


来源丨网络
1、项目背景
2、数据集介绍

3、数据清洗
# 导入python相关模块
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from datetime import datetime
plt.style.use('ggplot')
%matplotlib inline
# 设置中文编码和负号的正常显示
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# 读取数据,数据集较大,如果计算机读取内存不够用,可以尝试kaggle比赛
# 中的reduce_mem_usage函数,附在文末,主要原理是把int64/float64
# 类型的数值用更小的int(float)32/16/8来搞定
user_action = pd.read_csv('jdata_action.csv')
# 因数据集过大,本文截取'2018-03-30'至'2018-04-15'之间的数据完成本次分析
# 注:仅4月份的数据包含加购物车行为,即type == 5
user_data = user_action[(user_action['action_time'] > '2018-03-30') & (user_action['action_time'] '2018-04-15')]
# 存至本地备用
user_data.to_csv('user_data.csv',sep=',')
# 查看原始数据各字段类型
behavior = pd.read_csv('user_data.csv', index_col=0)
behavior[:10]
user_id sku_id action_time module_id type
17 1455298 208441 2018-04-11 15:21:43 6190659 1
18 1455298 334318 2018-04-11 15:14:54 6190659 1
19 1455298 237755 2018-04-11 15:14:13 6190659 1
20 1455298 6422 2018-04-11 15:22:25 6190659 1
21 1455298 268566 2018-04-11 15:14:26 6190659 1
22 1455298 115915 2018-04-11 15:13:35 6190659 1
23 1455298 208254 2018-04-11 15:22:16 6190659 1
24 1455298 177209 2018-04-14 14:09:59 6628254 1
25 1455298 71793 2018-04-14 14:10:29 6628254 1
26 1455298 141950 2018-04-12 15:37:53 10207258 1
behavior.info()
'pandas.core.frame.DataFrame'>
Int64Index: 7540394 entries, 17 to 37214234
Data columns (total 5 columns):
user_id int64
sku_id int64
action_time object
module_id int64
type int64
dtypes: int64(4), object(1)
memory usage: 345.2+ MB
# 查看缺失值
behavior.isnull().sum()
user_id 0
sku_id 0
action_time 0
module_id 0
type 0
dtype: int64
# 原始数据中时间列action_time,时间和日期是在一起的,不方便分析,对action_time列进行处理,拆分出日期和时间列,并添加星期字段求出每天对应
# 的星期,方便后续按时间纬度对数据进行分析
behavior['date'] = pd.to_datetime(behavior['action_time']).dt.date # 日期
behavior['hour'] = pd.to_datetime(behavior['action_time']).dt.hour # 时间
behavior['weekday'] = pd.to_datetime(behavior['action_time']).dt.weekday_name # 周
# 去除与分析无关的列
behavior = behavior.drop('module_id', axis=1)
# 将用户行为标签由数字类型改为用字符表示
behavior_type = {1:'pv',2:'pay',3:'fav',4:'comm',5:'cart'}
behavior['type'] = behavior['type'].apply(lambda x: behavior_type[x])
behavior.reset_index(drop=True,inplace=True)
# 查看处理好的数据
behavior[:10]
user_id sku_id action_time type date hour weekday
0 1455298 208441 2018-04-11 15:21:43 pv 2018-04-11 15 Wednesday
1 1455298 334318 2018-04-11 15:14:54 pv 2018-04-11 15 Wednesday
2 1455298 237755 2018-04-11 15:14:13 pv 2018-04-11 15 Wednesday
3 1455298 6422 2018-04-11 15:22:25 pv 2018-04-11 15 Wednesday
4 1455298 268566 2018-04-11 15:14:26 pv 2018-04-11 15 Wednesday
5 1455298 115915 2018-04-11 15:13:35 pv 2018-04-11 15 Wednesday
6 1455298 208254 2018-04-11 15:22:16 pv 2018-04-11 15 Wednesday
7 1455298 177209 2018-04-14 14:09:59 pv 2018-04-14 14 Saturday
8 1455298 71793 2018-04-14 14:10:29 pv 2018-04-14 14 Saturday
9 1455298 141950 2018-04-12 15:37:53 pv 2018-04-12 15 Thursday
4、分析模型构建指标
1.流量指标分析
pv、uv、消费用户数占比、消费用户总访问量占比、消费用户人均访问量、跳失率。
PV UV
# 总访问量
pv = behavior[behavior['type'] == 'pv']['user_id'].count()
# 总访客数
uv = behavior['user_id'].nunique()
# 消费用户数
user_pay = behavior[behavior['type'] == 'pay']['user_id'].unique()
# 日均访问量
pv_per_day = pv / behavior['date'].nunique()
# 人均访问量
pv_per_user = pv / uv
# 消费用户访问量
pv_pay = behavior[behavior['user_id'].isin(user_pay)]['type'].value_counts().pv
# 消费用户数占比
user_pay_rate = len(user_pay) / uv
# 消费用户访问量占比
pv_pay_rate = pv_pay / pv
# 消费用户人均访问量
pv_per_buy_user = pv_pay / len(user_pay)
# SQL
SELECT count(DISTINCT user_id) UV,
