


sqlite 提供了一种 redo log 型事务实现,支持读写的并发,见 write-ahead log(https://sqlite.org/wal.html)。本文将介绍 wal 原理,并源码剖析 checkpoint 过程,同时讨论下 wal 使用中的一些注意点。由于 sqlite 的复杂性,会省略掉一些细节,重点放在核心流程和 wal 并发的实现。
1. wal 原理
1.1 redo log
sqlite wal 是一种简单的 redo log 事务实现,redo log 概念这里简述下。数据库事务需要满足满足 acid,其中原子性(a),即一次事务内的多个修改,要么全部提交成功要么全部提交失败,不存在部分提交到 db 的情况。 redo log 的解决思路是将修改后的日志按序先写入 log 文件(wal 文件),每个完成的事务会添加 checksum,可鉴别事务的完整性。事务写入日志文件后,即代表提交成功,读取时日志和 db 文件合并的结果构成了 db 的完整内容。同时定期 checkpoint,同步 wal 中的事务到 db 文件,使 wal 文件保持在合理的大小。日志文件持久化到磁盘后,已提交成功的事务按序 checkpoint 执行的结果都是一样的,不受 crash 和掉电的影响。
sqlite 的 wal 也是这种思路的实现,只是 sqlite 提供的是一种简化实现,同时只允许一个写者操作日志文件,日志也是 page 这种物理日志。redo log 还能将 undo log 的随机写转化为顺序写,具有更高的写入性能,这里不赘述。
想对 redo log 进一步了解,可以参考以下资料:
https://zhuanlan.zhihu.com/p/35574452
https://developer.aliyun.com/article/1009683
1.2 sqlite wal
sqlite wal 写操作不直接写入 db 主文件,而是写到“db-wal”文件(以下简称’wal’文件)的末尾。读操作时,将结合 db 主文件以及 wal 的内容返回结果。wal 模式同时具有简单的 mvvc 实现,支持文件级别的读写并发,提供了相对 delete(rollback) 模式 (undo log 事务) 更高的并发性。 具体可看图加深理解。
下图中:
-
pgx.y,x 表示当前 page 的 num,y 表示当前 page 的版本,每个提交的事务都保存当前修改后的 page 副本; -
图中 wal 中提交了两个事务,wal 中蓝色框表示一个完整事务修改的所有 page; -
wal 实际中保存的单位是 wal frame,除了修改的页面还会保存 page number checksum 等信息,这里为了突出展示了 page, 详细格式见:https://www.sqlite.org/fileformat2.html

关于写
-
写操作总是发生在 wal 文件上; -
写操作总是追加在 wal 文件末尾,由 commit 触发; -
写入 wal 文件中是原始 page 修改后的副本; -
写操作对 wal 文件的访问是独占串行的; -
事务写入只有成功落盘(写入磁盘)才算成功提交,checkpoint 前会调用 wal 文件的 fsync,保证日志提交持久性和一致性; -
没有调用 fsync 不代表日志提交一定失败,会由文件系统定期回写; -
如果 fsync 回写之前发生 crash 或系统崩溃,导致事务 2 的 pg4.2 写 wal 失败,可校验出事务 2 不完整,则 wal 中成功提交的事务只有事务 1; 如果 pg0.1 回写失败,则 wal 中没有成功提交的事务。
 关于读
关于读
-
读与写可以并发; -
每个读事务会记录 wal 文件中一个 record 点,作为它的 read mark,每个事务执行过程中 read mark 不会发生改变,新提交的事务产生的修改不会影响旧的事务。read mark 会选择事务完整提交后的位置。原始 db 文件和 wal 中 read mark 之前的记录构成了数据库的一个固定的版本记录; -
