Apache Flink 持续保持高速发展,是 Apache 最活跃的社区之一。Flink 1.16 共有 240 多个 Contributor 热情参与,共完成了 19 个 FLIP [ 1] 和 1100 多个 issue,给社区带来非常多振奋人心的功能。 Flink 已经是流计算领域的领跑者,流批一体的概念逐渐得到大家的认可,并在越来越多的公司成功落地。之前的流批一体更强调统一的 API 和统一的计算框架。今年,在此基础上,Flink 推出了 Streaming Warehouse [ 2 ] ,进一步升级了流批一体的概念:真正完成了流批一体的计算和流批一体的存储的融合,从而实现流批一体的实时化分析。 在 1.16 版本里,Flink 社区对流、批都完成了众多改进:
在流处理方面,也完成了很多重大改进:
Changelog State Backend 可以为用户提供秒级甚至毫秒级 Checkpoint,从而大幅提升容错体验,同时为事务性 Sink 作业提供更小的端到端延迟体验。
维表关联在流处理中广泛被使用,引入了通用的缓存机制加快维表查询速度,引入了可配置的异步模式提升维表查询吞吐,引入可重试查询机制解决维表延迟更新问题。这些功能都非常实用,解决了用户经常抱怨的痛点,支持了更丰富的场景。
从 Flink SQL 诞生第一天就存在一些非确定性操作可能导致用户作业出现错误结果或作业运行异常,这给用户带来了极大的困扰。1.16 里我们花了很多大精力解决了大部分问题,未来还会持续改进。
随着流批一体的进一步 完善和 Flink Table Store 的不断迭代(0.2版本已 发布 [3] ),Flink 社区正一步一步推动 Streaming Warehouse 从概念变为现实并走向成熟 。
流式数仓(Streaming Warehouse)更准确地说,其实是 “make data warehouse streaming”,就是让整个数仓所有分层的数据全部实时地流动起来,从而实现一个具备端到端实时性的纯流服务(Streaming Service),并且用一套统一 API 和计算框架来处理和分析所有流动中的数据。想了解更多内容请参阅 文章 [4] 。 得益于我们在流处理的长期投资,流处理已经成为流计算领域的领导者。在批处理上,我们也投入更多的精力,使其成为一个优秀的批处理引擎。流批处理统一的整体体验也将会更加顺畅。
SQL Gateway 从各个渠道反馈中了解到, SQL Gateway [5] 一直是用户非常期待的功能,尤其是对批用户。1.16 里,该功能终于完成(设计见 FLIP-91 [6] )。SQL Gateway 是对 SQL Client 的扩展和增强,支持多租户和插件式 API 协议(Endpoint),解决了 SQL Client 只能服务单用户并且不能对接外部服务或组件的问题。当前 SQL Gateway 已支持 REST API 和 HiveServer2 协议,用户可以通过 cURL,Postman,各种编程语言的 HTTP 客户端链接到 SQL Gateway 提交流作业、批作业,甚至 OLAP 作业。对于 HiveServer2 协议,请参考“Hive 语法兼容”章节。
Hive 语法兼容 为了降低从 Hive 到 Flink 的迁移成本,这个版本里我们引入了 HiveServer2 协议并继续改进 Hive 语法的兼容性。
HiveServer2 协议 [7] 允许用户使用 Hive JDBC/Beeline 和 SQL Gateway 进行交互,Hive 生态(DBeaver, Apache Superset, Apache DolphinScheduler, and Apache Zeppelin)也因此很容易迁移到 Flink。当用户使用 HiveServer2 协议连接 SQL Gateway,SQL Gateway 会自动注册 Hive Catalog,自动切换到 Hive 方言,自动使用批处理模式提交作业,用户可以得到和直接使用 HiveServer2 一样的体验。
Hive 语法 [8] 已经是大数据处理的事实标准,Flink 完善了对 Hive 语法的兼容,增加了对 Hive 若干生产中常用语法的支持。通过对 Hive 语法的兼容,可以帮助用户将已有的 Hive SQL 任务迁移到 Flink,并且方便熟悉 Hive 语法的用户使用 Hive 语法编写 SQL 以查询注册进 Flink 中的表。到目前为止,基于 Hive qtest 测试集(包含12K 个 SQL 案例),Hive 2.3 版本的查询兼容性已达到 94.1%,如果排除 ACID 的查询语句,则已达到 97.3%。
