


导读:随着营销 3.0 时代的到来,企业愈发需要依托强大 CDP 能力解决其严重的数据孤岛问题,帮助企业加温线索、促活客户。但什么是 CDP 、好的 CDP 应该具备哪些关键特征?本文在回答此问题的同时,详细讲述了爱番番租户级实时 CDP 建设实践,既有先进架构目标下的组件选择,也有平台架构、核心模块关键实现的介绍。
全文 19135 字,预计阅读时间 26 分钟
一、CDP是什么
1.1 CDP由来
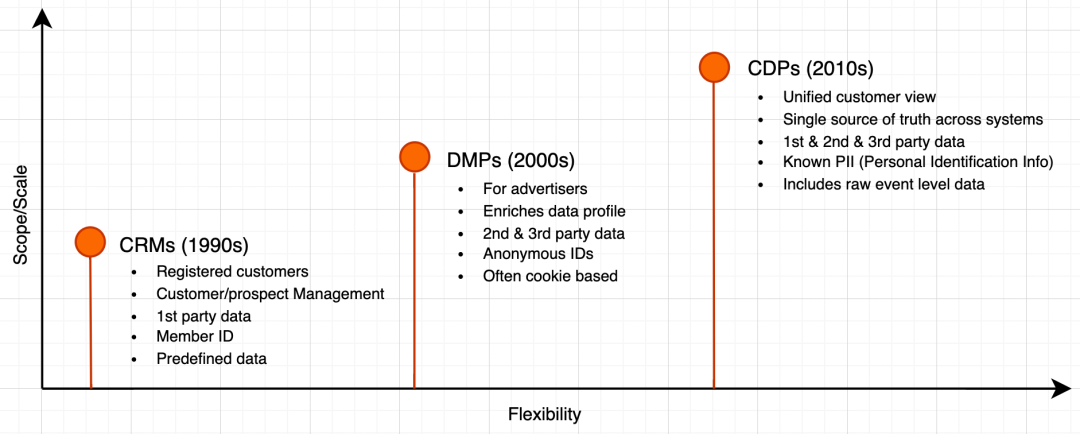
CDP(Customer Data Platform)是近些年时兴的一个概念。随着时代发展、大环境变化,企业在自有媒体增多的同时,客户管理、营销变难,数据孤岛问题也愈发严重,为了更好的营销客户 CDP 诞生了。纵向来看,CDP 出现之前主要经历了两个阶段:
-
CRM 时代,企业通过电话、短信、E-mail 与现有客户和潜在客户的互动,以及执行数据分析,从而帮助推动保留和销售; -
DMP 阶段,企业通过管理各大互联网平台进行广告投放和执行媒体宣传活动。
-
客户管理:CRM 侧重于销售跟单,CDP 更加侧重于营销。 -
触点:CRM 的客户主要是电话、QQ、邮箱等,CDP 还包含租户的自有媒体关联的用户账号(例如企业自己的网站、App、公众号、小程序)。
-
数据类型:DMP是匿名数据为主,CDP 以实名数据为主。
-
数据存储:DMP数据只是短期存储,CDP 数据长期存储。
1.2 CDP定义
-
Packaged Software:基于企业自身资源部署,使用统一软件包部署、升级平台,不做定制开发。 -
Persistent , Unified Customer Database:抽取企业多类业务系统数据,基于数据某些标识形成客户的统一视图,长期存储,并且可以基于客户行为进行个性化营销。 -
Accessible to Other Systems:企业可以使用 CDP 数据分析、管理客户,并且可以通过多种形式取走重组、加工的客户数据。
1.3 CDP分类
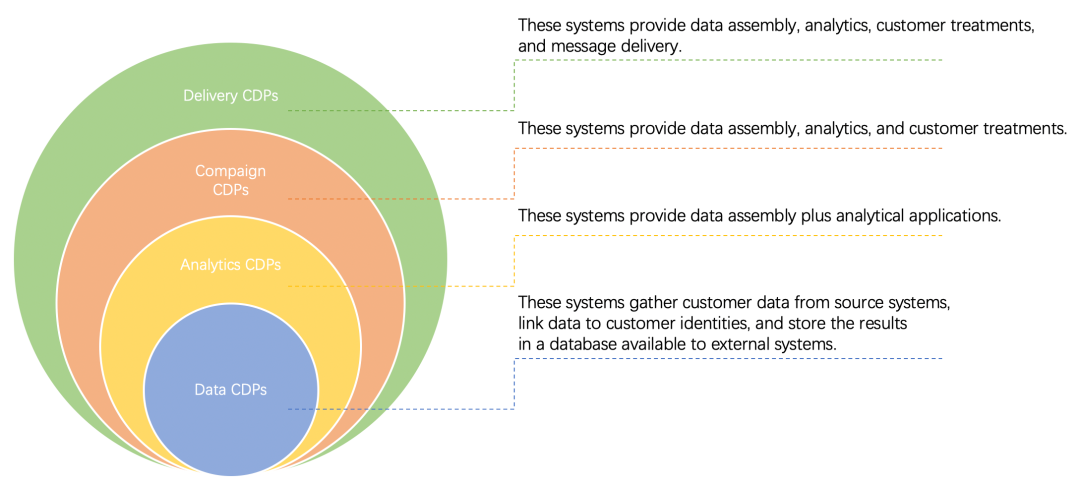
主要分为四类:
-
Data CDPs:主要是客户数据管理,包括多源数据采集、身份识别,以及统一的客户存储、访问控制等。 -
Analytics CDPs:在包含 Data CDPs 相关功能的同时,还包括客户细分,有时也扩展到机器学习、预测建模、收入归因分析等。 -
Campaign CDPs:在包含 Analytics CDPs 相关功能的同时,还包括跨渠道的客户策略(Customer Treatments),比如个性化营销、内容推荐等实时交互动作。 -
Delivery CDPs:在包括 Campaign CDPs 相关功能的同时,还包括信息触达(Message Delivery),比如邮件、站点、APP、广告等。
二、挑战与目标
2.1 面临挑战
业务层面
爱番番的客户涉及多类行业,有的B2C的也有B2B2C的。相对与B2C,B2B2C的业务场景复杂度是指数级上升。在管理好B、C画像的同时,还要兼顾上层服务的逻辑里,比如身份融合策略、基于行为的圈选等。另外,在许多业务场景也存在很多业务边界不清晰的问题。
CDP 目前主要以 SaaS 服务服务于中小企业,但不排除后续支持大客户 OP 部署(On-Premise,本地化部署)的需求,如何做好组件选型支持两类服务方式?