读事务读一个 page 优先读 wal 文件,没有则读原始文件; -
如果一个 page 在 wal 中有多个副本,读 read mark 前的最后一个; -
同一个 read mark 可以被多个读事务使用。
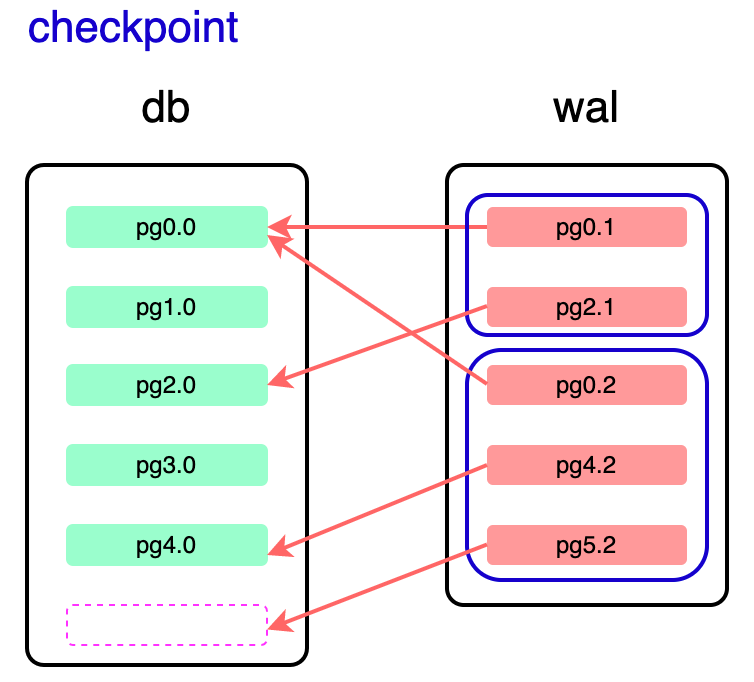
关于 checkpoint:
-
checkpoint 针对 wal 中已经成功落盘的事务,每次 checkpoint 前会执行 fsync; -
每次 checkpoint 从前到后按序回写 wal 文件中尚未提交的事务到 db; -
如果 checkpoint 中途 crash,由于事务已持久化到 wal 文件,下次启动重新按序回写 wal 中的事务即可; -
wal 中所有的事务 checkpoint 后,wal 文件会从头开始使用; -
checkpoint 并不一定都会提交 wal 中全部的事务,如果只是部分提交,下次写入还是会写入 wal 文件的末尾,wal 文件可能会变很大; -
只有 truncate 的 checkpoint 才能清理已经异常变大的 wal 文件,会 truncate 文件大小到 0。
2. wal 实现
wal 的实现大部分代码集中在 wal.c 中,从 sqlite 的架构划分应该主要算是 pager 层的实现。
https://www.sqlite.org/arch.html。wal 实现从逻辑上由 3 部分组成:
2.1 wal 和 wal-index 文件格式
文件格式定义,官方文档见:
https://www.sqlite.org/walformat.html
https://www.sqlite.org/fileformat2.html
这一层细节比较多,主要是些二进制定义。核心是 wal 格式提供了一种 page 格式的 redo log 组织格式,保证 crash 后 recover 过程满足一致性。
wal-index 文件(db-shm)只是一种对 wal 文件的快速索引,后文为了省事,也统称 wal 文件。
2.2 文件多副本抽象
即 wal 和 db 文件对外表现为一个统一的文件抽象,并提供文件级别的 mvcc,对 pager 层屏蔽 wal 细节。
由于 wal 和 db 一样都是以 pgno 的方式索引 page,按 pgno 替换就可以构造出不同版本的 b 树,比较简单。mvcc 主要通过 read lock 的 read mark 实现,前面有介绍过, 后面并发控制部分会详细举例介绍。
具体实现可看:
写入:https://github.com/sqlite/sqlite/blob/version-3.15.2/src/pager.c#L3077
读取:https://github.com/sqlite/sqlite/blob/version-3.15.2/src/wal.c#L2593
2.3 并发控制
通过文件锁保证并发操作不会损坏数据库文件,下一节详细讲解。
3. wal 下的并发
wal 支持读读、读写的并发,相比最初的 rollback journal 模式提供了更大的并发力度。但 wal 实现的是文件级别的并发,没有 mysql 表锁行锁的概念,一个 db 文件同时的并发写事务同时只能存在一个,不支持写的同时并发。checkpoint 也可能会 block 读写。
wal 并发实现上主要通过文件锁,和文件级别 mvcc 来实现文件级别的读写并发。 锁即下文源码中的 WAL_CKPT_LOCK,WAL_WRITE_LOCK 和WAL_READ_LOCK,出于简化问题考虑省略了 WAL_RECOVER_LOCK 等相关性不大的其他锁的讨论。mvcc 即通过文件多副本和 read mark 实现,后文也会详细介绍。
3.1 锁的分类和作用
官方介绍:https://www.sqlite.org/walformat.html
可看 2.3.1节 How the various locks are used