(SELECT count(*) PV from behavior_sql WHERE type = 'pv') PV
FROM behavior_sql;
SELECT count(DISTINCT user_id)
FROM behavior_sql
WHERE WHERE type = 'pay';
SELECT type, COUNT(*) FROM behavior_sql
WHERE
user_id IN
(SELECT DISTINCT user_id
FROM behavior_sql
WHERE type = 'pay')
AND type = 'pv'
GROUP BY type;
print('总访问量为 %i' %pv)
print('总访客数为 %i' %uv)
print('消费用户数为 %i' %len(user_pay))
print('消费用户访问量为 %i' %pv_pay)
print('日均访问量为 %.3f' %pv_per_day)
print('人均访问量为 %.3f' %pv_per_user)
print('消费用户人均访问量为 %.3f' %pv_per_buy_user)
print('消费用户数占比为 %.3f%%' %(user_pay_rate * 100))
print('消费用户访问量占比为 %.3f%%' %(pv_pay_rate * 100))
总访问量为 6229177
总访客数为 728959
消费用户数为 395874
消费用户访问量为 3918000
日均访问量为 389323.562
人均访问量为 8.545
消费用户人均访问量为 9.897
消费用户数占比为 54.307%
消费用户访问量占比为 62.898%
跳失率
# 跳失率:只进行了一次操作就离开的用户数/总用户数
attrition_rates = sum(behavior.groupby('user_id')['type'].count() == 1) / (behavior['user_id'].nunique())
# SQL
SELECT
(SELECT COUNT(*)
FROM (SELECT user_id
FROM behavior_sql GROUP BY user_id
HAVING COUNT(type)=1) A) /
(SELECT COUNT(DISTINCT user_id) UV FROM behavior_sql) attrition_rates;
print('跳失率为 %.3f%%' %(attrition_rates * 100) )
跳失率为 22.585%
2、用户消费频次分析
# 单个用户消费总次数
total_buy_count = (behavior[behavior['type']=='pay'].groupby(['user_id'])['type'].count()
.to_frame().rename(columns={'type':'total'}))
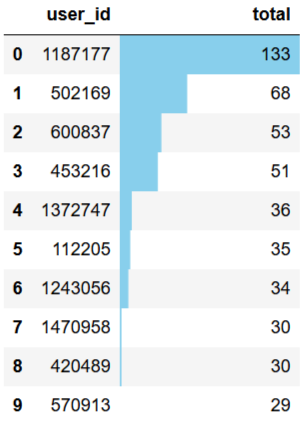
# 消费次数前10客户
topbuyer10 = total_buy_count.sort_values(by='total',ascending=False)[:10]
# 复购率
re_buy_rate = total_buy_count[total_buy_count>=2].count()/total_buy_count.count()
# SQL
#消费次数前10客户
SELECT user_id, COUNT(type) total_buy_count
FROM behavior_sql
WHERE type = 'pay'
GROUP BY user_id
ORDER BY COUNT(type) DESC
LIMIT 10
#复购率
CREAT VIEW v_buy_count
AS SELECT user_id, COUNT(type) total_buy_count
FROM behavior_sql
WHERE type = 'pay'
GROUP BY user_id;
SELECT CONCAT(ROUND((SUM(CASE WHEN total_buy_count>=2 THEN 1 ELSE 0 END)/
SUM(CASE WHEN total_buy_count>0 THEN 1 ELSE 0 END))*100,2),'%') AS re_buy_rate
FROM v_buy_count;
topbuyer10.reset_index().style.bar(color='skyblue',subset=['total'])
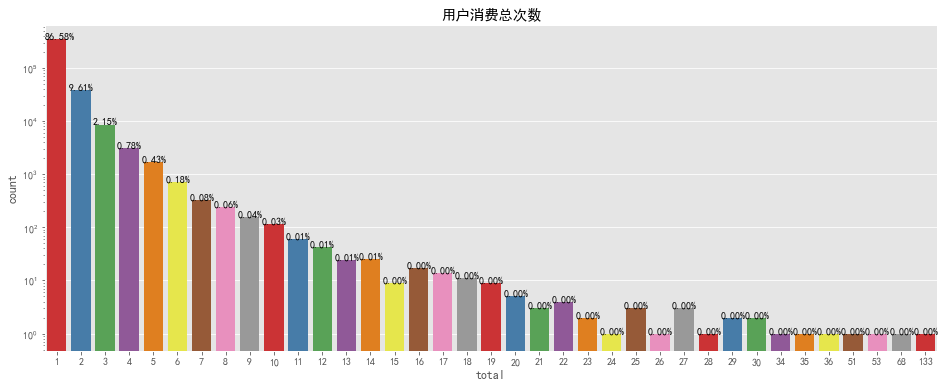
# 单个用户消费总次数可视化
tbc_box = total_buy_count.reset_index()
fig, ax = plt.subplots(figsize=[16,6])
ax.set_yscale("log")
sns.countplot(x=tbc_box['total'],data=tbc_box,palette='Set1')
for p in ax.patches:
ax.annotate('{:.2f}%'.format(100*p.get_height()/len(tbc_box['total'])), (p.get_x() - 0.1, p.get_height()))
plt.title('用户消费总次数')
print('复购率为 %.3f%%' %(re_buy_rate * 100))
复购率为 13.419%
3、用户行为在时间纬度的分布
# 日活跃人数(有一次操作即视为活跃)
daily_active_user = behavior.groupby('date')['user_id'].nunique()
# 日消费人数
daily_buy_user = behavior[behavior['type'] == 'pay'].groupby('date')['user_id'].nunique()
# 日消费人数占比
proportion_of_buyer = daily_buy_user / daily_active_user
# 日消费总次数
daily_buy_count = behavior[behavior['type'] == 'pay'].groupby('date')['type'].count()
# 消费用户日人均消费次数
consumption_per_buyer = daily_buy_count / daily_buy_user
# SQL
# 日消费总次数
SELECT date, COUNT(type) pay_daily FROM behavior_sql
WHERE type = 'pay'
GROUP BY date;
# 日活跃人数
SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY date;
# 日消费人数
SELECT date, COUNT(DISTINCT user_id) user_pay_daily FROM behavior_sql
WHERE type = 'pay'
GROUP BY date;
# 日消费人数占比
SELECT
(SELECT date, COUNT(DISTINCT user_id) user_pay_daily FROM behavior_sql
WHERE type = 'pay'
GROUP BY date) /
(SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY date)
# 日人均消费次数
SELECT
(SELECT date, COUNT(type) pay_daily FROM behavior_sql
WHERE type = 'pay'
GROUP BY date) /
(SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY date)