2.2 RT-CDP建设目标
2.2.1 关键业务能力
-
灵活的数据对接能力:可以对接客户各种数据结构多类数据源的客户系统。另外,数据可以被随时访问。
-
同时支持 B2C和B2B两类数据模型:面向不同的行业客户,用一套服务支撑。
-
统一的用户、企业画像:包含属性、行为、标签(静态、动态(规则)标签、预测标签)、智能评分、偏好模型等等。
-
实时的全渠道身份识别、管理:为了打破数据孤岛,打通多渠道身份,是提供统一用户的关键,也是为了进行跨渠道用户营销的前提。
-
强大的用户细分能力(用户分群):企业可以根据用户属性特征、行为、身份、标签等进行多维度多窗口组合的用户划分,进行精准的用户营销。
-
用户的实时交互、激活:面对用户习惯变化快,实时感知用户行为进行实时自动化营销能力尤为重要。
-
安全的用户数据管理:数据长期、安全存储是数据管理平台的基本要求。
2.2.2 先进技术架构
明确平台业务目标的同时,一个先进的技术架构也是平台建设的目标。如何做到平台架构,我们有如下几个核心目标:
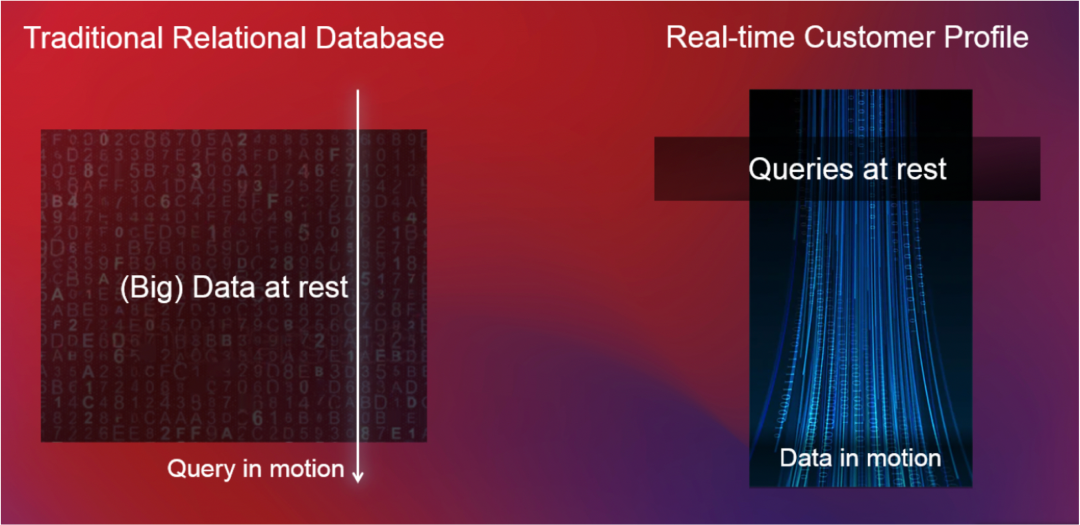
在传统数据库、数据处理上,还主要是『数据被动,查询主动』。数据在数据库中处于静止状态,直到用户发出查询请求。即使数据发生变化,也必须用户主动重新发出相同的查询以获得更新的结果。但现在数据量越来越大、数据变化及时感知要求越来越高,这种方法已无法满足我们与数据交互的整个范式。
现在系统架构设计如下图,更倾向于主动驱动其他系统的架构,比如领域事件驱动业务。数据处理亦是需要如此:『数据主动、查询被动』。
举个例子,企业想找到访问过企业小程序的用户进行发短信时,两种分别如何做?
-
传统方式:先将用户数据存入存储引擎,在企业发短信之前再将查询条件转换成sql,然后去海量数据中筛选符合条件的用户。
-
现代方式:在用户数据流入数据系统时,进行用户画像丰富,然后基于此用户画像进行符不符合企业查询条件的判断。它只是对单个用户数据的规则判断,而不是从海量数据筛选。
三、技术选型
3.1 身份关系存储新尝试
在 CDP 中跨渠道身份打通(ID Mapping)是数据流渠道业务的核心,需要做到数据一致、实时、高性能。
传统的 ID Mapping 是怎么做?
-
数据高并发实时写入能力有限;
-
一般身份识别都需要多跳数据关系查询,关系型数据库要查出来期望数据就需要多次 Join,查询性能很低。
2.使用 Spark GraphX 进行定时计算一般是将用户行为存入 Graph 或者 Hive,使用 Spark 定时将用户行为中身份信息一次性加载到内存,然后使用 GraphX 根据交叉关系进行用户连通性计算。该方案也存在两个问题:
-
不实时。之前更多场景是离线聚合、定时对用户做动作;
-
随着数据量增加计算耗时会越来越高,数据结果延迟也会越来越高。
我们怎么做?