也可看下面简化分析:

3.2 锁的持有情况
数据库的访问,可以分为 3 类:读、写和checkpoint。事务对锁的持有不总是在事务一开始就持有,后文为了简化分析,会假设读写事务对锁的持有在事务开始时是已知的,并且与事务同生命周期。实际在读事务某些执行路径上也可能会持有 write lock,这里专注主线逻辑。

3.3 锁的应用
这部分可以和源码分析部分参照起来看,是整个 wal 里面相对复杂的部分,重点,需要来回反复看。
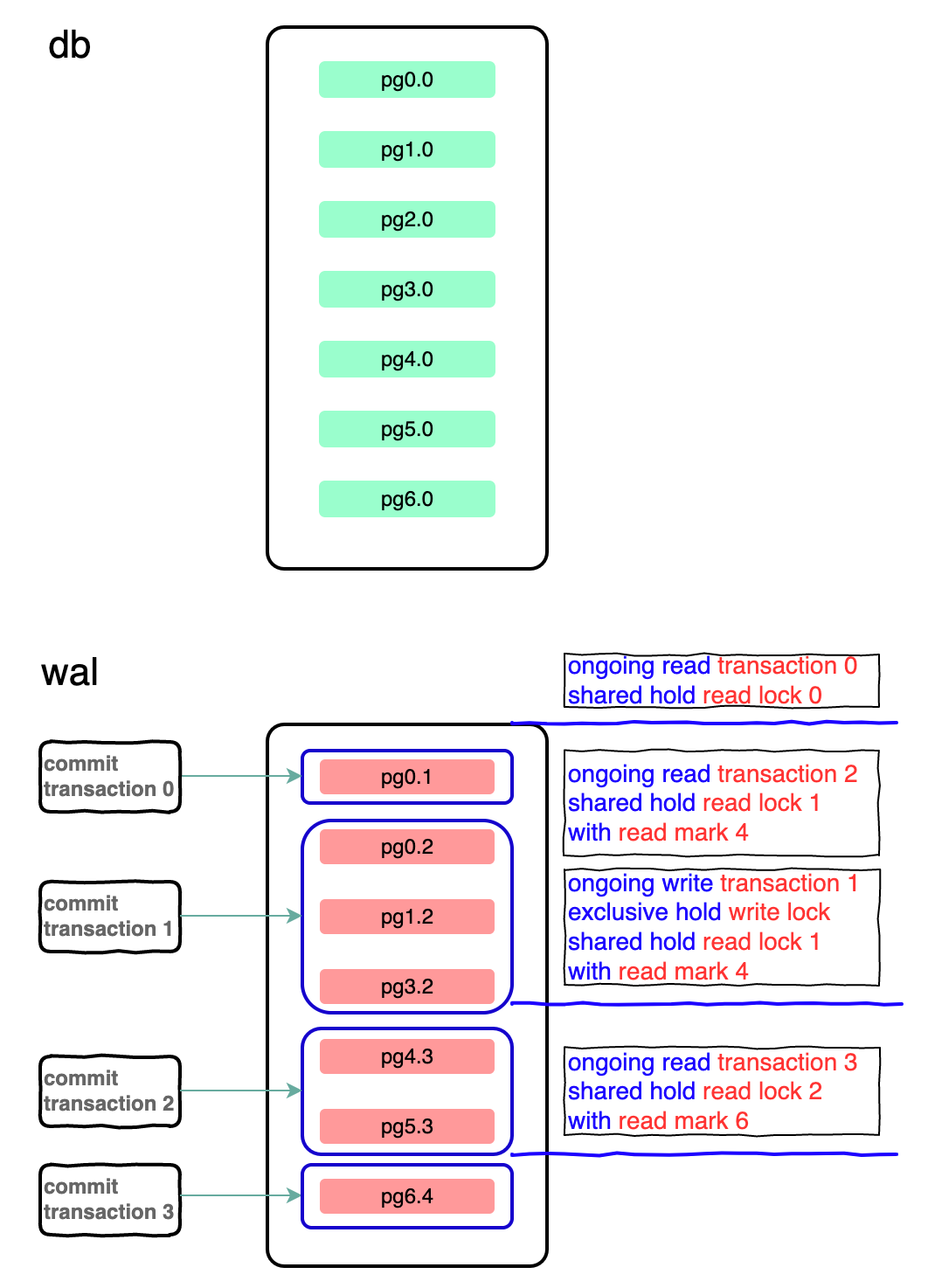
commit transaction:表示已经提交但没有 checkpoint 的事务,蓝框中表示事务修改的页面。
ongoing transition : 表示正在进行中的事务,同时也表示一个活跃的数据库连接,蓝线表示 read mark 的位置。
pgx.y: 表示 page 的页号和版本。
3.3.1 读写
如图可知:
-
wal文件存在 4 个已经提交的事务
第一个事务修改了 page0,第二个事务修改了 page0、1、3,依此类推。
-
当前数据库上存在 4 个活跃的连接,包括 3 个读事务和 1 个写事务; -
写事务独占了 WAL_WRITE_LOCK,所以此时不能再发起一个写事务; -
写事务占有 1(4)读锁,所以写事务读取不到 read mark 4 之后的修改,只能读取 read mark 4 之前的修改。即写事务读取 page4 时不能读取到 page4.3,只能读取 page4.0; -
3 个读事务占有 0(0),1(4),2(5)三个读锁,read mark 只能在事务结束的位置,不会处于中间 page 的位置; -
后续如果发起一个读事务,会占有读锁 3(7)。理论上可以发起任意多个读请求,读锁可以被 sqlite 连接共享。
3.3.2 checkpoint
这部分要和源码分析结合,如果此时发起 checkpoint。
-
由于事务 0 持有 read lock 0,read mark 0,计算 mxSafeFrame 为 0,不会发生 checkpoint。
如果事务 0 结束后发起 checkpoint。
-
由于写事务存在,不能发起非 passive 的 checkpoint。
如果事务 1 结束后执行 checkpoint。
-
计算 mxSafeFrame 等于 4,会提交前 4 个 page,没有完全提交,wal 文件不会重新利用,新的写入还是会写入 commit transaction3 之后。
如果所有事务结束后执行 checkpoint。
-
提交所有页面,下次写入 wal 文件头部。
4. checkpoint 源码分析
源码对应 sqlite 3.15.2,通过直接调用 checkpoint 观察整个过程。
https://github.com/sqlite/sqlite/tree/version-3.15.2/src
4.1 调用链路
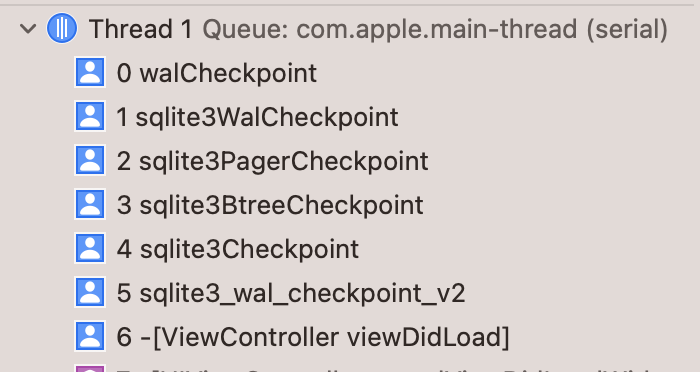
4.2 sqlite3_wal_checkpoint_v2
https://github.com/sqlite/sqlite/blob/version-3.15.2/src/main.c#L2065
主要是加锁和一些参数校验。
4.3 sqlite3Checkpoint
https://github.com/sqlite/sqlite/blob/version-3.15.2/src/main.c#L2146
ndb 上循环 checkpoint,大多数时候只有一个 db 文件。
4.4 sqlite3BtreeCheckpoint
https://github.com/sqlite/sqlite/blob/version-3.15.2/src/btree.c#L9472
检查 btree 是否 locked,也是前置检查逻辑。
4.5 sqlite3PagerCheckpoint
