
本文目录
-
背景
-
实时数仓可以为我们带来什么
-
技术方案选型
-
数据存储方案选型
-
Flink 开发平台选型
-
维表存储方案选型
-
Connector 开发
-
实时数仓整体架构
-
数据开发案例
-
数据接入
-
数据处理
-
展望
背景
流利说最开始的实时数仓是基于 Flink 1.9 搭建的,彼时Flink SQL 的生态也不够成熟,我们投入了大量的精力,使用 Yarn 做资源管理,修改了 SQL-Client 等组件,优化提交方式来提高开发效率,但是随着 Flink 社区的快速发展,此时 Flink 1.13 版本已经相对稳定,Flink SQL connector 也更加完善,可以将 Flink on K8s 资源管理应用于生产环境,所以我们将实时数仓中 Flink 的版本往前推进了一大步,并随即带动了其他生态组件的引入或升级。
实时数仓可以为我们带来什么
得益于开源社区对实时计算的推动,针对我们当下的数据平台的情况,实时数仓能够为我们解决的是
-
数据同步 -
秒级别实时数据处理 -
打通湖上数据达到实时离线一体化
技术方案选型
数据存储方案选型
现在主流的数据糊存储方案主要有 Delta、Hudi 和 Iceberg,Delta 与 Spark 是深度融合的,但由于我们已经选定了 Flink 作为实时计算引擎,故数据湖存储方案会在 Hudi 和 Iceberg 中进行比较,比较的详情如下。
| 比较维度 | Hudi | Iceberg |
|---|---|---|
| 云厂商支持程度 | 阿里云、AWS | 阿里云 |
| 小文件合并 | 自动处理 | V1 版本表支持,需要手动处理 |
| 稳定性 | 稳定 | 稳定 |
| 是否支持sql | 支持 | 支持 |
| 更新删除支持情况 | 支持 | V2 版本表支持 |
| 主流执行引擎支持 | Flink、Spark、Trino、Presto | Flink、Spark、Trino、Presto |
| 语言支持程度 | Java、Scala、Python 及 SQL | Java、Scala、Python 及 SQL |
由于 Iceberg V1 版本表不支持 Upsert ,Iceberg V2版本支持 Upsert 但是在小文件合并时存在问题,且 Iceberg 需要通过额外任务来进行小文件合并,最终选择 Hudi 作为数据湖存储方案。
Flink 开发平台选型
当前流利说大数据体系依托于 Aliyun EMR 集成 Hadoop 环境,维护实时数据运维平台成本较高,所以调研之后选择了阿里云实时计算 Flink (VVP)作为我们的开发平台。
我们关注 VVP 具备的能力主要有如下几个方面:
-
基于 K8s 进行部署,支持 Session 和 Appliction 模式提交任务,支持弹性伸缩 -
Flink SQL 开发界面,交互式的 Debug 数据输出,代码版本控制 -
集群高可用 -
元数据管理,支持接入独立的 Hive Metastore -
自定义 Connector 和 UDF -
Checkpoint 支持读写 OSS -
任务监控支持外部的 Prometheus -
多版本任务
VVP 提高了我们的开发效率,让我们更加专注于实现数据架构。
维表存储方案选型
Flink 官方提供 Connector 的支持情况见官网 Supported Connectors,根据业务情况整理如下几种类型。
| Name | Version | Source | Sink |
|---|---|---|---|
| JDBC | Bounded Scan, Lookup | Streaming Sink, Batch Sink | |
| HBase | 1.4.x & 2.2.x | Bounded Scan, Lookup | Streaming Sink, Batch Sink |
| Elasticsearch | 6.x & 7.x | Not supported | Streaming Sink, Batch Sink |
从上表中可以看出,Flink 官方已经可以使用 JDBC 和 HBase 作为维表进行 Lookup Join,特性如下。
| Name | 优点 | 缺点 |
|---|---|---|