图框架对比
大家也可以结合最新的图数据库的排名走势,进行重点调研。另外,关于主流图库对比案例也越来越多,可以自行参考。在分布式、开源图数据库中主要是 HugeGraph、DGraph 和 Nebula 。我们在生产环境主要使用了 DGraph 和 Nebula 。因为爱番番服务都是基于云原生建设,平台建设前期选择了 DGraph ,但后来发现水平扩展受限,不得不从 DGraph 迁移到 Nebula (关于DGraph到Nebula的迁移,坑还是挺多的,后续会有专门文章介绍,敬请期待)。

网上对 DGraph 和 Nebula 对比很少,这里简单说一下区别:
-
集群架构:DGraph 是算存一体的,其存储是 BadgerDB , go 实现的对外透明;Nebula 读写分离,但默认是 RocksDB存储 (除非基于源码更换存储引擎,也有公司在这么搞),存在读写放大问题;
-
数据切分:DGraph 是基于谓词切分(可以理解为点类型),容易出现数据热点,想支持多租户场景,就需要动态创建租户粒度谓词来让数据分布尽量均匀( DGraph 企业版也支持了多租户特性,但收费且依然没考虑热点问题);Nebula 基于边切分,基于 vid 进行 Parti tion ,不存在 热点问题,但图空间创建时需要预算好分区个数,不然不好修改分区数。 -
全文检索:DGraph支持;Nebula提供 listener 可以对接 ES。 -
Query语法:DGraph 是自己的一个查询语法;Nebula 有自身查询语法之外,还支持了 Cypher 语法( Neo4j 的图形查询语言),更符合图逻辑表达。 -
事务支持:DGraph 基于 MVCC 支持事务;Nebula 不支持,其边的写事务也是最新版才支持的(2.6.1)。 -
同步写:DGraph、Nebula 均支持异步、同步写。 -
集群稳定性:DGraph 集群更稳定;Nebula 的稳定性还有待提升,存在特定运算下偶发 Crash 的情况。 -
生态集群:DGraph 在生态集成更成熟,比如与云原生的集成;Nebula 在生态集成范围上更多样一些,比如 nebula-flink-connector、nebula-spark-connector 等,但在各类集成的成熟度上还有待提升。
3.2 流式计算引擎选择
https://blog.csdn.net/weixin_39478115/article/details/111316120

3.3 海量存储引擎取舍
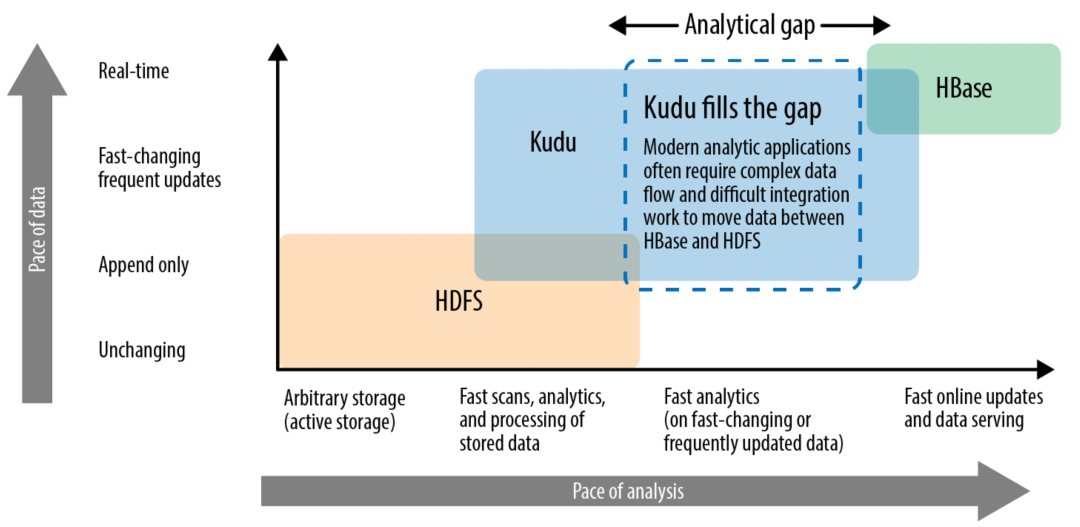
结合我们的平台建设理念,实时、高吞吐的数据存储、更新是核心目标,在数据复杂查询、数据应用的 QPS 上不高(因为核心的业务场景是基于实时流的实时客户处理),再加上 Cloudera Impala 无缝集成Kudu,我们最终确定 Impala+Kudu 做为平台的数据存储、查询引擎。