Join Hint Hint 一直是业界用来干预执行计划以改善优化器缺点的通用解决方案。Join 作为批作业中最广泛使用的算子,Flink 支持多种 Join 策略。统计信息缺失或优化器的代价模型不完善都会导致选出错误 Join 策略,从而导致作业运行慢甚至有运行失败的风险。用户通过指定 Join Hint [9] ,让优化器尽可能选择用户指定的 Join 策略,从而避免优化器的各种不足,以确保批作业的生产可用性。
自适应 Hash Join 对于批作业而言,数据倾斜是非常常见的,而此时使用 HashJoin 可能运行失败,这是非常糟糕的体验。为了解决该问题,我们引入了自适应的 HashJoin:Join 算子运行时一旦 HashJoin 运行失败,可以自动回退到 SortMergeJoin,并且是 Task 粒度。通过该机制可确保 HashJoin 算子始终成功,从而提高了作业的稳定性。
批处理的预测执行 为了解决问题机器导致批作业处理慢的问题,Flink 1.16 引入了预测执行。问题机器是指存在硬件问题、突发 I/O 繁忙或 CPU 负载高等问题的机器,这些问题可能会使得运行在该机器上的任务比其他机器上的任务要慢得多,从而影响批处理作业的整体执行时间。 当启用预测执行时,Flink 将持续检测慢任务。一旦检测到慢任务,该任务所在的机器将被识别为问题机器,并通过黑名单机制( FLIP-224 [10] )被加黑。调度器将为慢任务创建新的执行实例并将它们部署到未被加黑的节点,同时现有执行实例也将继续运行。新的执行实例和老的执行实例将处理相同的输入数据并产出相同的结果数据。一旦任何执行实例率先完成,它将被视为该任务的唯一完成执行实例,并且该任务的其余执行实例都将被取消。 大多数现有 Source 都可以使用预测执行 ( FLIP-245 [11] )。只有当一个 Source 使用了 SourceEvent 时,它必须额外实现 SupportsHandleExecutionAttemptSourceEvent 接口以支持预测执行。目前 Sink 尚不支持预测执行,因此预测执行不会在 Sink 上发生。 我们也改进了 Web UI 和 REST API ( FLIP-249 [12] ) ,以显示任务的多个执行实例和被加黑的 TaskManager。
混合 Shuffle 模式 我们为批处理引入了一种新的 混合 Shuffle [13] 模式。它结合了 Blocking Shuffle 和 Pipeline Shuffle(主要用于流式处理)的优点:
与 Blocking Shuffle 一样,它不要求上下游任务同时运行,这允许使用很少的资源执行作业。
与 Pipeline Shuffle 一样,它不要求上游任务完成后才执行下游任务,这在给定足够资源情况下减少了作业的整体执行时间。
用户可以选择不同的落盘策略,以满足减少数据落盘或是降低任务重启代价的不同需求。
Blocking shuffle 进一步改进 在这个版本中,我们进一步改进了 Blocking Shuffle 的可用性和性能,包括自适应网络缓冲区分配、顺序 IO 优化和结果分区重用,允许多个消费者节点重用同一个物理结果分区,以减少磁盘 IO 和存储空间。在 TPC-DS 10TB规模的测试中,这些优化可以实现 7% 的整体性能提升。此外,还引入了两种压缩率更高的压缩算法(LZO 和 ZSTD)。与默认的 LZ4 压缩算法相比,可以进一步减少存储空间,但要付出一些 CPU 成本。
动态分区裁剪 对于批作业,生产环境中分区表比非分区表使用更为广泛。当前 Flink 已经支持静态分区裁剪,即在优化阶段,优化器将 Filter 中的 Partition 相关的过滤条件下推到 Source Connector 中从而减少不必要的分区读取。 星形模型 [14] 是数据集市模式中最简单且使用最广泛的模式,我们发现很多用户的作业没法使用静态分区裁剪,因为分区裁剪信息在执行时才能确定,这就需要 动态分区裁剪技术 [15] ,即运行时根据其他相关表的数据确定分区裁剪信息从而 减少对分区表中无效分区的读取 。通过 TPC-DS 10TB 规模数据集的验证,该功能可提升 30% 的性能。
在 1.1 6 中,我们在 Checkpoint、SQL、Connector 和其他领域都进行了改进, 从而确保 Flink 在流计算领域继续领先。
Generalized Incremental Checkpoint Changelog State Backend 旨在令 Checkpoint 的间隔更短、更加可预测。这个版本在自身易用性上和与其他 State Backend 兼容性上做了诸多改进,使其达到生产可用。
在 Flink WebUI 上显示 Changelog 相关的配置
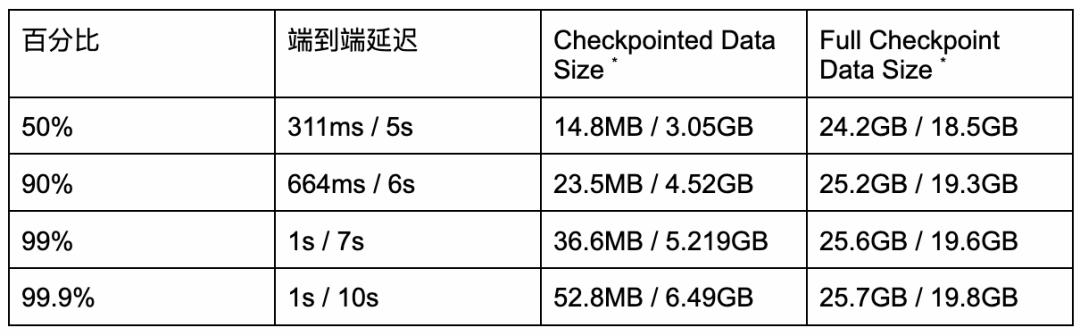