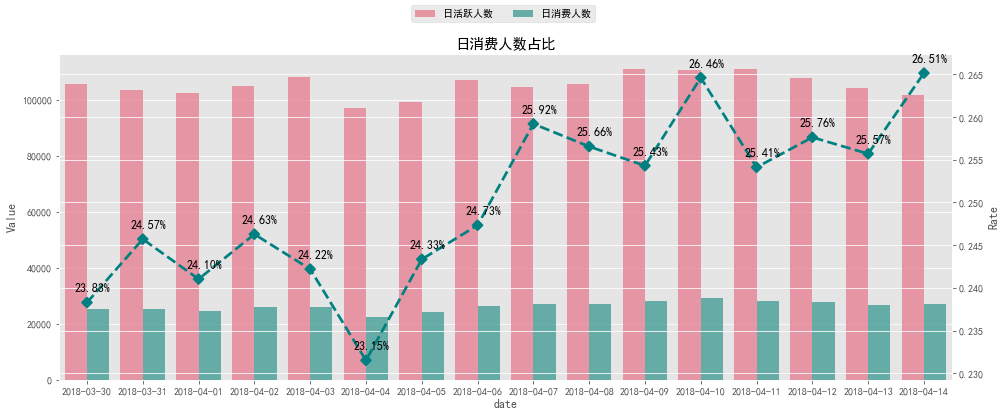
# 日消费人数占比可视化
# 柱状图数据
pob_bar = (pd.merge(daily_active_user,daily_buy_user,on='date').reset_index()
.rename(columns={'user_id_x':'日活跃人数','user_id_y':'日消费人数'})
.set_index('date').stack().reset_index().rename(columns={'level_1':'Variable',0: 'Value'}))
# 线图数据
pob_line = proportion_of_buyer.reset_index().rename(columns={'user_id':'Rate'})
fig1 = plt.figure(figsize=[16,6])
ax1 = fig1.add_subplot(111)
ax2 = ax1.twinx()
sns.barplot(x='date', y='Value', hue='Variable', data=pob_bar, ax=ax1, alpha=0.8, palette='husl')
ax1.legend().set_title('')
ax1.legend().remove()
sns.pointplot(pob_line['date'], pob_line['Rate'], ax=ax2,markers='D', linestyles='--',color='teal')
x=list(range(0,16))
for a,b in zip(x,pob_line['Rate']):
plt.text(a+0.1, b + 0.001, '%.2f%%' % (b*100), ha='center', va= 'bottom',fontsize=12)
fig1.legend(loc='upper center',ncol=2)
plt.title('日消费人数占比')
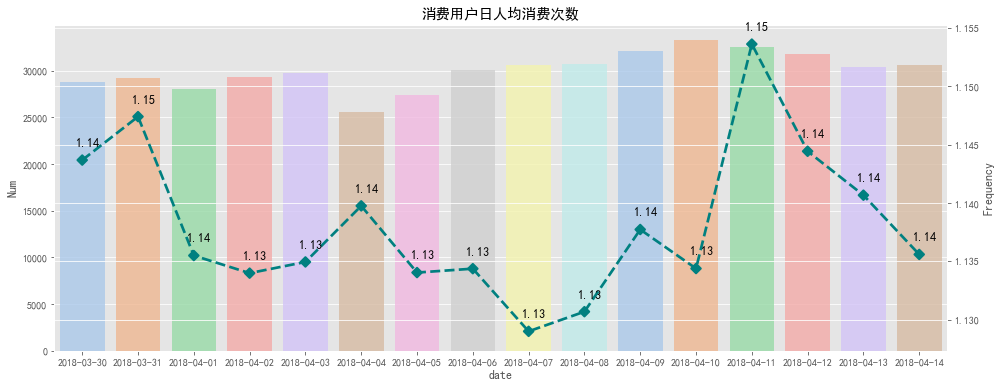
# 消费用户日人均消费次数可视化
# 柱状图数据
cpb_bar = (daily_buy_count.reset_index().rename(columns={'type':'Num'}))
# 线图数据
cpb_line = (consumption_per_buyer.reset_index().rename(columns={0:'Frequency'}))
fig2 = plt.figure(figsize=[16,6])
ax3 = fig2.add_subplot(111)
ax4 = ax3.twinx()
sns.barplot(x='date', y='Num', data=cpb_bar, ax=ax3, alpha=0.8, palette='pastel')
sns.pointplot(cpb_line['date'], cpb_line['Frequency'], ax=ax4, markers='D', linestyles='--',color='teal')
x=list(range(0,16))
for a,b in zip(x,cpb_line['Frequency']):
plt.text(a+0.1, b + 0.001, '%.2f' % b, ha='center', va= 'bottom',fontsize=12)
plt.title('消费用户日人均消费次数')
dau3_df = behavior.groupby(['date','user_id'])['type'].count().reset_index()
dau3_df = dau3_df[dau3_df['type'] >= 3]
# 每日高活跃用户数(每日操作数大于3次)
dau3_num = dau3_df.groupby('date')['user_id'].nunique()
# SQL
SELECT date, COUNT(DISTINCT user_id)
FROM
(SELECT date, user_id, COUNT(type)
FROM behavior_sql
GROUP BY date, user_id
HAVING COUNT(type) >= 3) dau3
GROUP BY date;
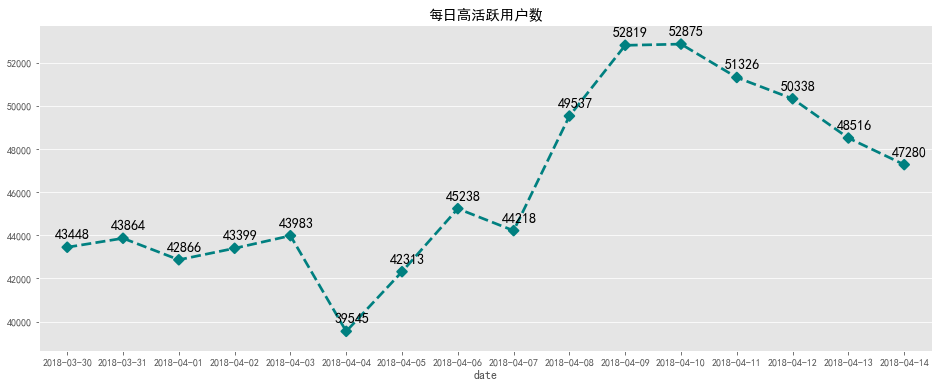
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(dau3_num.index, dau3_num.values, markers='D', linestyles='--',color='teal')
x=list(range(0,16))
for a,b in zip(x,dau3_num.values):
plt.text(a+0.1, b + 300 , '%i' % b, ha='center', va= 'bottom',fontsize=14)
plt.title('每日高活跃用户数')
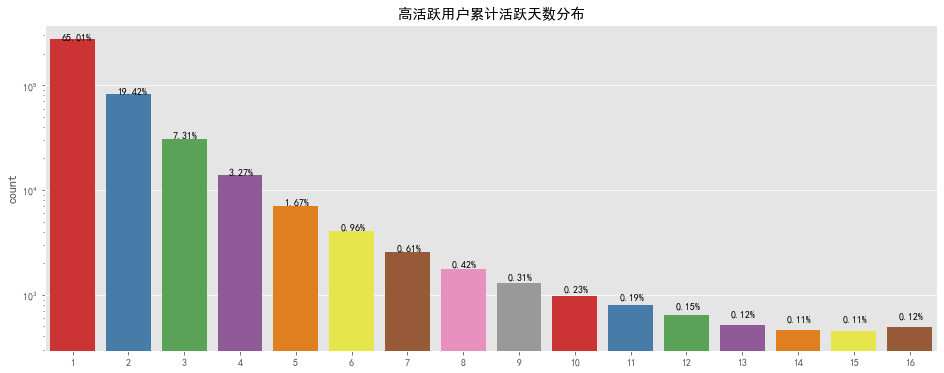
# 高活跃用户累计活跃天数分布
dau3_cumsum = dau3_df.groupby('user_id')['date'].count()
# SQL
SELECT user_id, COUNT(date)
FROM
(SELECT date, user_id, COUNT(type)
FROM behavior_sql
GROUP BY date, user_id
HAVING COUNT(type) >= 3) dau3
GROUP BY user_id;
fig, ax = plt.subplots(figsize=[16,6])
ax.set_yscale("log")
sns.countplot(dau3_cumsum.values,palette='Set1')
for p in ax.patches:
ax.annotate('{:.2f}%'.format(100*p.get_height()/len(dau3_cumsum.values)), (p.get_x() + 0.2, p.get_height() + 100))
plt.title('高活跃用户累计活跃天数分布')
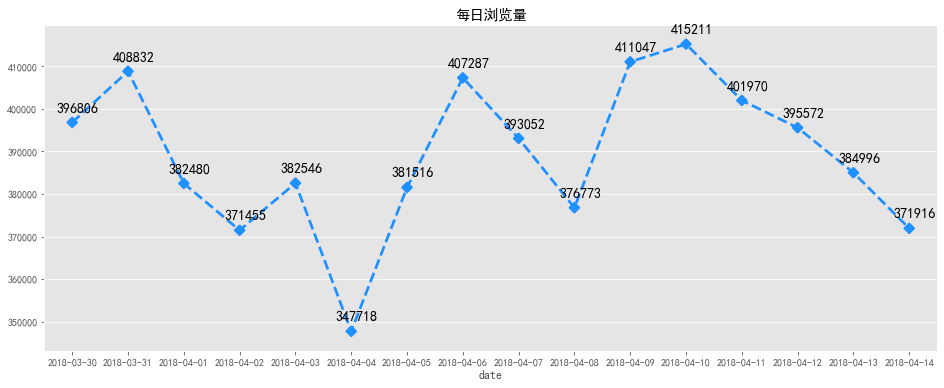
#每日浏览量
pv_daily = behavior[behavior['type'] == 'pv'].groupby('date')['user_id'].count()
#每日访客数
uv_daily = behavior.groupby('date')['user_id'].nunique()
# SQL
#每日浏览量
SELECT date, COUNT(type) pv_daily FROM behavior_sql
WHERE type = 'pv'
GROUP BY date;
#每日访客数
SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY date;
# 每日浏览量可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(pv_daily.index, pv_daily.values,markers='D', linestyles='--',color='dodgerblue')
x=list(range(0,16))
for a,b in zip(x,pv_daily.values):
plt.text(a+0.1, b + 2000 , '%i' % b, ha='center', va= 'bottom',fontsize=14)
plt.title('每日浏览量')
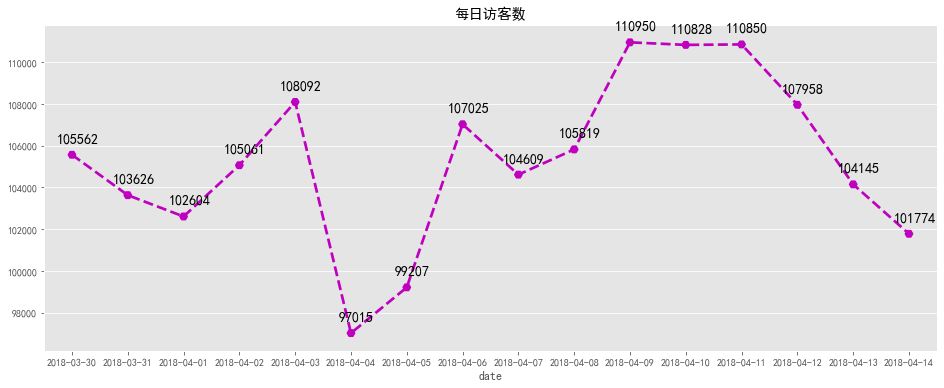