| JDBC | 官方支持,可直接使用业务库作为维表,无需数据同步 | 业务高峰时对数据库性能有较大损耗,可能对业务造成影响 |
| HBase | 官方支持,分布式服务,可支持高QPS,通过 RowKey 可进行快速检索 | 仅支持通过 RowKey 进行关联,Flink 1.13.x 对删除操作存在一定争议 |
| Elasticsearch | 分布式服务,可支持高 QPS,可通过唯一 Id 进行检索,也可通过其他字段进行关联 | 官方不支持,维表过大,效率较 HBase 低 |
综上,因历史数据中存在需要通过多个字段进行关联的情况,需要通过非唯一 id 进行关联,如果使用 HBase 需将一份数据存储为多份数据,会造成一定资源浪费,且会导致系统比较复杂,不利于后续的维护和管理。对于 Elasticsearch 检索较慢,可以在业务允许的范围内,通过 Cache 来进行一定程度优化。
Connector 开发
基于官方提供的文档、接口和我们的需求,我们开发了 Flink-Elasticsearch-connector 并同时支持 Source (Scan, Lookup)和 Sink(Streaming Sink, Batch Sink),即读取和写入数据。
实时数仓整体架构
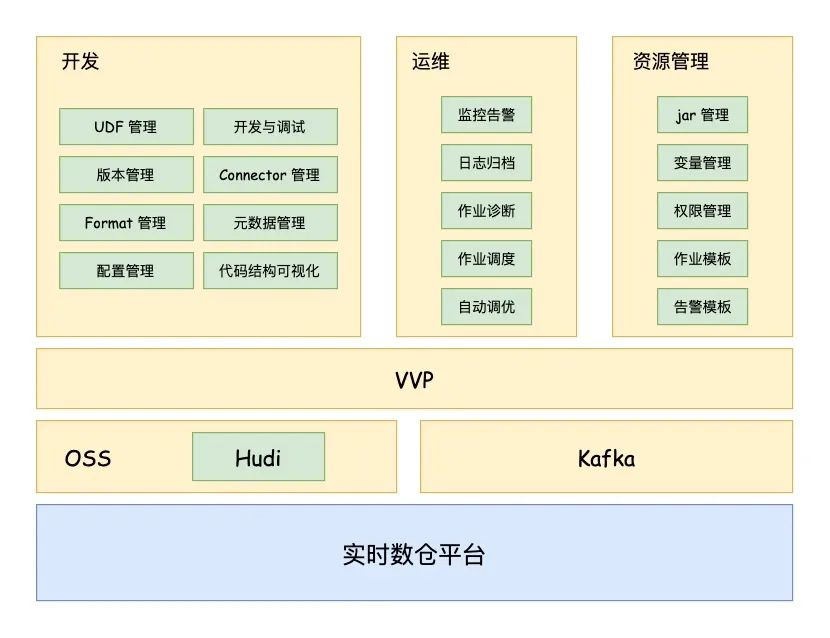
 实时数仓架构图
实时数仓架构图
实时数仓平台架构图如上,存储托管于 Kafka 和 OSS,OSS 中的表主要是 Hudi 类型,VVP 是阿里云托管的实时计算平台,主要提供开发,运维和资源管理等功能,实现 Flink 数据开发运维一体化,提高业务开发效率。
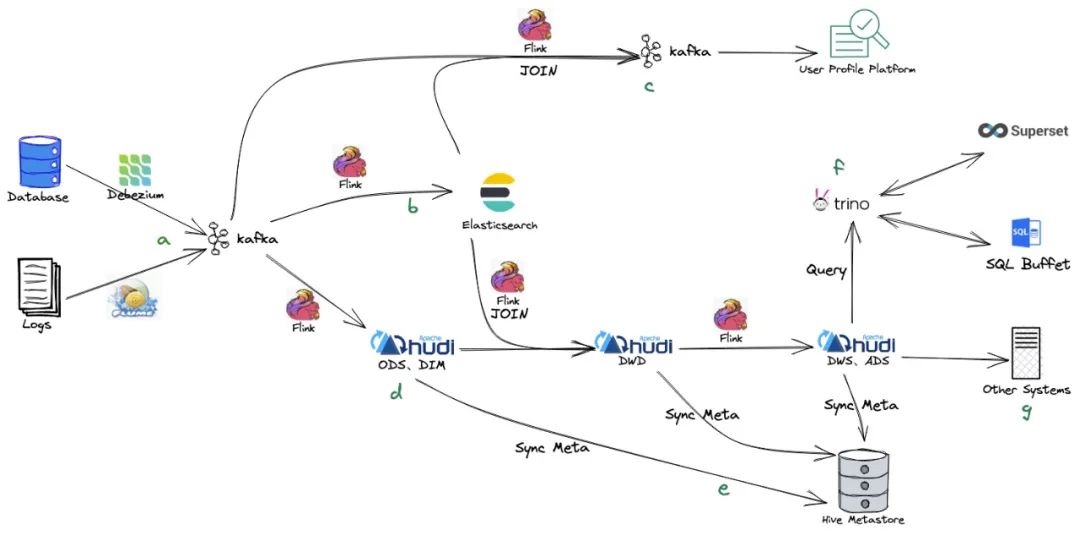
实时计算数据流图如上,几个重要的关键点:
a. 业务数据库和日志数据分别通过 CDC 和 Flume 的方式采集到 Kafka 作为源数据;
b. 维表数据通过 Flink 连接器同步存入 Elasticsearch;
c. Flink Join 维表数据计算存储到 Kafka, 这里采用 Kafka 的原因主要是 User Profile Platform(用户画像系统)对实时性要求较高;
d. Flink 从源数据中同步存入 Hudi 并进行分层处理计算;
e. Hudi 表的所有源数据会自动同步到流利说独立部署的 Hive Metastore;
f. 使用 Trino 引擎对数据做实时在线分析,Superset 报表可以自动生成 Trino SQL 来获取结果,SQL Buffet(流利说数据分析平台)提交自定义 SQL 交互式分析;
g. Hudi 的数据也可以被其他系统所使用,例如数据质量,数据指标等。
数据开发案例
数据接入
首先通过 CDC 将 Mysql 的 Binlog 实时同步到 Kafka 对应 Topic 中,相应数据格式为 Debezium Json。
Hudi 表接入开发流程
使用阿里云实时计算 Flink 作为流式任务调度和任务管理平台
-
通过 FlinkSQL 将历史数据同步到 Hudi 表中 -
FlinkSQL 语句
-- Hudi 表 DDL 语句
CREATE TABLE IF NOT EXISTS catalog.db_name.table_name (
id BIGINT,
xxx STRING,
data_date VARCHAR(20),
PRIMARY KEY (id) NOT ENFORCED
)
WITH (
'connector' = 'hudi',
'table.type' = 'COPY_ON_WRITE',
'write.tasks' = '2',
'index.global.enabled' = 'true',
'index.bootstrap.enabled' = 'true',
'read.streaming.enabled' = 'true',
'oss.endpoint' = 'xxx',
'accessKeyId' = 'xxx',
'accessKeySecret' = 'xxx',
'path' = 'oss://xxx',
'hive_sync.enable' = 'true',
'hive_sync.mode' = 'hms',
'hive_sync.db' = 'hudi',
'hive_sync.metastore.uris' = 'xxx',