https://github.com/sqlite/sqlite/blob/version-3.15.2/src/pager.c#L7198
也是前置的处理逻辑。不过有个和 checkpoint 逻辑有关的。
/* 只在非SQLITE_CHECKPOINT_PASSIVE模式时设置xBusyHandler
* 即SQLITE_CHECKPOINT_PASSIVE时如果获取不到锁,立即返回,不进行等待并retry
*/
if( pPager->pWal ){
rc = sqlite3WalCheckpoint(pPager->pWal, db, eMode,
(eMode==SQLITE_CHECKPOINT_PASSIVE ? 0 : pPager->xBusyHandler),
pPager->pBusyHandlerArg,
pPager->walSyncFlags, pPager->pageSize, (u8 *)pPager->pTmpSpace,
pnLog, pnCkpt
);
}
4.6 sqlite3WalCheckpoint
https://github.com/sqlite/sqlite/blob/version-3.15.2/src/wal.c#L3192
int sqlite3WalCheckpoint(
Wal *pWal, /* Wal connection */
int eMode, /* PASSIVE, FULL, RESTART, or TRUNCATE */
int (*xBusy)(void*), /* Function to call when busy */
void *pBusyArg, /* Context argument for xBusyHandler */
int sync_flags, /* Flags to sync db file with (or 0) */
int nBuf, /* Size of temporary buffer */
u8 *zBuf, /* Temporary buffer to use */
int *pnLog, /* OUT: Number of frames in WAL */
int *pnCkpt /* OUT: Number of backfilled frames in WAL */
){
int rc; /* Return code */
int isChanged = 0; /* True if a new wal-index header is loaded */
int eMode2 = eMode; /* Mode to pass to walCheckpoint() */
int (*xBusy2)(void*) = xBusy; /* Busy handler for eMode2 */
assert( pWal->ckptLock==0 );
assert( pWal->writeLock==0 );
/* EVIDENCE-OF: R-62920-47450 The busy-handler callback is never invoked
** in the SQLITE_CHECKPOINT_PASSIVE mode. */
assert( eMode!=SQLITE_CHECKPOINT_PASSIVE || xBusy==0 );
if( pWal->readOnly ) return SQLITE_READONLY;
WALTRACE(("WAL%p: checkpoint beginsn", pWal));
/* IMPLEMENTATION-OF: R-62028-47212 All calls obtain an exclusive
** "checkpoint" lock on the database file. */
// 独占获取WAL_CKPT_LOCK锁
rc = walLockExclusive(pWal, WAL_CKPT_LOCK, 1);
if( rc ){