# 每日访客数可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(uv_daily.index, uv_daily.values, markers='H', linestyles='--',color='m')
x=list(range(0,16))
for a,b in zip(x,uv_daily.values):
plt.text(a+0.1, b + 500 , '%i' % b, ha='center', va= 'bottom',fontsize=14)
plt.title('每日访客数')
#每时浏览量
pv_hourly = behavior[behavior['type'] == 'pv'].groupby('hour')['user_id'].count()
#每时访客数
uv_hourly = behavior.groupby('hour')['user_id'].nunique()
# SQL
# 每时浏览量
SELECT date, COUNT(type) pv_daily FROM behavior_sql
WHERE type = 'pv'
GROUP BY hour;
# 每时访客数
SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY hour;
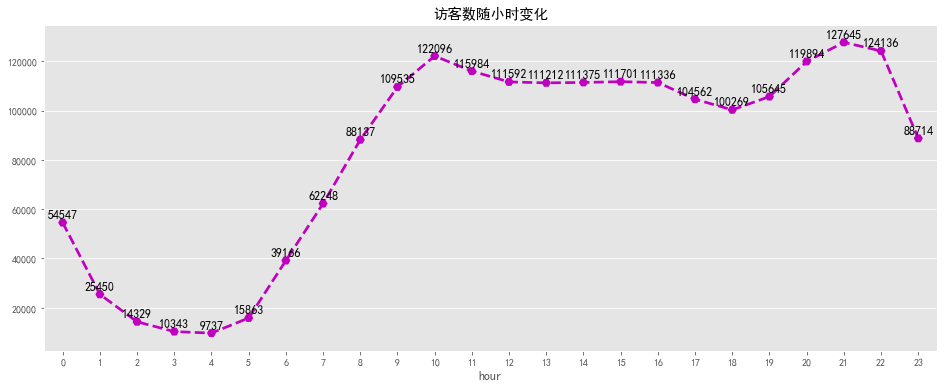
# 浏览量随小时变化可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(pv_hourly.index, pv_hourly.values, markers='H', linestyles='--',color='dodgerblue')
for a,b in zip(pv_hourly.index,pv_hourly.values):
plt.text(a, b + 10000 , '%i' % b, ha='center', va= 'bottom',fontsize=12)
plt.title('浏览量随小时变化')
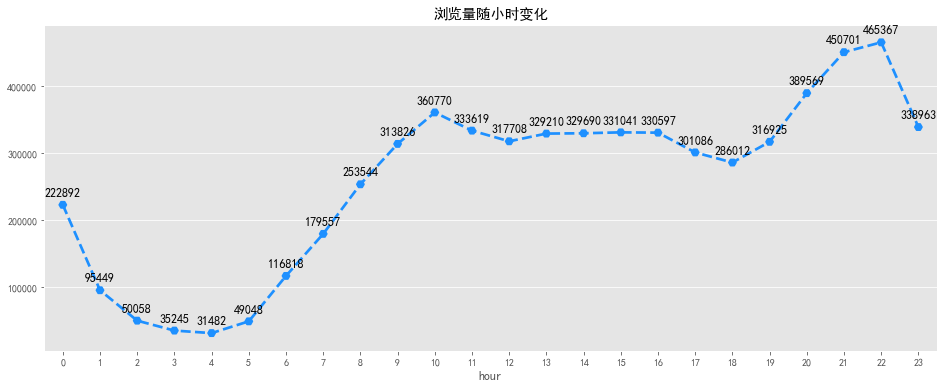
# 访客数随小时变化可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(uv_hourly.index, uv_hourly.values, markers='H', linestyles='--',color='m')
for a,b in zip(uv_hourly.index,uv_hourly.values):
plt.text(a, b + 1000 , '%i' % b, ha='center', va= 'bottom',fontsize=12)
plt.title('访客数随小时变化')
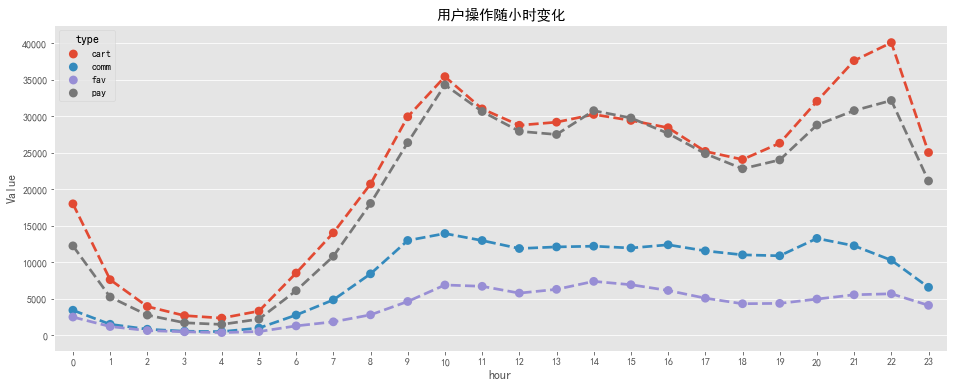
# 用户各操作随小时变化
type_detail_hour = pd.pivot_table(columns = 'type',index = 'hour', data = behavior,aggfunc=np.size,values = 'user_id')
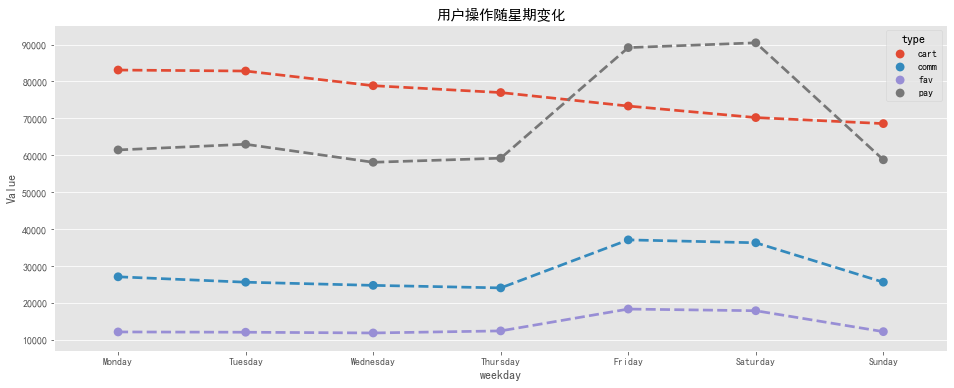
# 用户各操作随星期变化
type_detail_weekday = pd.pivot_table(columns = 'type',index = 'weekday', data = behavior,aggfunc=np.size,values = 'user_id')
type_detail_weekday = type_detail_weekday.reindex(['Monday','Tuesday','Wednesday','Thursday','Friday','Saturday','Sunday'])
# SQL
# 用户各操作随小时变化
SELECT hour,
SUM(CASE WHEN behavior='pv' THEN 1 ELSE 0 END)AS 'pv',
SUM(CASE WHEN behavior='fav' THEN 1 ELSE 0 END)AS 'fav',
SUM(CASE WHEN behavior='cart' THEN 1 ELSE 0 END)AS 'cart',
SUM(CASE WHEN behavior='pay' THEN 1 ELSE 0 END)AS 'pay'
FROM behavior_sql
GROUP BY hour
ORDER BY hour
# 用户各操作随星期变化
SELECT weekday,
SUM(CASE WHEN behavior='pv' THEN 1 ELSE 0 END)AS 'pv',
SUM(CASE WHEN behavior='fav' THEN 1 ELSE 0 END)AS 'fav',
SUM(CASE WHEN behavior='cart' THEN 1 ELSE 0 END)AS 'cart',
SUM(CASE WHEN behavior='pay' THEN 1 ELSE 0 END)AS 'pay'
FROM behavior_sql
GROUP BY weekday
ORDER BY weekday
tdh_line = type_detail_hour.stack().reset_index().rename(columns={0: 'Value'})
tdw_line = type_detail_weekday.stack().reset_index().rename(columns={0: 'Value'})
tdh_line= tdh_line[~(tdh_line['type'] == 'pv')]
tdw_line= tdw_line[~(tdw_line['type'] == 'pv')]
# 用户操作随小时变化可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(x='hour', y='Value', hue='type', data=tdh_line, linestyles='--')
plt.title('用户操作随小时变化')
# 用户操作随星期变化可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(x='weekday', y='Value', hue='type', data=tdw_line[~(tdw_line['type'] == 'pv')], linestyles='--')
plt.title('用户操作随星期变化')
4、用户行为转化漏斗
# 导入相关包
from pyecharts import options as opts
from pyecharts.charts import Funnel
import math
behavior['action_time'] = pd.to_datetime(behavior['action_time'],format ='%Y-%m-%d %H:%M:%S')
# 用户整体行为分布
type_dis = behavior['type'].value_counts().reset_index()
type_dis['rate'] = round((type_dis['type'] / type_dis['type'].sum()),3)
type_dis.style.bar(color='skyblue',subset=['rate'])

df_con = behavior[['user_id', 'sku_id', 'action_time', 'type']]
df_pv = df_con[df_con['type'] == 'pv']
df_fav = df_con[df_con['type'] == 'fav']