'hive_sync.table' = 'xxx',
'compaction.tasks' = '1',
'hoodie.cleaner.commits.retained' = '10',
'hoodie.datasource.write.precombine.field' = 'updated_at',
'hoodie.datasource.write.recordkey.field' = 'id'
);
-- DML 语句
INSERT INTO catalog.db_name.table_name
SELECT id,
xxx,
data_date
FROM kafka_streaming_table
WHERE id != null;
-
通过 Flink SQL 任务实时同步数据到 Hudi (使用 COPY_ON_WRITE 模式),时效性在分钟级别(Checkpoint 时间有关) -
Hudi 表中已经有历史数据时,需要支持按照 ‘PRIMARY KEY’ 进行去重时 -
首次接入流式数据需设置 index.bootstrap.enabled=true,保证数据的唯一性,后续可直接通过状态进行恢复即可 -
要支持更新和删除必须在 DDL 中指定 PRIMARY KEY,或者在 Table Properties 中设置 hoodie.datasource.write.recordkey.field=${YouPrimaryKey} -
需要指定更新的 Precombine Key 须在 Table Properties 中设置 hoodie.datasource.write.precombine.field=${YouPrecombineKey} -
表使用 COPY_ON_WRITE 对读友好,通过 hoodie.cleaner.commits.retained来设置保留的数据历史版本数量,对历史记录进行清理 -
同步元数据到 Hive Metastore 需设置如下参数
| 参数 | 类型 | 备注 |
|---|---|---|
| hive_sync.enable | Boolean | 是否允许进行元数据同步到 Hive |
| hive_sync.mode | String | 指定元数据同步采用 hms(Hive Metastore) |
| hive_sync.metastore.uris | String | Hive Metastore 地址 |
| hive_sync.db | String | 同步到 Hive Metastore 中对应的数据库名 |
| hive_sync.table | String | 同步到 Hive Metastore 中对应的表名 |
-
业务方可通过 Trino 直接对 Hudi 表进行交互式在线查询,需注意版本要支持对 Hudi 表的读取,我们使用的对应 Trino 版本为 359。
ES 维表接入
将开发好的自定义 Flink-Elasticsearch-connector 打包,上传到阿里云实时平台进行注册。
-
通过 FlinkSQL 读取 Kafka 中的数据,写入到 Elasticsearch 中,Flink SQL语句如下
-- ES 表 DDL语句
DROP TABLE IF EXISTS es_dimension01;
CREATE TABLE IF NOT EXISTS es_dimension01(
id STRING,
xxx STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch6-lls',
'format' = 'json',
'hosts' = 'http://xxx:9200',
'index' = 'es_dimension01',
'username' = 'xxx',
'password' = 'xxx'
);
-- DML 读取 Kafka 写出到 Elasticsearch
INSERT INTO es_dimension01
SELECT id,
xxx,
FROM kafka_xxx_dimension;
-
其中 kafka_xxx_dimension 中为同步 binlog 数据,Flink 解析其中 Debezium Format 数据转换为 RowData(其中包含 RowKind — 标识该行数据的操作类型) -