/* EVIDENCE-OF: R-10421-19736 If any other process is running a
** checkpoint operation at the same time, the lock cannot be obtained and
** SQLITE_BUSY is returned.
** EVIDENCE-OF: R-53820-33897 Even if there is a busy-handler configured,
** it will not be invoked in this case.
*/
testcase( rc==SQLITE_BUSY );
testcase( xBusy!=0 );
return rc;
}
pWal->ckptLock = 1;
/* IMPLEMENTATION-OF: R-59782-36818 The SQLITE_CHECKPOINT_FULL, RESTART and
** TRUNCATE modes also obtain the exclusive "writer" lock on the database
** file.
**
** EVIDENCE-OF: R-60642-04082 If the writer lock cannot be obtained
** immediately, and a busy-handler is configured, it is invoked and the
** writer lock retried until either the busy-handler returns 0 or the
** lock is successfully obtained.
*/
// 非SQLITE_CHECKPOINT_PASSIVE时,独占获取WAL_WRITE_LOCK锁,并进行busy retry
if( eMode!=SQLITE_CHECKPOINT_PASSIVE ){
rc = walBusyLock(pWal, xBusy, pBusyArg, WAL_WRITE_LOCK, 1);
if( rc==SQLITE_OK ){
pWal->writeLock = 1;
}else if( rc==SQLITE_BUSY ){
eMode2 = SQLITE_CHECKPOINT_PASSIVE;
xBusy2 = 0;
rc = SQLITE_OK;
}
}
//如果wal-index显示db有变化,unfetch db文件,和主线逻辑关系不大
/* Read the wal-index header. */
if( rc==SQLITE_OK ){
rc = walIndexReadHdr(pWal, &isChanged);
if( isChanged && pWal->pDbFd->pMethods->iVersion>=3 ){
sqlite3OsUnfetch(pWal->pDbFd, 0, 0);
}
}
/* Copy data from the log to the database file. */
if( rc==SQLITE_OK ){
if( pWal->hdr.mxFrame && walPagesize(pWal)!=nBuf ){
rc = SQLITE_CORRUPT_BKPT;
}else{
// checkpoint
rc = walCheckpoint(pWal, eMode2, xBusy2, pBusyArg, sync_flags, zBuf);
}
/* If no error occurred, set the output variables. */
if( rc==SQLITE_OK || rc==SQLITE_BUSY ){
if( pnLog ) *pnLog = (int)pWal->hdr.mxFrame;
if( pnCkpt ) *pnCkpt = (int)(walCkptInfo(pWal)->nBackfill);
