 address 是一个数组结构,在左下边那个返回的结果里面,我们看到第一行和第二行是有结果的,到第三行就返回空了。这有什么好处呢?因为我们数据湖里的数据是不断增加的,数据结构也会变化,有可能你的文件增加了列,也有可能你的文件列的类型产生变化,如果采用传统的 Schema Infer的方式的话,读取前几行,或者随机的读取几行,去分析这个文件的 Shema,就把它当做整个表格 Schema,在处理这种情况的时候,可能会处理到这个字符串,这个任务就跑挂。而我们这种可变数据类型对于这种数据的变化是比较友好的,不会挂掉,即使有时候你数据在变化的一个刹那,也可以正常跑。
第二个就是我们在stage上实现了增量数捕获。对于传统来讲,数据入湖或者说传统的数据导入方式,我们可能会把这个增量文件传到一个新的目录里面,等增量文件一段时间(比如 15 分钟或一个小时写完之后)我们会在 Hive 里面增加一个新的 Partition ,这时候完全需要上游来操作,下游需要感知到 Partition 的存在,再去跑下游的任务。但 Stage 不需要做这些操作,只需要把数据不停的添加到你的对应的 URL 里面,我们每次跑例行任务的时候,比如你是往同一张表上去插入数据,他就会知道有哪些文件是新增的、哪些文件是改变的,自动把这些数据导入对应的表里,也不需要我们去上游维护这些事情。同时它不同的表之间是互不影响的,也就是说这是一个表级别的数据增长捕获。
以上为半结构化数据入湖的方式。
2. STREAM
下面讲一下流式存储中的数据是怎么入湖。
我们以 Kafka 为例,它的 FE 中映射的是 Stream Table 的形式,Stream Table 里存 Kafka 的服务的 Host + Port 、Topic、Consume Offset 及 Value Convertor 。我要重点讲一下这后两点,也就是 Consume Offset ,它记录的其实就是 Kafka 消费的位置。

我们在这里面做了一些处理,如果说是查询操作,比如 Select 这个 Stream Table ,Offset 是不会被更新的。这个有什么用呢?如果你是一个数据开发人员,这会方便去探查流里面的数据,你可以在这边做不停的查询,去测试你的操作,当你完全测试好之后,你去写真正的任务的时候,把它 Insert 到一个别的表里边,这个 Consume Offset 才会被更新,这样就方便我们进行数据探查。
下面说到 Value Convertor,它同样用了可变数据类型的能力,会自动解析 Value 的内容,只需要标注一下,它就会自动解析这种格式,可以看到我们这个列就直接显示出来了,我们也就不需要在这个上面反复用一些 UDF 来处理这些内部数据。
3. EXTERNAL DATABASE
下面介绍的是数据集成—— External Database。

数据集成 – EXTERNAL DATABASE
当我们集成 Hive 的时候,我们以前考虑的可能是只建一个表的映射,建表和表的映射的时候,问题就在于我们 Hive 中可能有成百上千张表,我们需要手动去把所有表都建成一个映射,即使使用了一些自动化的工具来做这些事情,出错概率也会很大。
同时如果 Hive 表进行了增删或者表结构变更,我们都需要手动维护这件事情。
External Database 就解决了这个问题,它是一个 DB 级别的映射,而在 Hive 里 DB 是不经常变化的,所以说把 DB 映射到数据湖里,表的增删就能自动探查到,也就不需要去手动维护。同时可以看到 FE 里 External Database 里还存了 Hive Version,也就是说我们支持多个不同版本的 Hive 之间进行联邦查询。
在 External Database 里我们还做了两个缓存,一个是原数据缓存,一个数据缓存。原数据缓存用来加速原数据查询,数据缓存加速数据查询。我们知道 Hive 查询比较慢的两个地方就是 List Partition 和 List File,这两个 List 都是非常耗时耗力的。
当我们有了原数据缓存之后,List Partition 的耗时就不存在,那么数据缓存是把 Hive 的数据再转成 Iceberg 存在数据湖里,这样 List File 的损耗也就没有了,同时这两个缓存是智能的,可以自动的探测到 Hive 里面的变化,不需要用户手动操作。