df_cart = df_con[df_con['type'] == 'cart']
df_pay = df_con[df_con['type'] == 'pay']
df_pv_uid = df_con[df_con['type'] == 'pv']['user_id'].unique()
df_fav_uid = df_con[df_con['type'] == 'fav']['user_id'].unique()
df_cart_uid = df_con[df_con['type'] == 'cart']['user_id'].unique()
df_pay_uid = df_con[df_con['type'] == 'pay']['user_id'].unique()
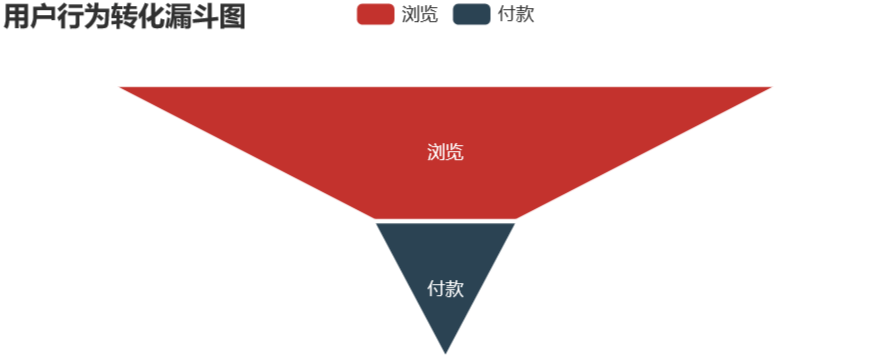
pv – buy
fav_cart_list = set(df_fav_uid) | set(df_cart_uid)
pv_pay_df = pd.merge(left=df_pv, right=df_pay, how='inner', on=['user_id', 'sku_id'], suffixes=('_pv', '_pay'))
pv_pay_df = pv_pay_df[(~pv_pay_df['user_id'].isin(fav_cart_list)) & (pv_pay_df['action_time_pv'] 'action_time_pay'])]
uv = behavior['user_id'].nunique()
pv_pay_num = pv_pay_df['user_id'].nunique()
pv_pay_data = pd.DataFrame({'type':['浏览','付款'],'num':[uv,pv_pay_num]})
pv_pay_data['conversion_rates'] = (round((pv_pay_data['num'] / pv_pay_data['num'][0]),4) * 100)
attr1 = list(pv_pay_data.type)
values1 = list(pv_pay_data.conversion_rates)
data1 = [[attr1[i], values1[i]] for i in range(len(attr1))]
# 用户行为转化漏斗可视化
pv_pay=(Funnel(opts.InitOpts(width="600px", height="300px"))
.add(
series_name="",
data_pair=data1,
gap=2,
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{b} : {c}%"),
label_opts=opts.LabelOpts(is_show=True, position="inside"),
itemstyle_opts=opts.ItemStyleOpts(border_color="#fff", border_width=1)
)
.set_global_opts(title_opts=opts.TitleOpts(title="用户行为转化漏斗图"))
)
pv_pay.render_notebook()
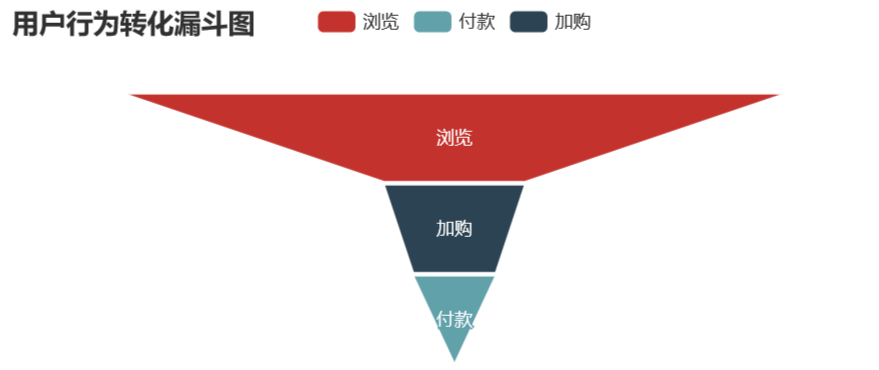
pv – cart – pay
pv_cart_df = pd.merge(left=df_pv, right=df_cart, how='inner', on=['user_id', 'sku_id'], suffixes=('_pv', '_cart'))
pv_cart_df = pv_cart_df[pv_cart_df['action_time_pv'] 'action_time_cart']]
pv_cart_df = pv_cart_df[~pv_cart_df['user_id'].isin(df_fav_uid)]
pv_cart_pay_df = pd.merge(left=pv_cart_df, right=df_pay, how='inner', on=['user_id', 'sku_id'])
pv_cart_pay_df = pv_cart_pay_df[pv_cart_pay_df['action_time_cart'] 'action_time']]
uv = behavior['user_id'].nunique()
pv_cart_num = pv_cart_df['user_id'].nunique()
pv_cart_pay_num = pv_cart_pay_df['user_id'].nunique()
pv_cart_pay_data = pd.DataFrame({'type':['浏览','加购','付款'],'num':[uv,pv_cart_num,pv_cart_pay_num]})
pv_cart_pay_data['conversion_rates'] = (round((pv_cart_pay_data['num'] / pv_cart_pay_data['num'][0]),4) * 100)
attr2 = list(pv_cart_pay_data.type)
values2 = list(pv_cart_pay_data.conversion_rates)
data2 = [[attr2[i], values2[i]] for i in range(len(attr2))]
# 用户行为转化漏斗可视化
pv_cart_buy=(Funnel(opts.InitOpts(width="600px", height="300px"))
.add(
series_name="",
data_pair=data2,
gap=2,
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{b} : {c}%"),
label_opts=opts.LabelOpts(is_show=True, position="inside"),
itemstyle_opts=opts.ItemStyleOpts(border_color="#fff", border_width=1)
)
.set_global_opts(title_opts=opts.TitleOpts(title="用户行为转化漏斗图"))
)
pv_cart_buy.render_notebook()
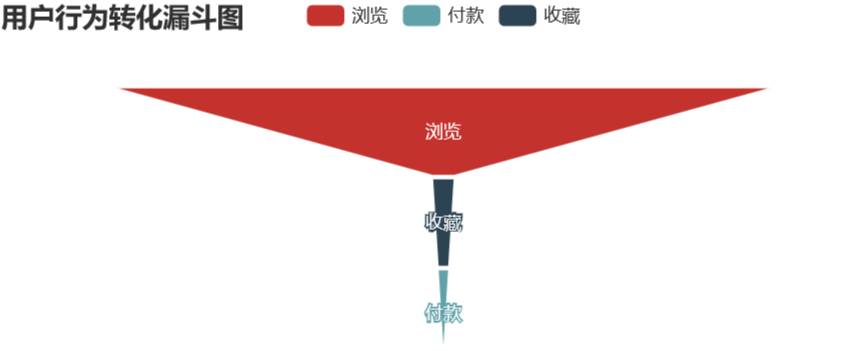
pv – fav – pay
pv_fav_df = pd.merge(left=df_pv, right=df_fav, how='inner', on=['user_id', 'sku_id'], suffixes=('_pv', '_fav'))
pv_fav_df = pv_fav_df[pv_fav_df['action_time_pv'] 'action_time_fav']]
pv_fav_df = pv_fav_df[~pv_fav_df['user_id'].isin(df_cart_uid)]
pv_fav_pay_df = pd.merge(left=pv_fav_df, right=df_pay, how='inner', on=['user_id', 'sku_id'])
pv_fav_pay_df = pv_fav_pay_df[pv_fav_pay_df['action_time_fav'] 'action_time']]
uv = behavior['user_id'].nunique()
pv_fav_num = pv_fav_df['user_id'].nunique()
pv_fav_pay_num = pv_fav_pay_df['user_id'].nunique()