}
}
// release wal index,非主线逻辑
if( isChanged ){
/* If a new wal-index header was loaded before the checkpoint was
** performed, then the pager-cache associated with pWal is now
** out of date. So zero the cached wal-index header to ensure that
** next time the pager opens a snapshot on this database it knows that
** the cache needs to be reset.
*/
memset(&pWal->hdr, 0, sizeof(WalIndexHdr));
}
// 释放锁,返回
/* Release the locks. */
sqlite3WalEndWriteTransaction(pWal);
walUnlockExclusive(pWal, WAL_CKPT_LOCK, 1);
pWal->ckptLock = 0;
WALTRACE(("WAL%p: checkpoint %sn", pWal, rc ? "failed" : "ok"));
return (rc==SQLITE_OK && eMode!=eMode2 ? SQLITE_BUSY : rc);
}
4.7 walCheckpoint
https://github.com/sqlite/sqlite/blob/version-3.15.2/src/wal.c#L1724
static int walCheckpoint(
Wal *pWal, /* Wal connection */
int eMode, /* One of PASSIVE, FULL or RESTART */
int (*xBusy)(void*), /* Function to call when busy */
void *pBusyArg, /* Context argument for xBusyHandler */
int sync_flags, /* Flags for OsSync() (or 0) */
u8 *zBuf /* Temporary buffer to use */
){
int rc = SQLITE_OK; /* Return code */
int szPage; /* Database page-size */
WalIterator *pIter = 0; /* Wal iterator context */
u32 iDbpage = 0; /* Next database page to write */
u32 iFrame = 0; /* Wal frame containing data for iDbpage */
u32 mxSafeFrame; /* Max frame that can be backfilled */
u32 mxPage; /* Max database page to write */
int i; /* Loop counter */
volatile WalCkptInfo *pInfo; /* The checkpoint status information */
szPage = walPagesize(pWal);
testcase( szPage32768 );
testcase( szPage>=65536 );
pInfo = walCkptInfo(pWal);
if( pInfo->nBackfillhdr.mxFrame ){
/* Allocate the iterator */
rc = walIteratorInit(pWal, &pIter);
if( rc!=SQLITE_OK ){
return rc;
}
assert( pIter );
/* EVIDENCE-OF: R-62920-47450 The busy-handler callback is never invoked
** in the SQLITE_CHECKPOINT_PASSIVE mode. */
assert( eMode!=SQLITE_CHECKPOINT_PASSIVE || xBusy==0 );
/* Compute in mxSafeFrame the index of the last frame of the WAL that is
** safe to write into the database. Frames beyond mxSafeFrame might
** overwrite database pages that are in use by active readers and thus
** cannot be backfilled from the WAL.
*/
mxSafeFrame = pWal->hdr.mxFrame;
mxPage = pWal->hdr.nPage;
/* 计算mxSafeFrame
* 会尝试独占的获取aReadMark锁,如果获取到,则代表原先持有对应aReadMark锁的事务已经结束。
* 会不断的用busy rerty逻辑等待对应的读锁释放。
* 如果对应事物一直没有释放aReadMark锁,最终的 mxSafeFrame = MIN(unfinished_aReadMarks)
*/
for(i=1; i /* Thread-sanitizer reports that the following is an unsafe read,
** as some other thread may be in the process of updating the value
** of the aReadMark[] slot. The assumption here is that if that is
** happening, the other client may only be increasing the value,
** not decreasing it. So assuming either that either the "old" or
** "new" version of the value is read, and not some arbitrary value
** that would never be written by a real client, things are still
** safe. */
u32 y = pInfo->aReadMark[i];
if( mxSafeFrame>y ){
assert( yhdr.mxFrame );
// 尝试获取 WAL_READ_LOCK(i)锁,并进行忙等待
rc = walBusyLock(pWal, xBusy, pBusyArg, WAL_READ_LOCK(i), 1);
if( rc==SQLITE_OK ){
// 成功获取 WAL_READ_LOCK(i)锁,设置为READMARK_NOT_USED;i==1,是个treak,不影响主流程
pInfo->aReadMark[i] = (i==1 ? mxSafeFrame : READMARK_NOT_USED);
walUnlockExclusive(pWal, WAL_READ_LOCK(i), 1);
}else if( rc==SQLITE_BUSY ){
// 一直没有获取对应WAL_READ_LOCK(i)锁,设置mxSafeFrame为y
mxSafeFrame = y;
xBusy = 0;
}else{
goto walcheckpoint_out;
}
}
}
// 开始从wal文件写回db文件,此时独占的持有WAL_READ_LOCK(0)
if( pInfo->nBackfill && (rc = walBusyLock(pWal, xBusy, pBusyArg, WAL_READ_LOCK(0),1))==SQLITE_OK
){
i64 nSize; /* Current size of database file */
u32 nBackfill = pInfo->nBackfill;
pInfo->nBackfillAttempted = mxSafeFrame;
/* Sync the WAL to disk */
if( sync_flags ){
rc = sqlite3OsSync(pWal->pWalFd, sync_flags);