基于 Impala+Kudu 的选型,在支持 OP 部署时是完全没有问题的,因为各个企业的数据体量、数据查询 QPS 都有限,这样企业只需要很简单的架构就可以支持其数据管理需求,提高了平台稳定性、可靠性,同时也可以降低企业运维、资源成本。但由于 Impala并发能力有限(当然在 Impala 4.0 开始引入多线程,并发处理能力提升不少),爱番番的私域服务目前还是以 Saas 服务为重,想在 Saas 场景下做到高并发下的毫秒级数据分析,这种架构性能很难达标,所以我们在分析场景引入了分析引擎 Apache Doris。Apache Doris 是基于 MPP 架构的 OLAP 引擎,相对于 Druid、ClickHouse 等开源分析引擎,Apache Doris 具有如下特点:
-
支持多种数据模型,包括聚合模型、Uniq 模型、Duplicate 模型;
-
支持 Rollup、物化视图;
-
在单表、多表上的查询性能都表现很好;
-
支持 MySQL 协议接入、学习成本低;
-
无需集成 Hadoop 生态,集群运维成本也低很多。
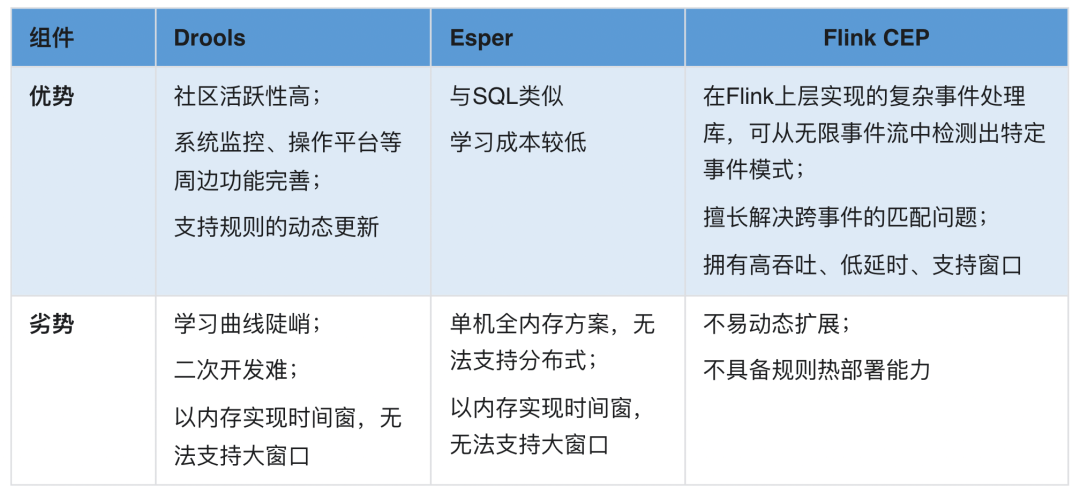
3.4 规则引擎调研
实时规则引擎主要用于客户分群,结合美团的规则对比,几个引擎(当然还有一些其他的 URule、Easy Rules 等)特点如下:
四、平台架构
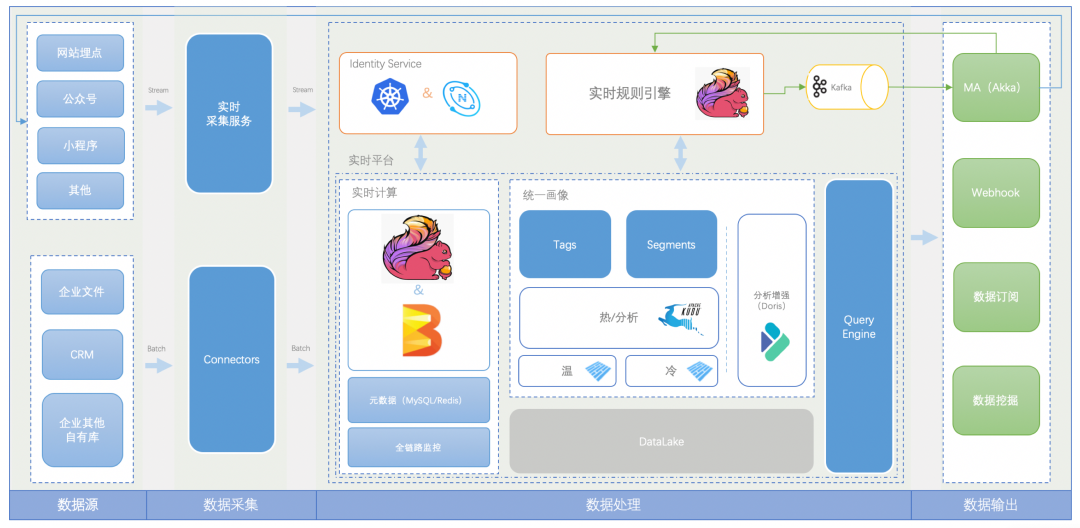
4.1 整体架构

RT-CDP 也是就两部分功能进行拆分,主要包含五部分:数据源、数据采集、实时数仓,数据应用和公共组件,除公共组件部分是横向支撑外,其他四部分就是标准的数据对接到数据应用的四个阶段:
-
数据源:这里的数据源不仅包含客户私有数据,也包括在各个生态上的自有媒体数据,比如微信公众号、微信小程序、企微线索、百度小程序、抖音企业号、第三方生态行为数据等。 -
数据采集:大多中小企业没有研发能力或者很薄弱,如何帮助快速将自有系统对接到爱番番 RT-CDP 是这层需要重点考虑的,为此我们封装了通用的采集 SDK 来简化企业的数据采集成本,并且兼容 uni-app 等优秀前端开发框架。另外,由于数据源多种多样、数据结构不一,为了简化不断接入的新数据源,我们建设了统一的采集服务,负责管理不断新增的数据通道,以及数据加解密、清洗、数据转换等数据加工,这个服务主要是为了提供灵活的数据接入能力,来降低数据对接成本。 -
实时算存:在采集到数据后就是进行跨渠道数据身份识别,然后转换成结构化的客户统一画像。就数据管理来说,这层也包含企业接入到 CDP 中的碎片客户数据,为了后续企业客户分析。经过这层处理,会形成跨渠道的客户身份关系图、统一画像,然后再通过统一视图为上层数据接口。另外,就是数仓常规的数据质量、资源管理、作业管理、数据安全等功能。 -
数据应用:这层主要是为企业提供客户管理、分析洞察等产品功能,比如丰富的潜客画像、规则自由组合的客户分群和灵活的客户分析等。也提供了多种数据输出方式,方便各个其他系统使用。 -
公共组件:RT-CDP 服务依托爱番番先进的基础设施,基于云原生理念管理服务,也借助爱番番强大的日志平台、链路追踪进行服务运维、监控。另外,也基于完备的 CICD 能力进行 CDP 能力的快速迭代,从开发到部署都是在敏捷机制下,持续集成、持续交付。