pv_fav_pay_data = pd.DataFrame({'type':['浏览','收藏','付款'],'num':[uv,pv_fav_num,pv_fav_pay_num]})
pv_fav_pay_data['conversion_rates'] = (round((pv_fav_pay_data['num'] / pv_fav_pay_data['num'][0]),4) * 100)
attr3 = list(pv_fav_pay_data.type)
values3 = list(pv_fav_pay_data.conversion_rates)
data3 = [[attr3[i], values3[i]] for i in range(len(attr3))]
# 用户行为转化漏斗可视化
pv_fav_buy=(Funnel(opts.InitOpts(width="600px", height="300px"))
.add(
series_name="",
data_pair=data3,
gap=2,
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{b} : {c}%"),
label_opts=opts.LabelOpts(is_show=True, position="inside"),
itemstyle_opts=opts.ItemStyleOpts(border_color="#fff", border_width=1)
)
.set_global_opts(title_opts=opts.TitleOpts(title="用户行为转化漏斗图"))
)
pv_fav_buy.render_notebook()
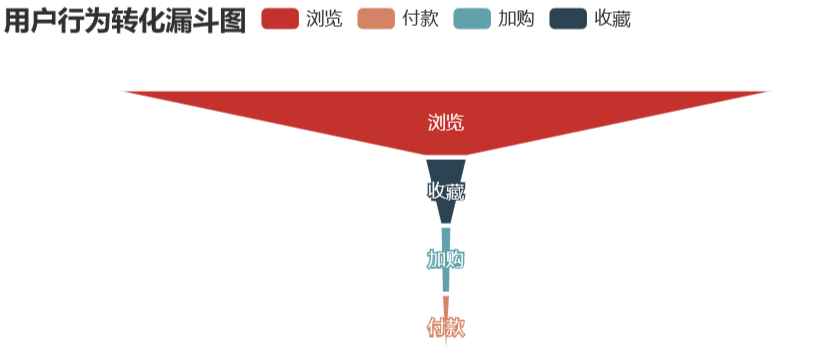
pv – fav – cart – pay
pv_fav = pd.merge(left=df_pv, right=df_fav, how='inner', on=['user_id', 'sku_id'],suffixes=('_pv', '_fav'))
pv_fav = pv_fav[pv_fav['action_time_pv'] 'action_time_fav']]
pv_fav_cart = pd.merge(left=pv_fav, right=df_cart, how='inner', on=['user_id', 'sku_id'])
pv_fav_cart = pv_fav_cart[pv_fav_cart['action_time_fav']'action_time']]
pv_fav_cart_pay = pd.merge(left=pv_fav_cart, right=df_pay, how='inner', on=['user_id', 'sku_id'],suffixes=('_cart', '_pay'))
pv_fav_cart_pay = pv_fav_cart_pay[pv_fav_cart_pay['action_time_cart']'action_time_pay']]
uv = behavior['user_id'].nunique()
pv_fav_n = pv_fav['user_id'].nunique()
pv_fav_cart_n = pv_fav_cart['user_id'].nunique()
pv_fav_cart_pay_n = pv_fav_cart_pay['user_id'].nunique()
pv_fav_cart_pay_data = pd.DataFrame({'type':['浏览','收藏','加购','付款'],'num':[uv,pv_fav_n,pv_fav_cart_n,pv_fav_cart_pay_n]})
pv_fav_cart_pay_data['conversion_rates'] = (round((pv_fav_cart_pay_data['num'] / pv_fav_cart_pay_data['num'][0]),4) * 100)
attr4 = list(pv_fav_cart_pay_data.type)
values4 = list(pv_fav_cart_pay_data.conversion_rates)
data4 = [[attr4[i], values4[i]] for i in range(len(attr4))]
# 用户行为转化漏斗可视化
pv_fav_buy=(Funnel(opts.InitOpts(width="600px", height="300px"))
.add(
series_name="",
data_pair=data4,
gap=2,
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{b} : {c}%"),
label_opts=opts.LabelOpts(is_show=True, position="inside"),
itemstyle_opts=opts.ItemStyleOpts(border_color="#fff", border_width=1)
)
.set_global_opts(title_opts=opts.TitleOpts(title="用户行为转化漏斗图"))
)
pv_fav_buy.render_notebook()
不同路径用户消费时间间隔分析:
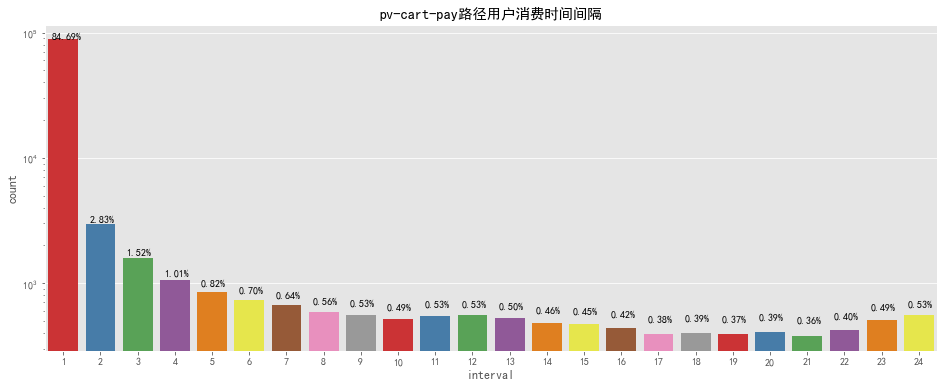
pv – cart – pay
pcp_interval = pv_cart_pay_df.groupby(['user_id', 'sku_id']).apply(lambda x: (x.action_time.min() - x.action_time_cart.min())).reset_index()
pcp_interval['interval'] = pcp_interval[0].apply(lambda x: x.seconds) / 3600
pcp_interval['interval'] = pcp_interval['interval'].apply(lambda x: math.ceil(x))
fig, ax = plt.subplots(figsize=[16,6])
sns.countplot(pcp_interval['interval'],palette='Set1')
for p in ax.patches:
ax.annotate('{:.2f}%'.format(100*p.get_height()/len(pcp_interval['interval'])), (p.get_x() + 0.1, p.get_height() + 100))
ax.set_yscale("log")
plt.title('pv-cart-pay路径用户消费时间间隔')
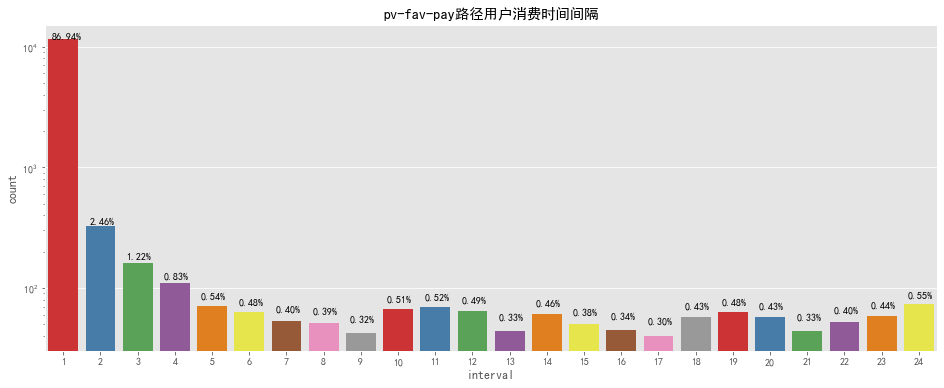
pv – fav – pay
pfp_interval = pv_fav_pay_df.groupby(['user_id', 'sku_id']).apply(lambda x: (x.action_time.min() - x.action_time_fav.min())).reset_index()
pfp_interval['interval'] = pfp_interval[0].apply(lambda x: x.seconds) / 3600
pfp_interval['interval'] = pfp_interval['interval'].apply(lambda x: math.ceil(x))
fig, ax = plt.subplots(figsize=[16,6])
sns.countplot(pfp_interval['interval'],palette='Set1')
for p in ax.patches:
ax.annotate('{:.2f}%'.format(100*p.get_height()/len(pfp_interval['interval'])), (p.get_x() + 0.1, p.get_height() + 10))
ax.set_yscale("log")
plt.title('pv-fav-pay路径用户消费时间间隔')
# SQL
# 漏斗图
SELECT type, COUNT(DISTINCT user_id) user_num
FROM behavior_sql
GROUP BY type
ORDER BY COUNT(DISTINCT user_id) DESC
SELECT COUNT(DISTINCT b.user_id) AS pv_fav_num,COUNT(DISTINCT c.user_id) AS pv_fav_pay_num
FROM
((SELECT DISTINCT user_id, sku_id, action_time FROM users WHERE type='pv' ) AS a
LEFT JOIN
(SELECT DISTINCT user_id, sku_id, action_time FROM users WHERE type='fav'
AND user_id NOT IN
(SELECT DISTINCT user_id
FROM behavior_sql
WHERE type = 'cart')) AS b
ON a.user_id = b.user_id AND a.sku_id = b.sku_id AND a.action_time LEFT JOIN
(SELECT DISTINCT user_id,sku_id,item_category,times_new FROM users WHERE behavior_type='pay') AS c
ON b.user_id = c.user_id AND b.sku_id = c.sku_id AND AND b.action_time
5、用户留存率分析
#留存率
first_day = datetime.date(datetime.strptime('2018-03-30', '%Y-%m-%d'))
fifth_day = datetime.date(datetime.strptime('2018-04-03', '%Y-%m-%d'))
tenth_day = datetime.date(datetime.strptime('2018-04-08', '%Y-%m-%d'))
fifteenth_day = datetime.date(datetime.strptime('2018-04-13', '%Y-%m-%d'))
#第一天新用户数
user_num_first = behavior[behavior['date'] == first_day]['user_id'].to_frame()
#第五天留存用户数
user_num_fifth = behavior[behavior['date'] == fifth_day ]['user_id'].to_frame()
#第十留存用户数
user_num_tenth = behavior[behavior['date'] == tenth_day]['user_id'].to_frame()
#第十五天留存用户数
user_num_fifteenth = behavior[behavior['date'] == fifteenth_day]['user_id'].to_frame()
#第五天留存率
fifth_day_retention_rate = round((pd.merge(user_num_first, user_num_fifth).nunique())
/ (user_num_first.nunique()),4).user_id
#第十天留存率
tenth_day_retention_rate = round((pd.merge(user_num_first, user_num_tenth ).nunique())
/ (user_num_first.nunique()),4).user_id
#第十五天留存率
fifteenth_day_retention_rate = round((pd.merge(user_num_first, user_num_fifteenth).nunique())
/ (user_num_first.nunique()),4).user_id
# 留存率可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.barplot(x='n日后留存率', y='Rate', data=retention_rate,
palette='Set1')
x=list(range(0,3))
for a,b in zip(x,retention_rate['Rate']):
plt.text(a, b + 0.001, '%.2f%%' % (b*100), ha='center', va= 'bottom',fontsize=12)
plt.title('用户留存率')

# SQL
#n日后留存率=(注册后的n日后还登录的用户数)/第一天新增总用户数
create table retention_rate as select count(distinct user_id) as user_num_first from behavior_sql
where date = '2018-03-30';
alter table retention_rate add column user_num_fifth INTEGER;
update retention_rate set user_num_fifth=
(select count(distinct user_id) from behavior_sql
where date = '2018-04-03' and user_id in (SELECT user_id FROM behavior_sql
WHERE date = '2018-03-30'));
alter table retention_rate add column user_num_tenth INTEGER;
update retention_rate set user_num_tenth=
(select count(distinct user_id) from behavior_sql
where date = '2018-04-08' and user_id in (SELECT user_id FROM behavior_sql
WHERE date = '2018-03-30'));
alter table retention_rate add column user_num_fifteenth INTEGER;
update retention_rate set user_num_fifteenth=
(select count(distinct user_id) from behavior_sql
where date = '2018-04-13' and user_id in (SELECT user_id FROM behavior_sql
WHERE date = '2018-03-30'));
SELECT CONCAT(ROUND(100*user_num_fifth/user_num_first,2),'%')AS fifth_day_retention_rate,
CONCAT(ROUND(100*user_num_tenth/user_num_first,2),'%')AS tenth_day_retention_rate,
CONCAT(ROUND(100*user_num_fifteenth/user_num_first,2),'%')AS fifteenth_day_retention_rate
from retention_rate;
6、商品销量分析
# 商品总数
behavior['sku_id'].nunique()