}
/* If the database may grow as a result of this checkpoint, hint
** about the eventual size of the db file to the VFS layer.
*/
if( rc==SQLITE_OK ){
i64 nReq = ((i64)mxPage * szPage);
rc = sqlite3OsFileSize(pWal->pDbFd, &nSize);
if( rc==SQLITE_OK && nSize sqlite3OsFileControlHint(pWal->pDbFd, SQLITE_FCNTL_SIZE_HINT, &nReq);
}
}
// 逻辑比较简单,遍历并回写
/* Iterate through the contents of the WAL, copying data to the db file */
while( rc==SQLITE_OK && 0==walIteratorNext(pIter, &iDbpage, &iFrame) ){
i64 iOffset;
assert( walFramePgno(pWal, iFrame)==iDbpage );
if( iFramemxSafeFrame || iDbpage>mxPage ){
continue;
}
iOffset = walFrameOffset(iFrame, szPage) + WAL_FRAME_HDRSIZE;
/* testcase( IS_BIG_INT(iOffset) ); // requires a 4GiB WAL file */
rc = sqlite3OsRead(pWal->pWalFd, zBuf, szPage, iOffset);
if( rc!=SQLITE_OK ) break;
iOffset = (iDbpage-1)*(i64)szPage;
testcase( IS_BIG_INT(iOffset) );
rc = sqlite3OsWrite(pWal->pDbFd, zBuf, szPage, iOffset);
if( rc!=SQLITE_OK ) break;
}
/* If work was actually accomplished... */
if( rc==SQLITE_OK ){
if( mxSafeFrame==walIndexHdr(pWal)->mxFrame ){
i64 szDb = pWal->hdr.nPage*(i64)szPage;
testcase( IS_BIG_INT(szDb) );
rc = sqlite3OsTruncate(pWal->pDbFd, szDb);
if( rc==SQLITE_OK && sync_flags ){
rc = sqlite3OsSync(pWal->pDbFd, sync_flags);
}
}
if( rc==SQLITE_OK ){
/* 更新nBackfill为已经checkpoint的部分
* nBackfill记录当前已经checkpoint的部分
*/
pInfo->nBackfill = mxSafeFrame;
}
}
/* Release the reader lock held while backfilling */
// 释放 WAL_READ_LOCK(0)
walUnlockExclusive(pWal, WAL_READ_LOCK(0), 1);
}
if( rc==SQLITE_BUSY ){
/* Reset the return code so as not to report a checkpoint failure
** just because there are active readers. */
rc = SQLITE_OK;
}
}
/* If this is an SQLITE_CHECKPOINT_RESTART or TRUNCATE operation, and the
** entire wal file has been copied into the database file, then block
** until all readers have finished using the wal file. This ensures that
** the next process to write to the database restarts the wal file.
*/
// 非passive的checkpoint的区别都在这里
if( rc==SQLITE_OK && eMode!=SQLITE_CHECKPOINT_PASSIVE ){
assert( pWal->writeLock );
if( pInfo->nBackfillhdr.mxFrame ){
// 没有全部checkpoint
rc = SQLITE_BUSY;
}else if( eMode>=SQLITE_CHECKPOINT_RESTART ){
// RESTART or TRUNCATE
u32 salt1;
sqlite3_randomness(4, &salt1);
assert( pInfo->nBackfill==pWal->hdr.mxFrame );
// 获取所有读锁, 保证下一个事物能够重新开始restart,即循环利用wal文件
rc = walBusyLock(pWal, xBusy, pBusyArg, WAL_READ_LOCK(1), WAL_NREADER-1);