4.2 核心模块
从数据源和 RT-CDP 数据交互方式上,主要分为实时流入和批次拉取。针对两种场景,我们抽象了两个模块:实时采集服务和 Connectors。
-
实时采集服务:该模块主要是对接企业已有的自有媒体数据源,爱番番业务系统领域事件以及爱番番合作的第三方平台。这层主要存在不同媒体平台API协议、场景化行为串联时的业务参数填充、用户事件不断增加等问题,我们在该模块抽象了数据 Processor& 自定义 Processor Plugin 等来减少新场景的人工干预。
-
Connectors :该模块主要是对接企业的自有业务系统的数据源,比如 MySQL、Oracle、PG 等业务库,这部分不需要实时接入,只需按批次定时调度即可。这里需要解决的主要是多不同数据源类型的支持,为此我们也抽象了 Connector 和扩展能力,以及通用的调度能力来支持。针对两种场景下,存在同一个问题:如何应对多样数据结构的数据快读快速接入?为此,我们抽象了数据定义模型(Schema),后面会详细介绍。
2.数据处理
-
Identity Service:该模块提供跨渠道的客户识别能力,是一种精准化的 ID Mapping,用于实时打通进入 RT-CDP 的客户数据。该服务持久化了客户身份相关关系图放在 Nebula 中,会根据实时数据、身份融合策略进行实时、同步更新Nebula,然后将识别结果填充到实时消息。进入 CDP 数据只有经过 Identity Service 识别后才继续往后走,它决定了营销旅程的客户交互是否符合预期,也决定了 RT-CDP 的吞吐上限。 -
实时计算:该模块包含了所有数据处理、加工、分发等批流作业。目前抽象了基于 Apache Beam 的作业开发框架,尝试批流都在 Flink 上做,但有些运维 Job 还用了 Spark ,会逐渐去除。 -
统一画像:该模块主要是持久化海量的潜客画像,对于热数据存储在 Kudu 中,对于温、冷的时序数据定时转存到 Parquet 中。潜客画像包括客户属性、行为、标签、所属客群、以及聚合的客户扩展数据等。虽然标签、客群是单独存在的聚合根,但是在存储层面是一致的存储机制。另外,标准 RT-CDP 还应该管理客户碎片数据,所以统一画像和数据湖数据如何交互是后续建设的重点。 -
统一查询服务:在 RT-CDP 中,客户数据分散在图数据库、Kudu、增强的分析引擎和数据湖,但对用户来说只有属性、行为、标签、客群等业务对象,如何支持产品上透明使用?我们通过统一视图、跨源查询建设了此统一查询服务,该服务支持了Impala、Doris、MySQL、Presto、ES 等查询存储引擎以及 API 的跨源访问。 -
实时规则引擎:该模块主要是基于 Flink 提供实时规则判断,来支持圈群、基于规则的静态打标、规则标签等业务场景。
4.3 关键实现
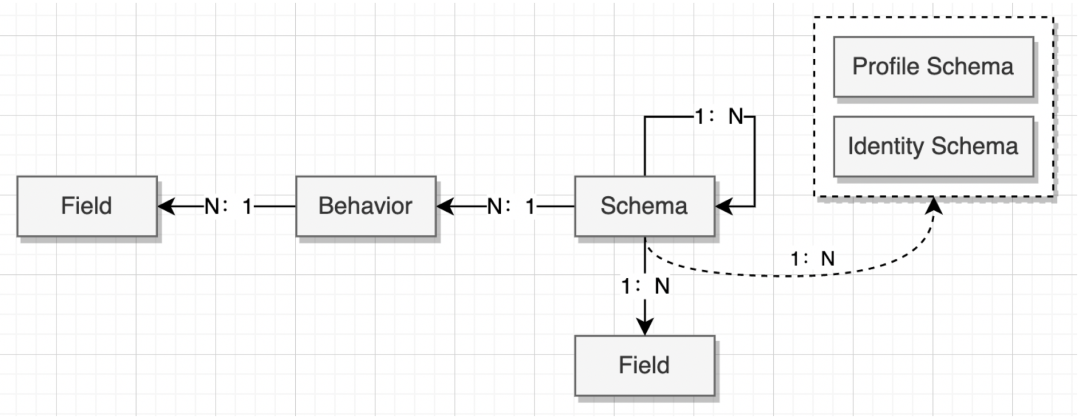
4.3.1 数据定义模型