表 1: Value State 上 Changelog Enabled / Changelog Disabled 对比 (详细配置请参考 文档 [16] )
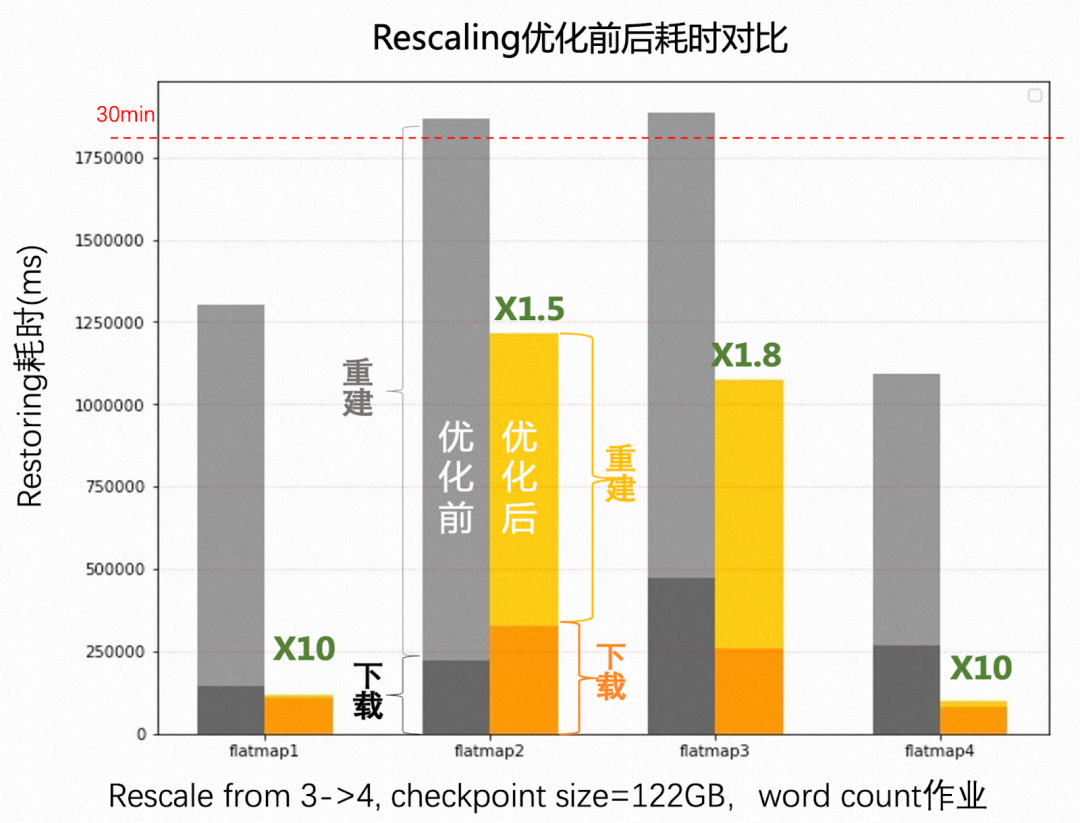
RocksDB Rescaling 改进及性能测试 对于使用 Flink 构建的云服务应用来说,Rescaling 是一种非常频繁的操作。这个版本使用了 RocksDB 的 区间删除 [17] 来优化增量 RocksDB State Backend 的 Rescaling 性能。区间删除被用来避免在 Rescaling 过程中大量的扫描和单点删除操作,对有大量的状态需要删除的扩并发来说,单个并发上的恢复速度可以 提高 2~10 倍 [18] 。 改善 State Backend 的监测体验和可用性 这个版本还改善了状态后台的监控体验和可用性。之前,RocksDB 的日志位于它自己的 DB 目录中,这使得调试 RocksDB 没那么容易。这个版本让 RocksDB 的日志默认留在 Flink 的日志目录中。新增了 RocksDB 相关的统计指标,以帮助调试 DB 级别的性能,例如,在 DB 内的总块缓存命中/失败计数。
支持透支缓冲区 透支缓冲区 [19] (Overdraft Buffers)旨在缓解反压情况下 Subtask 被阻塞的概率,可以通过设置 taskmanager.network.memory.max-overdraft-buffers-per-gate [20] 开启。 从 1.16 开始,一个 Flink 的 Subtask 可以申请 5 个(默认)额外的透支缓冲区。透支缓冲区会轻微地增加作业的内存使用量,但可以极大地减少 Checkpoint 的间隔,特别是在开启 Unaligned Checkpoint 情况下。只有当前 Subtask 被下游 Subtasks 反压且当前 Subtask 需要请求超过 1 个网络缓冲区(Network Buffer)才能完成当前的操作时,透支缓冲区才会被使用。更多细节可以参考 文档 [21] 。
对齐 Checkpoint 超时 这个版本更新了从 Aligned Checkpoint(AC) 切换到 Unaligned Checkpoint (UC) 的时间点。在开启 UC 的情况下,如果配置了 execution.checkpointing.aligned-checkpoint-timeout [22] , 在启动时每个 Checkpoint 仍然是 AC,但当全局 Checkpoint 持续时间超过 aligned-checkpoint-timeout 时, 如果 AC 还没完成,那么 Checkpoint 将会转换为 UC。 以前,对一个 Substask 来说,AC 到 UC 的切换需要等所有上游的 Barriers 到达后才能开始,在反压严重的情况下, 在 checkpointing-timeout [23] 过期之前,下游的 Substask 可能无法完全地收到所有 Barriers,从而导致 Checkpoint 失败。 在这个版本中,如果上游 Subtask 中的 Barrier 无法在 execution.checkpointing.aligned-checkpoint-timeout [24] 内发 送到下游,Flink 会让上游的 Subtask 先切换成 UC,以把 Barrier 发送到下游,从而减少反压情况下 Checkpoint 超时的概率。更多细节可以参 考 文档 [25] 。
流计算的非确定性 Flink SQL 用户经常抱怨理解流处理的成本太高,其中一个痛点是流处理中的非确定性(而且通常不直观),它可能会导致错误的结果或异常。而这些痛点在 Flink SQL 的早期就已经存在了。 对于复杂的流作业,现在可以在运行前检测并解决潜在的正确性问题。如果问题不能完全解决,一个详细的消息可以提示用户如何调整 SQL,以避免引入非确定性问题。更多细节可以参 考 文档 [26] 。
维表增强 维表关联在流处理中被广泛使用,在 1.16 中我们为此加入了多项优化和增强:
支持了通用的缓存机制和 相关指标 [27]
通过 作业配置 [28] 查询提示 [29]
可重试的 查询机制 [30]
异步 I/O 支持重试 为 异步 I/O [31] 引入 了内置的重试机制,它对用户现有代码是透明的,可以灵活地满足用户的重试和异常处理需求。