239007
# 商品被购前产生平均操作次数
sku_df = behavior[behavior['sku_id'].isin(behavior[behavior['type'] == 'pay']['sku_id'].unique())].groupby('sku_id')['type'].value_counts().unstack(fill_value=0)
sku_df['total'] = sku_df.sum(axis=1)
sku_df['avg_beha'] = round((sku_df['total'] / sku_df['pay']), 2)
fig, ax = plt.subplots(figsize=[8,6])
sns.scatterplot(x='avg_beha', y='pay', data=sku_df, palette='Set1')
ax.set_xscale("log")
ax.set_yscale("log")
plt.xlabel('平均操作次数')
plt.ylabel('销量')
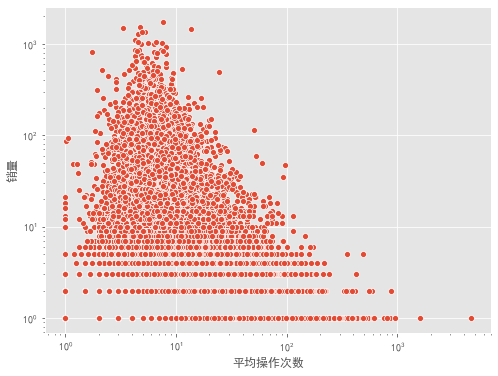
-
左下角操作少购买少,属于冷门购买频率较低的产品。 -
左上角操作少购买多,属于快消类产品,可选择品牌少,少数品牌垄断的行业。 -
右下角操作多购买少,品牌多,但是购买频率低,应为贵重物品类。 -
右上角操作多购买多,大众品牌,可选多,被购买频次高。
# 商品销量排行
sku_num = (behavior[behavior['type'] == 'pay'].groupby('sku_id')['type'].count().to_frame()
.rename(columns={'type':'total'}).reset_index())
# 销量大于1000的商品
topsku = sku_num[sku_num['total'] > 1000].sort_values(by='total',ascending=False)
# 单个用户共购买商品种数
sku_num_per_user = (behavior[behavior['type'] == 'pay']).groupby(['user_id'])['sku_id'].nunique()
topsku.set_index('sku_id').style.bar(color='skyblue',subset=['total'])
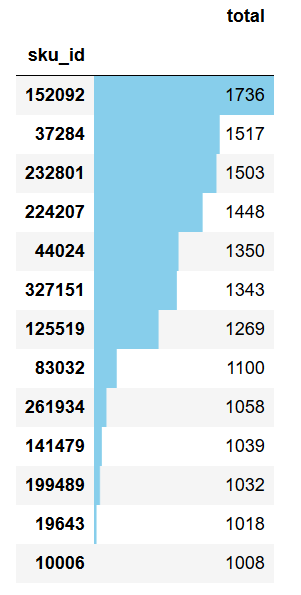
# SQL
# sku销量排行
SELECT sku_id, COUNT(type) sku_num FROM behavior_sql
WHERE type = 'pay'
GROUP BY sku_id
HAVING sku_num > 1000
ORDER BY sku_num DESC;
7、RFM用户分层
#RFM
#由于缺少M(金额)列,仅通过R(最近一次购买时间)和F(消费频率)对用户进行价值分析
buy_group = behavior[behavior['type']=='pay'].groupby('user_id')['date']
#将2018-04-13作为每个用户最后一次购买时间来处理
final_day = datetime.date(datetime.strptime('2018-04-14', '%Y-%m-%d'))
#最近一次购物时间
recent_buy_time = buy_group.apply(lambda x:final_day-x.max())
recent_buy_time = recent_buy_time.reset_index().rename(columns={'date':'recent'})
recent_buy_time['recent'] = recent_buy_time['recent'].map(lambda x:x.days)
#近十五天内购物频率
buy_freq = buy_group.count().reset_index().rename(columns={'date':'freq'})
RFM = pd.merge(recent_buy_time,buy_freq,on='user_id')
RFM['R'] = pd.qcut(RFM.recent,2,labels=['1','0'])
#天数小标签为1天数大标签为0
RFM['F'] = pd.qcut(RFM.freq.rank(method='first'),2,labels=['0','1'])
#频率大标签为1频率小标签为0
RFM['RFM'] = RFM['R'].astype(int).map(str) + RFM['F'].astype(int).map(str)
dict_n={'01':'重要保持客户',
'11':'重要价值客户',
'10':'重要挽留客户',
'00':'一般发展客户'}
#用户标签
RFM['用户等级'] = RFM['RFM'].map(dict_n)
RFM_pie = RFM['用户等级'].value_counts().reset_index()
RFM_pie['Rate'] = RFM_pie['用户等级'] / RFM_pie['用户等级'].sum()
fig, ax = plt.subplots(figsize=[16,6])
plt.pie(RFM_pie['Rate'], labels = RFM_pie['index'], startangle = 90,autopct="%1.2f%%",
counterclock = False,colors = ['yellowgreen', 'gold', 'lightskyblue', 'lightcoral'])
plt.axis('square')
plt.title('RFM用户分层')

-
对于重要价值客户来说,要提高该部分用户的满意度,服务升级,发放特别福利,增大该部分用户留存率,在做运营推广时也要给与特别关注,避免引起用户反感。 -
对于重要保持客户,他们购物频次较高,但最近一段时间没有消费,可以推送相关其他商品,发放优惠卷、赠品和促销信息等,唤回该部分用户。 -
对于重要挽留客户,他们最近消费过,但购物频次较低,可以通过问卷有礼的方式找出其对平台的不满,提升购物体验,增大用户粘性。 -
对于一般发展客户,做到定期发送邮件或短信唤回,努力将其转化为重要保持客户或重要挽留客户。
# SQL
# RFM
CREATE VIEW RF_table AS
SELECT user_id, DATEDIFF('2018-04-14',MAX(date)) AS R_days,
COUNT(*) AS F_count
FROM behavior_sql WHERE type='pay' GROUP BY user_id;
SELECT AVG(R_days), AVG(F_count)
FROM RF_table
create view RF_ layer as
SELECT user_id, (CASE WHEN R_days (CASE WHEN F_count FROM RF_table
ORDER BY user_id DESC;
create view customer_value as
select user_id, R, F, (CASE WHEN R=1 and F=1 THEN "重要价值客户"
WHEN R=1 and F=0 THEN "重要挽留客户"
WHEN R=0 and F=1 THEN "重要保持客户"
WHEN R=0 and F=0 THEN "一般发展客户" ELSE 0 END) as 用户价值
FROM RF_ layer;
SELECT * FROM customer_value;
5、总结
万水千山总是情,点个 👍 行不行。
本文为从大数据到人工智能博主「bajiebajie2333」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/11740/