从这几个实体来说明 Schema 的特点,如下图:
-
Field:字段是最基本的数据单元,是组成 Schema 的最小粒度元素。 -
Schema:是一组字段、Schema 的集合,它本身可以包含多个字段(Field),字段可以自定义,比如字段名、类型、值列表等;也可以引用一个或多个其他 Schema,引用时也可以以数组的形式承载,比如一个 Schema 里面可以包含多个 Identity 结构的数据。 -
Behavior:是潜客或企业的不同行为,本身也是通过 Schema 承载,不同的 Behavior 也可以自定义其特有的 Field。

扩展1:借助字段映射解决多租户无限扩列问题
-
事实表只做无业务含义的字段;
-
在数据接入、查询时通过业务字段(逻辑字段)和事实字段的映射关系进行数据转换后与前端、租户交互。
4.3.2 Identity Service

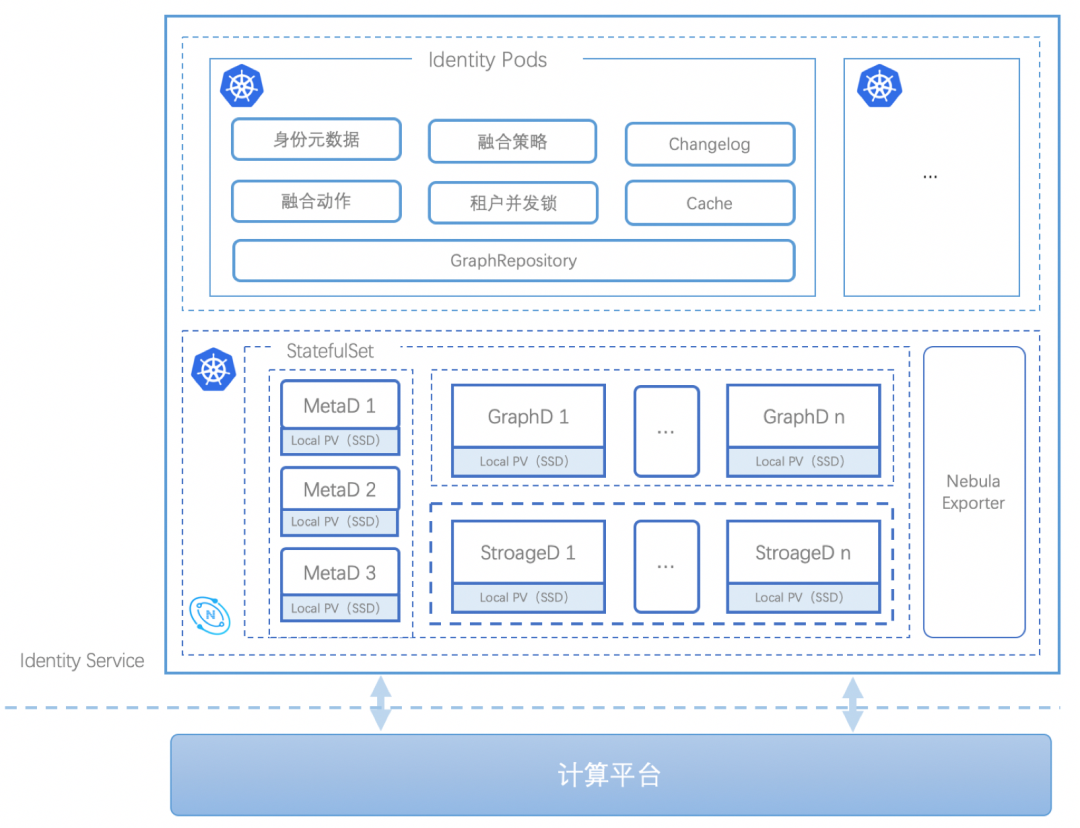
-
使用 Nebula Operator 自动化运维我们 K8s 下的 Nebula 集群;
-
使用 Statefulset 管理 Nebula 相关有状态的节点 Pod;
-
每个节点都是使用本地 SSD 盘来保证图存储服务性能。
-
设计好数据模型,尽量减少Nebula内部IO次数;
-
合理利用Nebula语法,避免Graphd多余内存操作;
-
查询上,尽量减少深度查询;更新上,控制好写粒度、降低无事务对业务的影响。
扩展1:如何解决未登录时潜客打通问题
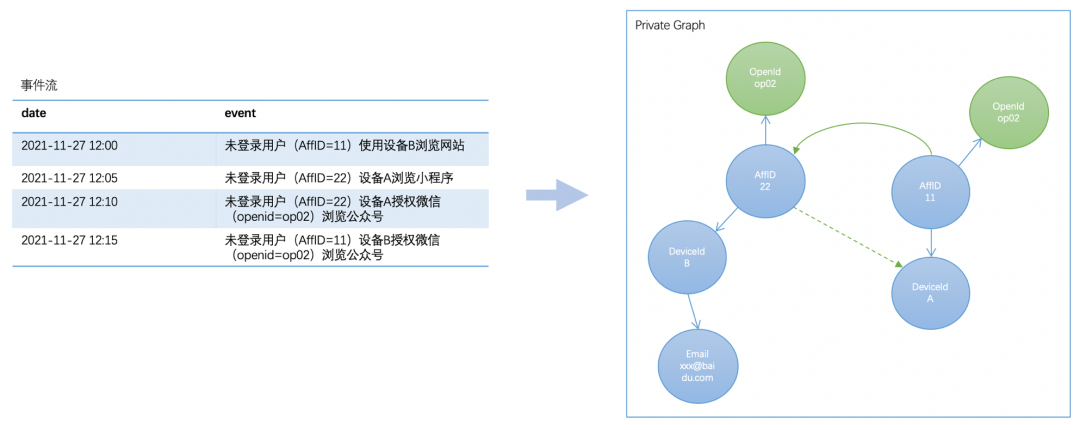
4.3.3 实时存算
4.3.3.1 流计算
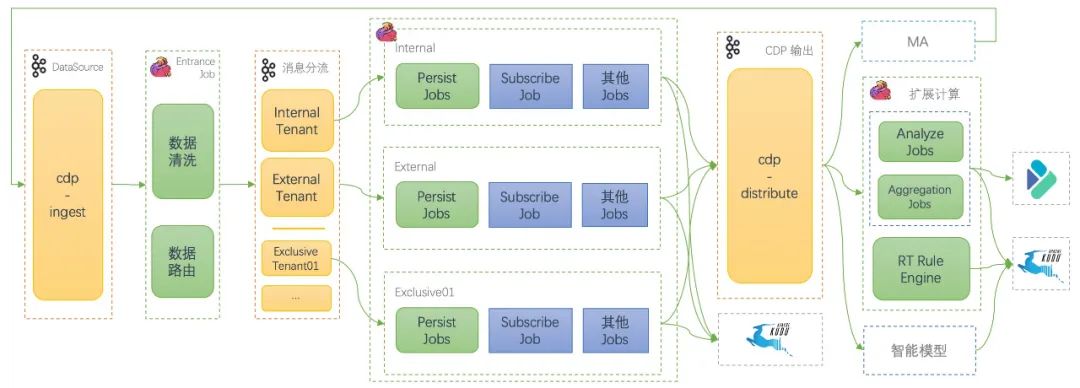
-
主要采集和格式化的数据,会统一发到 cdp-ingest 的 topic; -
RT-CDP 有个统一的入口 Job(Entrance Job)负责数据的清洗、校验、Schema 解析以及身份识别等,然后根据租户属性进行数据分发。因为这是 RT-CDP 入口 Job,需要支持横向扩缩,所以这个作业是无状态J ob。 -
经过数据分发,会有不同的 Job 群进行分别的数据处理、持久化,以及数据聚合等数据加工逻辑,一方面丰富潜客画像,另一方面为更多维度的潜客圈群提供数据基础。 -
最后会将打通的数据分发到下游,下游包括外部系统、数据分析、实时规则引擎、策略模型等多类业务模块,以便进行更多的实时驱动。
扩展1:数据路由
扩展2:自定义Trigger批量写
一般租户的一次营销活动,会集中产生一大批潜客行为,这其中包括系统事件、用户实时行为等,这种批量写的方式,可以有效提高吞吐。
4.3.3.2 实时存储

扩展1:基于数据分层增强存储
-
在热、温、冷之上建立统一视图,上层根据视图进行数据查询。 -
然后每天定时进行热到温、温到冷的顺序性的分别离线迁移,在分别迁移后会分别进行视图的实时更新。
扩展2:基于潜客融合路径的映射关系管理解决数据迁移问题
为什么需要管理映射?