在 Flink 1.15 中,我们引入了一种新的执行模式:“线程”模式。在该模式下,用户自定义的 Python 函数将通过 JNI 在 JVM 中执行,而不是在独立的 Python 进程中执行。但是,在 Flink 1.15 中,仅在 Table API 和 SQL 上的 Python 标量函数的执行上支持了该功能。在该版本中,我们对该功能提供了更全面的支持,在 Python DataStream API 中以及在 Table API 和 SQL 的 Python 表值函数中,也支持了该功能。 除此之外,我们还在持续补全 Python API 所缺失的最后几处功能。在这个版本中,我们对 Python DataStream API 提供了更全面的支持:支持了旁路输出、Broadcast State 等功能,并完善了对于窗口功能的支持。我们还在 Python DataStream API 中,添加了对于更多的 Connector 以及 Format 的支持,例如添加了对于 Elasticsearch、Kinesis、Pulsar、Hybrid Source 等 Connector 的支持以及对于 Orc、Parquet 等 Format 的支持。有了这些功能之后,Python API 已经基本对齐了 Java 和 Scala API 中绝大部分的重要功能,用户已经可以使用 Python 语言完成大多数类型 Flink 作业的开发。
新语法
1.16 扩展了多个 DDL 语法以帮助用户更好的使用 SQL:
USING JAR [32]
CREATE TABLE AS SELECT [33] (CTAS) 方便用户基于已有的表和查询创建新的表。
ANALYZE TABLE [34]
DataStream 中的缓存 支持通过 DataStream#cache 缓存 Transformation 的执行结果。缓存的中间结果在首次计算中间结果时才生成,以便以后的作业可以重用该结果。如果缓存丢失,原始的 Transformation 将会被重新计算以得到结果。目前该功能只在批处理模式下支持。这个功能对于 Python 中的 ML 和交互式编程非常有用。
History Server 及已完成作业的信息增强 在这个版本中,我们加强了查看已完成作业的信息的体验。
JobManager / HistoryServer WebUI 提供了详细的执行时间指标,包括任务在每个执行状态下的耗时,以及在运行过程中繁忙/空闲/反压总时间。
JobManager / HistoryServer WebUI 提供了按 Task 或者 TaskManager 维度分组的主要子任务指标的聚合。
JobManager / HistoryServer WebUI 提供了更多的环境信息,包括环境变量,JVM 选项和 Classpath。
HistoryServer 现在支持从外部日志归档服务中浏览日志,更多细节可以参考 文档 [35] 。
Protobuf 格式
Flink 现在支 持 Protocol Buffers [36] ( Protobuf) 格式,这允许您直接在 Table API 或 SQL 应用程序中使用这种格式。
为异步 Sink 引入可配置的 RateLimitingStrategy 1.15 中实现了异步 Sink,允许用户轻松实现自定义异步 Sink。这个版本里,我们对此进行扩展以支持可配置的 RateLimitingStrategy。这意味着 Sink 的实现者现在可以自定义其异步 Sink 在请求失败时的行为方式,具体行为取决于特定的 Sink。如果没有指定 RateLimitingStrategy,它将默认使用 AIMDScalingStrategy。
我们尽力的让每次版本升级都平稳,但仍有一些改动需要用户升级到1.16时对现有应用程序做出一些调整。请参考 Release Notes 获取更多的升级时需要的改动与可能的问题列表细节。 更多 Flink 相关技术问题,可扫码加入社区钉钉交流群~ Apache Flink 社区感谢对此版本做出贡献的每一位贡献者: 1996fanrui, Ada Wang, Ada Wong, Ahmed Hamdy, Aitozi, Alexander Fedulov, Alexander Preuß, Alexander Trushev, Andriy Redko, Anton Kalashnikov, Arvid Heise, Ben Augarten, Benchao Li, BiGsuw, Biao Geng, Bobby Richard, Brayno, CPS794, Cheng Pan, Chengkai Yang, Chesnay Schepler, Danny Cranmer, David N Perkins, Dawid Wysakowicz, Dian Fu, DingGeGe, EchoLee5, Etienne Chauchot, Fabian Paul, Ferenc