4. CDC
再讲一下 CDC 数据如何入到我们的数据湖。
在 MySQL 里,我们通过 Canal 来获取了 MySQL 的 Binlog ,在 FE 中存了 CDC Sync Job 对象,这里主要存了 Canal 的地址和它的 Destination,我们要处理同步哪些表、我们要同步到哪些表、以及 Binlog 的 Offset。
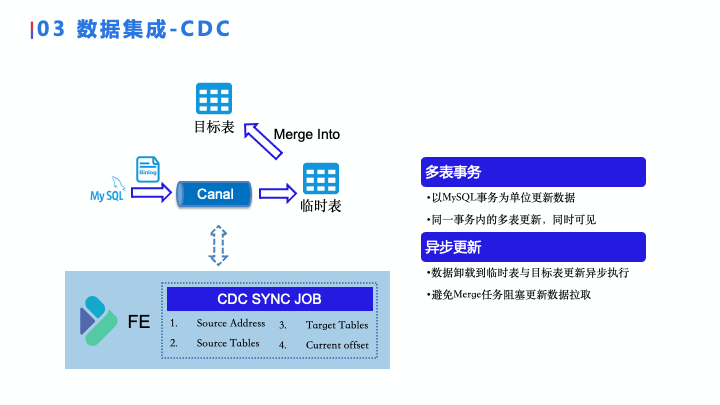
数据集成 – CDC
我们在整个 CDC 里总结了两点:
-
第一点,它支持多表事务,这个在 Doris 原本的 Load 任务里面也是支持的,也就是说他支持同时往多张表里面 Load 数据,然后同时可见,这样的话一个 MySQL 事务在数据湖内部依然是同一个事务可见的,方便下游去处理,不会产生数据的错误。
-
第二点,异步更新。因为现在 Iceberg 还不支持 Merge On Read,所以我们是用 Merge Into 来实现的,中间 Canal 数据会做一次临时表,和这个 Merge Into 的操作进行解耦,防止 Merge Into 影响 Canal 数据的抓取。Iceberg 社区 0.12 版本在努力地做Merge On Read 的功能。如果 0.12 版本功能完善的话,我们将会迁移到这个功能。
存储优化-小文件合并
上面讲了数据是如何入湖,后面还有两点我们来讲一讲,其实在大家在做大数据系统或者数据处理系统都会遇到的问题,一个是小文件合并,一个是过期文件处理这两个比较传统的问题在这个系统上是如何完成的。
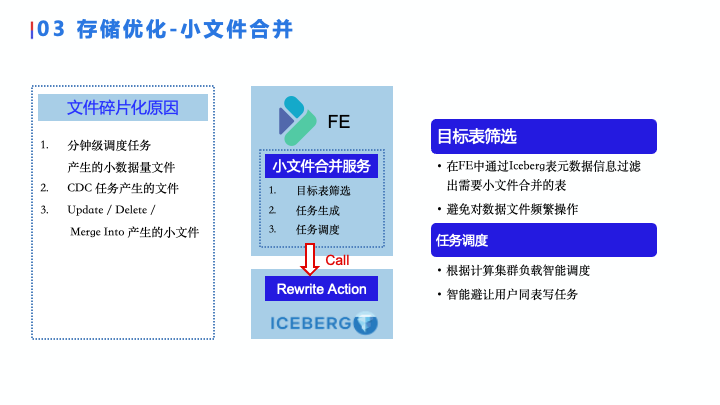
小文件合并
为什么会产生文件碎片,主要是有这几点原因:
-
第一点是有分钟级的调度任务,会产生很多的小数据量的问题;
-
第二点,刚才说了 CDC 任务,因为 CDC 任务的数据量都比较小,所以也会产生很多小文件;
-
第三点是大家可能在这个数据上数据的处理会有一些 Update、Delete 和 Merge into的操作,由于 Copy On Write的机制它也会产生很多小文件。
我们小文件合并是在 Iceberg 里 Rewrite Data File Action 的基础上做的,在这基础上我们也实现了两点:
-
第一点是目标表示的筛选,我们通过在 FE 中去探查 Iceberg 的元数据,通过小文件的占比以及小文件产生时间等一些因素,去过滤出需要小文件合并的表,而不是去暴力的把所有的表都周期性进行处理,这样我们的任务的量就大大减少。
-
第二点是我们做了一个智能的任务调度,当一张目标表需要做小件合并的时候,我们可以知道这张表在我们系统里是否有周期性的调度任务在同时发生,如果有的话我们会智能避让一些行为,因为像 Iceberg 这种表格存储格式的话,它虽然是乐观性支持并发写数据,但是如果要同时做 Update 等操作的话,还是会有任务失败的概率。智能避让这种用户的任务的话,会减少这种情况发生,也可以减少系统资源的浪费。
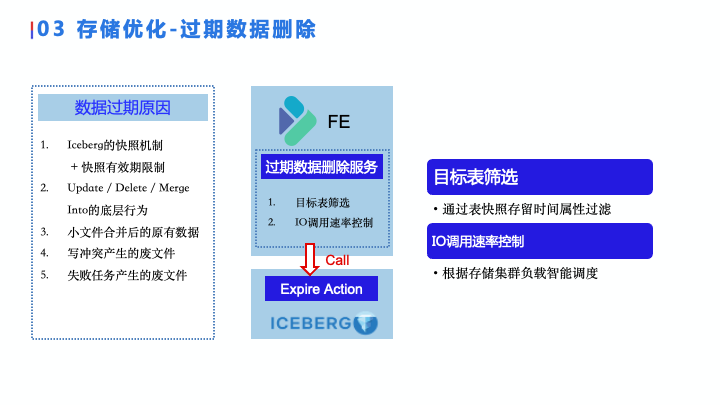
存储优化-过期数据删除
第二个就是过期数据删除,同样的过期数据删除在 Iceberg 上也提供了很多的 Action 去做这个事情,一个是过期数据删除,还有无用数据删除以及过期的原数据的删除。
在 Action之上我们同样有了两点,一个是目标表筛选,看看这些表是否需要有大量的文件需要删除。第二个是我们做了智能 IO 调用速率控制,根据集群的负载来决定我们删除的速率,防止后台任务影响前端任务执行。
过期数据删除
其他功能
除了前面几点,我们还有很多其他的功能比如,任务流调度、实时监控、用户行为审计、克隆表等等这些功能,就不在这做一一的介绍了。
过期数据删除
整体架构
Doris 数据湖架构
04 总结
最后做一个简单的总结,Doris 数据湖的扩展就是以 Doris 为核心、聚焦用户的需求、以降低用户使用难度为目标、实现最小的功能集,来拓展 Doris 数据湖能力。
本文为从大数据到人工智能博主「bajiebajie2333」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/bigdata/doris/doris-advanced/5272/