-
新增一张潜客融合关系表(user_change_rela)维护映射关系; -
在融合关系表和时序表(比如 event)之上创建视图,做到对业务层透明。
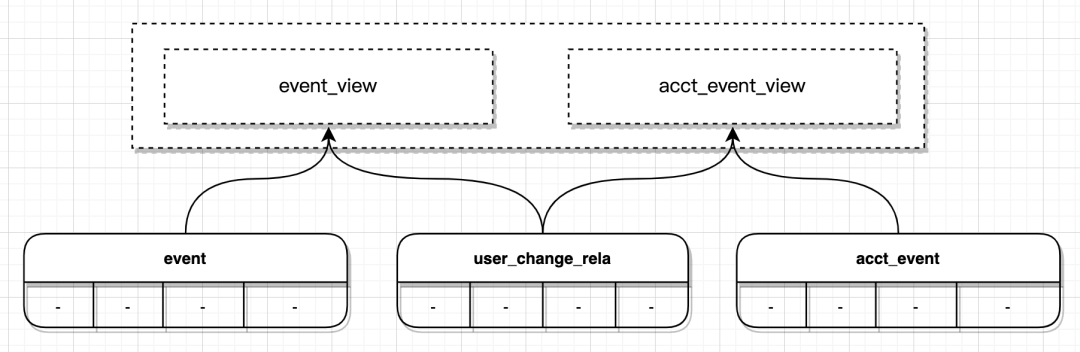

4.3.3.3 分析增强
-
使用 flink-doris-connector 往 Doris 写数据,比使用 Routine Load 方式少一次 Kafka。
-
使用 flink-doris-connector 比 Routine Load 方式在数据处理上,也能更加灵活。
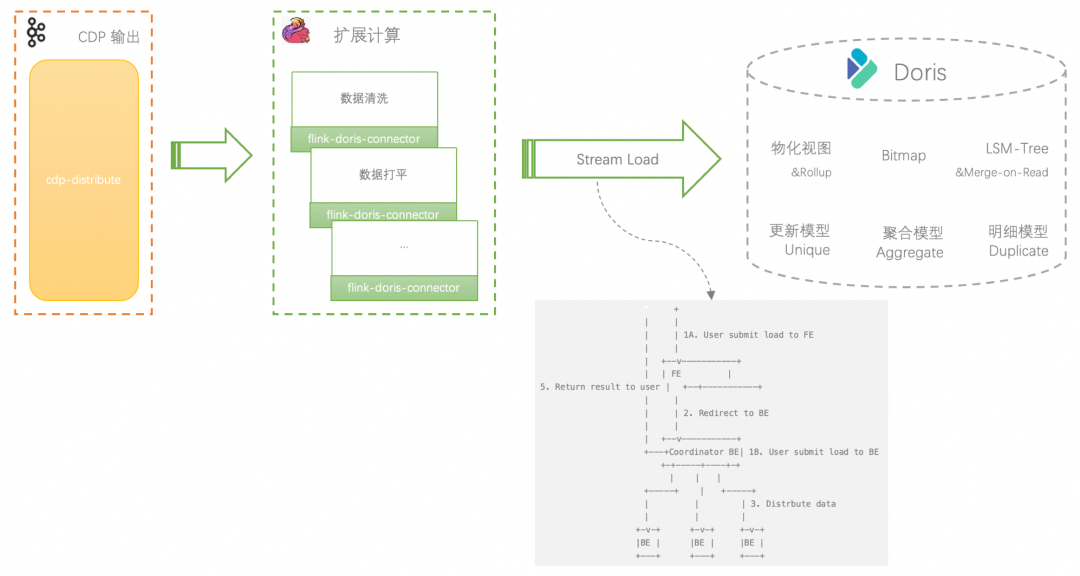
扩展1:RoutineLoad和Stream Load区别
Stream Load方式
4.3.4 实时规则引擎
面临的问题是什么?
-
海量数据实时判断 -
窗口粒度数据聚合的内存占用问题 -
滑动窗口下的窗口风暴 -
无窗口规则的数据聚合问题 -
潜客数据变更后的窗口数据更新
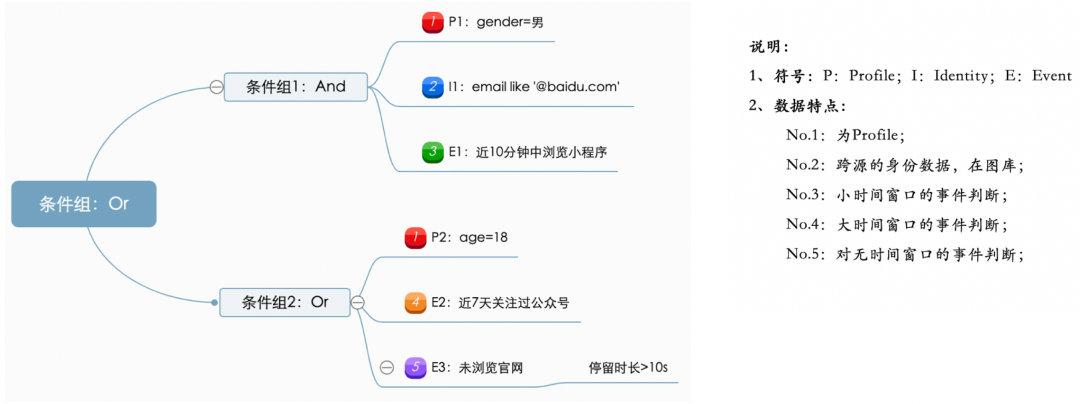

另外,规则引擎是一个独立于 Segment 等业务对象的服务,可以支持圈群、打标签、 MA 旅程节点等各个规则相关的业务场景。
4.3.5 扩展
4.3.5.1 弹性集群
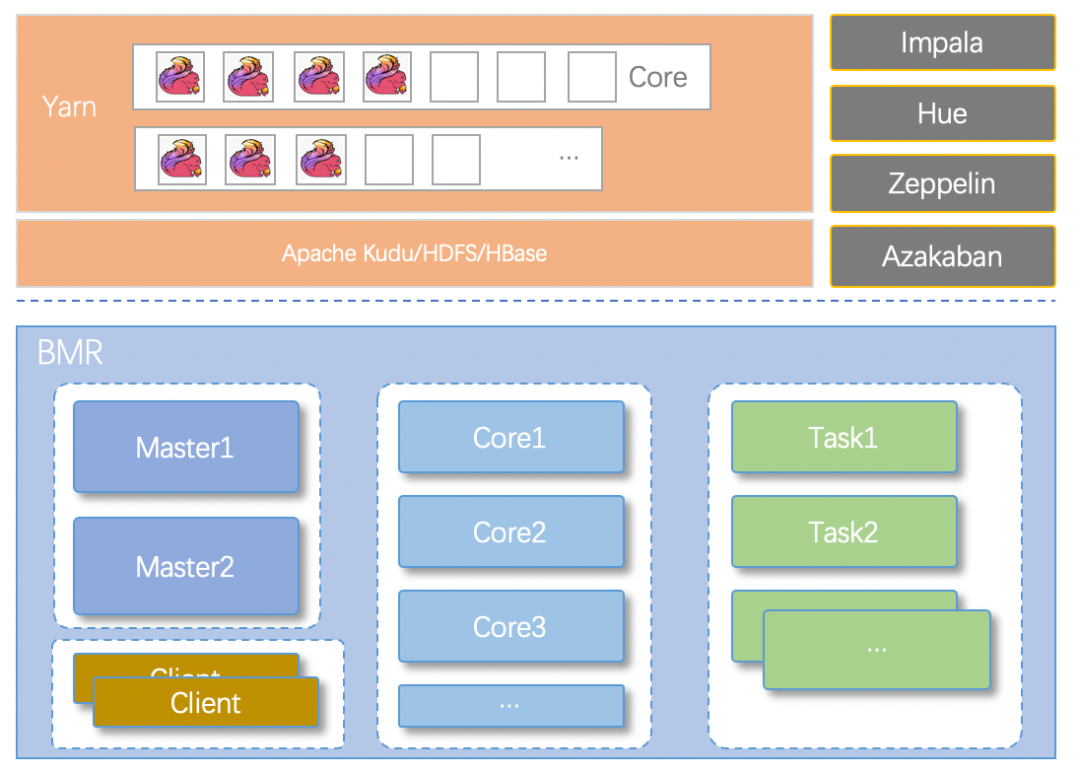
-
Master节点:集群管理节点,部署 NameNode、ResourceManager 等进程,并且做到组件故障时的自动迁移;
-
Core节点:计算及数据存储节点,部署 DataNode、NodeManager 等进程;
-
Task节点:计算节点,用来补充 core 节点的算力,部署 NodeManger 等进程,该节点一般不用来存储数据,支持按需动态扩容和缩容操作;
-
Client节点:独立的集群管控节点及作业提交节点。
4.3.5.2 全链监控

-
日志采集:基于爱番番贡献给 Skywalking 的 Satellite 收集全链路服务日志,支持了 K8s 下微服务的日志收集,也支持了 Flink Job 的日志采集,做到一个日志平台,汇集全链服务日志。然后通过 Grafana 进行日志查询、分析; -
服务指标采集:我们通过 PushGateway 将各个微服务,Apache Flink、Impala、Kudu等算存集群指标统一采集到爱番番 Prometheus,做到服务实时监控&报警。 -
全链路延时监控:我们也通过 Skywalking Satellite 采集 RT-CDP 全链路的数据埋点,然后通过自研的打点分析平台进行延时分析,做到全链路数据延时可视化和阈值报警。
五、平台成果
5.1 资产数据化
-