Csaky, Francesco Guardiani, Gabor Somogyi, Gen Luo, Gyula Fora, Haizhou Zhao, Hangxiang Yu, Hao Wang, Hong Liang Teoh, Hong Teoh, Hongbo Miao, HuangXingBo, Ingo Bürk, Jacky Lau, Jane Chan, Jark Wu, Jay Li, Jia Liu, Jie Wang, Jin, Jing Ge, Jing Zhang, Jingsong Lee, Jinhu Wu, Joe Moser, Joey Pereira, Jun He, JunRuiLee, Juntao Hu, JustDoDT, Kai Chen, Krzysztof Chmielewski, Krzysztof Dziolak, Kyle Dong, LeoZhang, Levani Kokhreidze, Lihe Ma, Lijie Wang, Liu Jiangang, Luning Wang, Marios Trivyzas, Martijn Visser, MartijnVisser, Mason Chen, Matthias Pohl, Metehan Yıldırım, Michael, Mingde Peng, Mingliang Liu, Mulavar, Márton Balassi, Nie yingping, Niklas Semmler, Paul Lam, Paul Lin, Paul Zhang, PengYuan, Piotr Nowojski, Qingsheng Ren, Qishang Zhong, Ran Tao, Robert Metzger, Roc Marshal, Roman Boyko, Roman Khachatryan, Ron, Ron Cohen,Ruanshubin, Rudi Kershaw, Rufus Refactor, Ryan Skraba, Sebastian Mattheis, Sergey, Sergey Nuyanzin, Shengkai, Shubham Bansal, SmirAlex, Smirnov Alexander, SteNicholas, Steven van Rossum, Suhan Mao, Tan Yuxin, Tartarus0zm, TennyZhuang, Terry Wang, Thesharing, Thomas Weise, Timo Walther, Tom, Tony Wei, Weijie Guo, Wencong Liu, WencongLiu, Xintong Song, Xuyang, Yangze Guo, Yi Tang, Yu Chen, Yuan Huang, Yubin Li, Yufan Sheng, Yufei Zhang, Yun Gao, Yun Tang, Yuxin Tan, Zakelly, Zhanghao Chen, Zhu Zhu, Zichen Liu, Zili Sun, acquachen, bgeng777, billyrrr, bzhao, caoyu, chenlei677, chenzihao, chenzihao5, coderap, cphe, davidliu, dependabot[bot], dkkb, dusukang, empcl, eyys, fanrui, fengjiankun, fengli, fredia, gabor.g.somogyi, godfreyhe, gongzhongqiang, harker2015, hongli, huangxingbo, huweihua, jayce, jaydonzhou, jiabao.sun, kevin.cyj, kurt, lidefu, lijiewang.wlj, liliwei, lincoln lee, lincoln.lil, littleeleventhwolf, liufangqi, liujia10, liujiangang, liujingmao, liuyongvs, liuzhuang2017, longwang, lovewin99, luoyuxia, mans2singh, maosuhan, mayue.fight, mayuehappy, nieyingping, pengmide, pengmingde, polaris6, pvary, qinjunjerry, realdengziqi, root, shammon, shihong90, shuiqiangchen, slinkydeveloper, snailHumming, snuyanzin, suxinglee, sxnan, tison, trushev, tsreaper, unknown, wangfeifan, wangyang0918, wangzhiwu, wenbingshen, xiangqiao123, xuyang, yangjf2019, yangjunhan, yangsanity, yangxin, ylchou, yuchengxin, yunfengzhou-hub, yuxia