Elasticsearch-connector 支持 upsert,通过设置 es_dimension01 表设定 PRIMARY KEY 对应 Elasticsearch 中的唯一 Id -
在进行 upsert 操作时通过 Id 对数据进行修改和删除操作
数据处理
使用一个标签任务来说明使用流程,该标签任务通过 Flink 消费 Kafka 对应 Topic 中数据,通过关联 Elasticsearch维表进行维度补全,最后将结果输出到指定的 Kafka topic 中,DML 语句如下:
INSERT INTO kafka_sink
SELECT cast (a.id as BIGINT) as id,
'lable0' AS lable,
CASE
WHEN f.id is NOT null THEN f.start_sec * 1000 ELSE e.start_sec * 1000
END AS sourceTime,
CASE
WHEN f.id is NOT null THEN f.end_sec * 1000 ELSE e.end_sec * 1000
END AS expiredAt,
a.updated_at AS updated,
'dmp' as type
FROM
kafka_stream_source a
JOIN es_llspay_order_items FOR SYSTEM_TIME AS OF a.proctime AS b
ON a.id = b.id
JOIN es_dimension01 FOR SYSTEM_TIME AS OF a.proctime AS c
ON b.id = c.id
JOIN es_dimension02 FOR SYSTEM_TIME AS OF a.proctime AS d
ON a.id = d.id LEFT
JOIN es_dimension03 FOR SYSTEM_TIME AS OF a.proctime AS e
ON e.id = d.id LEFT
JOIN kafka_stream_dimension01 AS f
ON CAST (f.id AS STRING) = d.id
AND a.proctime between f.proctime - interval '1' second
and f.proctime + interval '5' second
WHERE
c.name
LIKE '%label1%'
OR c.name
LIKE '%label2%'
AND (
e.id IS NOT NULL
OR f.id IS NOT NULL
);
上面标签任务中,kafka_stream_source 为流表,对应的为 Kafka 中的 topic,通过 Lookup Join 维表 es_dimension01、es_dimension02 和 es_dimension03 进行维度补全,因为 es_dimension03 对应的表更新较频繁,为避免数据未 Join 成功,在这里通过 Interval Join 流表 kafka_stream_dimension01 来进行补偿,当流表 kafka_stream_dimension01 和 es_dimension03 中数据同时 Join 到时,优先使用 kafka_stream_dimension01 中数据,尽可能保证数据的准确性,该标签任务的整体的延迟在秒级,可保证数据的时效性。
展望
实时数仓目前还不能解决所有的计算和存储问题,只能根据业务需求场景来选择离线计算还是实时计算,当前流利说整体数据架构采用的是 Lambda 架构,且离线计算以 Spark 2.4.5 为主(目前 Hive 任务数量已经清零,离线计算全面拥抱 Spark),从最初 Hive 2.X 到 Spark 2.X 一步步升级上来,Hudi 的引入让我们可以方便的查询实时数据,我们希望未来升级完 Spark 3.X 的时候,Hudi 可以继续作为离线批处理的存储,进而实现在流利说离线和实时数仓存储方面的统一。
本文转载自Bruce, Ibson 流利说技术团队,原文链接:https://mp.weixin.qq.com/s/y7L3Mphs_HRy2-2DguZ_OQ。