if( rc==SQLITE_OK ){
if( eMode==SQLITE_CHECKPOINT_TRUNCATE ){
/* IMPLEMENTATION-OF: R-44699-57140 This mode works the same way as
** SQLITE_CHECKPOINT_RESTART with the addition that it also
** truncates the log file to zero bytes just prior to a
** successful return.
**
** In theory, it might be safe to do this without updating the
** wal-index header in shared memory, as all subsequent reader or
** writer clients should see that the entire log file has been
** checkpointed and behave accordingly. This seems unsafe though,
** as it would leave the system in a state where the contents of
** the wal-index header do not match the contents of the
** file-system. To avoid this, update the wal-index header to
** indicate that the log file contains zero valid frames. */
walRestartHdr(pWal, salt1);
// Truncate wal文件
rc = sqlite3OsTruncate(pWal->pWalFd, 0);
}
walUnlockExclusive(pWal, WAL_READ_LOCK(1), WAL_NREADER-1);
}
}
}
walcheckpoint_out:
walIteratorFree(pIter);
return rc;
}
5. 常见问题
5.1 checkpoint 何时触发
-
手动调用 checkpoint 触发; -
通过 sql 语句 PRAGMA wal_checkpoint 触发; -
sqlite 官方默认的 checkpoint 阈值是 1000 page,即当 wal 文件达到 1000 page 大小时,写操作的线程在完成写操作后同步进行 checkpoint 操作; -
当最后一个连接 close 时触发。
5.2 checkpoint 四种 mode 的区别
-
passive 不会加写锁,也就是不会 block 写操作; -
其他三种 mode 在回写 db 结束之前的逻辑都是一样。区别是 restart 会尝试再次独占获取读锁,保证 restart 型的 checkpoint 正常结束后,下一个发起的事务会从头开始循环利用 wal 文件。truncate 模式更近一步会 truncate wal 文件。
5.3 wal 下读写和 checkpoint 的并发性
可看看上面不同操作对锁的持有情况:
-
读和读可以同时进行; -
读和写可以同时进行; -
checkpoint 和读事务也存在很大程度的并发,checkpoint 对读锁持有都是间歇性的,理论上都是耗时很短。仔细观察上面的源码分析部分,虽然会周期性持有读锁,基本上是等待读事务释放读锁,在真正耗时的 io 操作回写 wal 日志到 db 的过程中,还是可以发起读事务的。这种实现 checkpoint 对读存在着某种避让,读操作过于激进,会导致 checkpoint 饥饿,极端点会导致 wal 文件异常大; -
passive checkpoint 和写事务,理论上也是可以并发; -
非passive checkpoint 和写事务,理论上不可以并发。
5.4 wal 文件巨大的原因 & 如何解决
5.4.1 原因
wal 文件提供的操作模型非常简单,只有在一次完整的 checkpoint 后才会重头开始循环利用 wal 文件,如果 checkpoint 一直没有提交当前的 wal 文件中所有更新,会导致 wal 文件无限增大。同时只有在 truncate 模式 checkpoint 才会缩减 wal 文件。
大概有以下原因会导致 wal 不能完全提交,核心都是 checkpoint 竞争不到锁。
-
非 passive 模式 checkpoint,需要获取 write lock,但获取不到; -
passive 模式 checkpoint 过程中,有并发的写操作,导致 wal 中有未提交的日志; -
checkpoint 没能及时获取所以读锁。
在 checkpoint 中不能如预料中的获得锁,主要有两种可能:
-
事务耗时很长,导致锁迟迟不能释放; -
数据连接中存在锁丢失的情况,导致 checkpoint 永远不能获取到需求的锁; -
数据库连接过多,导致 checkpoint 过程中竞争不到锁。
5.4.2 解决方案
综上要解决 wal 无限增大主要有:
-
尽量把无关代码移除事务,保证事务只做数据库相关的操作; -
检查代码,避免出现锁丢失的情况; -
读写操作适当退避,保证 checkpoint 有机会完全提交,而不总是部分提交。
本文转载自 FD 字节跳动技术团队,原文链接:https://mp.weixin.qq.com/s/E6ueX3TKw1qD10pHtifXEA。