Luo, yuzelin, zhangchaoming, zhangjingcun, zhangmang, zhangzhengqi3, zhaoweinan, zhengyunhong.zyh, zhenyu xing, zhouli, zhuanshenbsj1, zhuzhu.zz, zoucao, zp, 周磊, 饶紫轩,, 鲍健昕 愚鲤, 帝国阿三 [1] https://cwiki.apache.org/confluence/display/FLINK/1.16+Release [2] https://developer.aliyun.com/article/851771 [3] https://flink [4] https://developer.aliyun.com/article/851771 [5] https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/dev/table/sql-gateway/overview/ [6] https://cwiki.apache.org/confluence/display/FLINK/FLIP-91%3A+Support+SQL+Gateway [7] https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/dev/table/hive-com patibility/hiveserver2/ [8] https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/dev/table/hive-compatibility/hive-dialect/overview/ [9] https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/dev/table/sql/queries/hints/ [10] https://cwiki.apache.org/confluence/display/FLINK/FLIP-224%3A+Blocklist+Mechanism [11] https://cwiki.apache.org/confluence/display/FLINK/FLIP-245 %3A+Source+Supports+Speculative+Execution+For+Batch+Job [12] https://cwiki.apache.org/confluence/display/FLINK/FLIP-249%3A+Flink+Web+UI+Enhancement+for+Speculative+Execution [13] https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/ops/batch/batch_shuffle/ [14] https://en.wikipedia.org/wiki/Star_schema [15] https://cwiki.apache.org/confluence/display/FLINK/FLIP-248%3A+Introduce+dynamic+partition+pruning [16] https://flink-learning.org.cn/article/detail/2a107b2622171b9972293f3b062c4d52 [17] https://rocksdb.org/blog/2018/11/21/delete-range.html [18] https://github.com/apache/flink/pull/19033#issuecomment-1072267658 [19] https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/deployment/memory/network_mem_tuning/#overdraft-buffers [20] https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/deployment/config/#taskmanager-network-memory-max-overdraft-buffers-per-gate [21] https://nightlies.apache.org/flink/flink-docs-master/zh/docs/deployment/memory/network_mem_tuning/#%e9%80%8f%e6%94%af%e7%bc%93%e5%86%b2%e5%8c%baoverdraft-buffers [22] https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/config/#execution-checkpointing-aligned-checkpoint-ti meout [23] https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/config/#execution-checkpointing-timeout [24] https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/config/#execution-checkpointing-aligned-checkpoint-timeout [25] https://nightlies.apache.org/flink/flink-docs-master/zh/docs/ops/state/checkpointing_under_ backpressure/#%e5%af%b9%e9%bd%90-checkpoint-%e7%9a%84%e8%b6%85%e6%97%b6 [26] https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/table/concepts/determinism/ [27] https://cwiki.apache.org/confluence/display/FLINK/FLIP-221%3A+Abstraction+for+lookup+source+cache+and+metric [28] https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/config/#table-exec-async-lookup-output-mode [29] https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/sql/queries/hints/#2-configure-the-async-parameters [30] https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/sql/queries/hints/#3-enable-delayed-retry-strategy-for-lookup [31] https: //nightlies.apache.org/flink/flink-docs-release-1.16/docs/dev/datastream/operators/asyncio/#retry-support [32] https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/dev/table/sql/create/#create-function [33] https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/dev/table/sql/create/#as-select_statement [34] https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/dev/table/sql/analyze/ [35] https://nightlies.apache.org/flink/flink-docs-release-1.16/ zh/docs/deployment/advanced/historyserver/ [36] https://developers.google.com/protocol-buffers
https://flink-forward.org.cn/
本文为从大数据到人工智能博主「xiaozhch5」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/10666/