多方化:集成一方数据,打通二方数据,利用三方数据,通过多方数据打通,实现更精准、深度的客户洞察。 -
数字化:通过自定义属性、标签、模型属性等将客户信息全面数字化管理。 -
安全化:通过数据加密、隐私计算、多方计算实现数据安全和隐私保护,保护企业数据资产。 -
智能化:通过智能模型不断丰富客户画像,服务更多营销场景。
5.2 高效支撑业务
-
丰富的自定义 API,用于可以自定义 Schema、属性、事件等不同场景的数据上报结构; -
支持了身份类型自定义,方便企业根据自身数据特定指定潜客标识; -
针对不同企业的不同结构的数据可以做到零开发成本接入。

5.3 架构先进
5.3.1 实时高吞吐
-
Identity Service 做到数十万 QPS 的关系查询,支持上万 TPS 的身份裂变。
-
实时计算做到了数十万 TPS 的实时处理、实时持久化,做到毫秒级延迟。
-
支持企业海量数据、高并发下毫秒级实时分析。
-
真正基于实时流数据实现规则判断,支撑了私域打标、实时规则判断、圈群等多个实时业务场景,让营销毫秒触达。
5.3.2 高扩展性
-
基于云原生+Nebula 搭建了可动态伸缩的图存储集群;
-
借助百度云原生 CCE、BMR 等云上能力,搭建了存算分离的弹性伸缩的存算集群;
-
计算集群动态伸缩,节约企业资源成本。
5.3.3 高稳定性
六、未来展望
-
平台目前在业务支撑上已经具备了比较好的定义能力。下一步将结合重点服务的企业行业,内置更多行业业务对象,进一步简化企业数据接入成本。
-
在 B2B2C 数据模型上做更多业务尝试,更好服务 ToB 企业。
-
RT-CDP 已经为企业提供了智能化的潜客评分能力,支持企业灵活定义评分规则。在AI时代,我们将继续丰富更多的AI模型来帮助企业管理、洞察、营销客户。
-
目前 Flink 作业还是基于Yarn管理资源、基于 API、脚本方式流程化操作(比如涉及到 CK 的操作)作业监控通过如流、短信、电话报警。后续我们将作业管理、运维上做更多尝试,比如基于 K8s 管理 Flink 作业、结合如流的 Webhook 能力完善作业运维能力等。
-
在流数据驱动下,数据处理机制的变化让数据治理、数据检查变得更有挑战。为了提供更可靠的数据服务,还有很多工作要做。
-
国内互联网公司已经有不少数据湖技术实践案例,确实可以解决一些原有数仓架构的痛点,比如数据不支持更新操作,无法做到准实时的数据查询。我们目前也在做 Flink 和 Iceberg/Hudi 集成的一些尝试,后续会逐步落地。
– 作者介绍 –
Jimmy:带着团队为爱番番奔走的资深工程师
本文为从大数据到人工智能博主「jellyfin」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/bigdata/doris/doris-usage/4879/