
背景介绍
1.1 团队简介


1.2 一些概念
-
Minecraft 中的游戏实体包括三部分,掉落物实体、方块实体、生物实体,极少量玩家在线时,无模组服务器平均每分钟都会有上千条实体更新事件产生。 -
当玩家增多时,玩家摆放的方块,玩家身边的实体会进行 tick 计算(1 秒=20 tick)。由于一些历史和执行顺序的原因,区块生成、实体运算等加起来占比超过 60%的部分,都在一个主线程上执行,市面上大多数尝试拆分运算到多线程的服务端,都因为一些莫名其妙的 bug (破坏“游戏机制” 或者 导致一些线程安全、执行顺序、多线程反而造成性能下降的问题) 而不愠不火。 -
对于大型服务器,任何 bug 都可能导致严重后果,本方案几乎不篡改游戏机制,避免遇到上述 bug。 -
大型刷怪场 / 大型红石机器 / 刷石机刷铁机 /…/ 过大的生存建筑包含过量的方块实体。头颅、箱子、信标、牌子、发射器、投掷器、旗帜、盔甲架等等都属于方块实体,每 1/20 秒都需要参与一次运算。让这些东西扎堆出现,显然对服务端不利,会严重影响服务器TPS(Tick Per Second)。直接在服务端进行统计运算是不合适的,这会严重影响到玩家体验。

1.3 方案目的
-
统计服务端集群当前时刻实体的异常点,采用定点清除或限制等策略处理异常点,提升服务端运算效率,提高玩家体验。 -
将 Minecraft 的日志发送到大数据后端,通过 Flink 进行算法统计,将算法参数,输出结果写入数据库报表查看,或者反馈到服务端对生物生成等参数动态调优。
设计方案
2.1 整体架构

2.2 日志采集及信息反馈

-
对掉落物、生物、状态方块进行埋点,获取其唯一标签 -
定时获取服务器 tps、gc 信息,输出到大数据后端 -
实时获取玩家数据信息,记录玩家聊天信息,交互信息等 -
从 mysql 获取大数据后端输出的异常点,采用不同策略处理 -
实时获取 mysql 数据库中的服务端动态配置信息,调整生物刷新率,降低服务器负载
2.3 数据传输

-
相对于传统的 Kafka+Flume 组合,使用 Pravega 可以简化系统处理架构。Pravega 能够自动的将数据由热存储转为冷存储,不需要额外的 ETL 开发。 -
Pravega 对于高吞吐的历史数据和低延迟的实时数据有一致的访问方式,能够有效满足离线计算和实时计算两种处理方式的统一。Pravega 便于后续拓展批数据处理业务,如基于长时间段内的数据进行深度学习模型训练等。 -
Pravega 相比于 Kafka 可以节省数据存储开销。数据在 Pravega 只需要存储一份,而 Kafka 需要存储副本。 -
系统内部将 Pravega 作为存储引擎与消息队列,利用其能够自动伸缩的特性,能够很好地代替 Kafka,并且通过 Pravega Flink Connectors 能够使其与 Flink 之间丝滑对接。 -
出于学习的目的选择使用 Pravega。Pravega 批流一体的存储设计具有有大的发展潜力。
-
这里使用 Springboot 将采集到的数据写入 Pravega(demo 如下):

-
Flink 通过 Connectors 对 Pravega 数据进行消费。这部分使用起来跟 Kafka 差不多,非常方便。

2.4 数据处理

-
对数据进行 ETL

-
将总的日志流按照类别进行分流处理,统计各类实体的数量,便于后续分析 -
数据处理中需要统计出当前时间内各类掉落物的数量以及当前的坐标
-
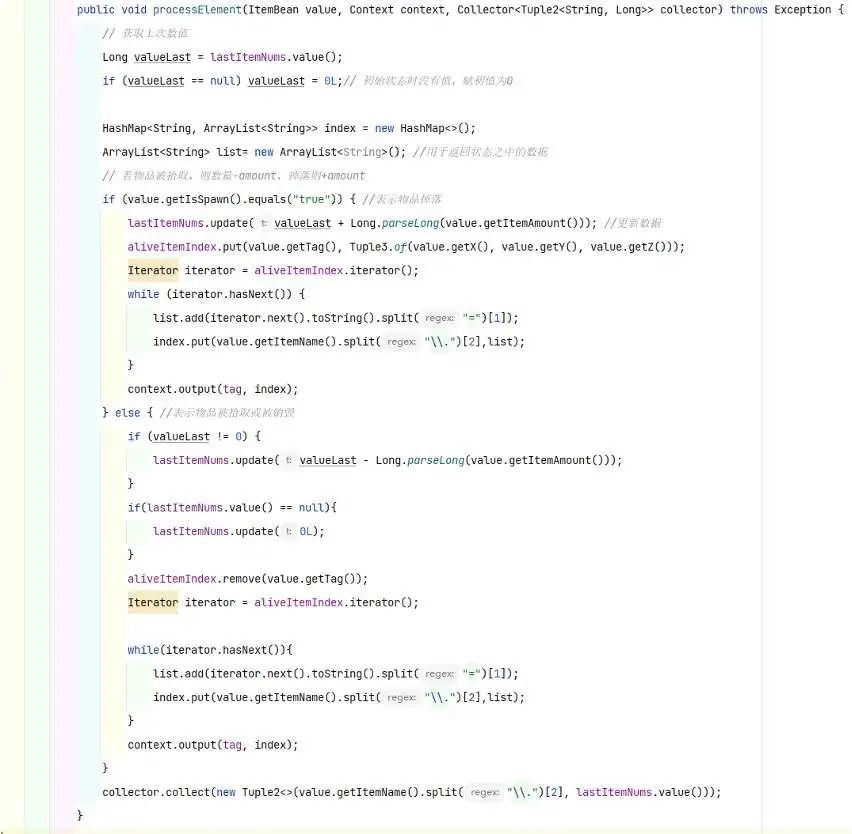
主输出流收集当前时间内掉落物的数量,每来一条游戏日志,判断是否为掉落物类,如果是,判断日志类型为掉落或为拾取,分别加上掉落的 amount 或者减去拾取 amount。 -
侧输出流收集当前时间内掉落物的物品种类以及他们的坐标位置,同样每来一条游戏日志,判断是否为掉落物类,如果是,将掉落物类型和它们的坐标放进 map 中输出。 -
分别将主输出流和测输出流写进 MySQL 中,作为数据展示。
-
使用 DBSCAN 聚类算法对数据点进行实时分析 -
考虑到服务器中数据点的分布是无规则的,而 DBSCAN 是一种可以处理任意形状的空间聚类问题的基于密度的聚类算法,所以该系统选用了 DBSCAN 对数据进行分析。DBSCAN 算法还具有不需要划分类别个数、可以处理噪声点等优点。 -
这里采用的是 org.apache.commons.math3.stat.clustering.DBSCANClusterer

-
要实现实时分析,需要将旧的计算结果保存起来,当新数据到来时能基于旧结果进行计算更新。我们采取的方案是:将每个 cluster 的密度 ρ(cluster 内数据点数/cluster 面积)作为 cluster 中心点的计算权值,既一批数据点经过聚类计算后得到的是各个 cluster 的中心点集,包含了中心点的坐标和权值,将其存储在 Flink 的 State中。当新的数据点到来时就将其与 State 中的中心点集一同进行聚类,并更新最新的中心点集到 State。 -
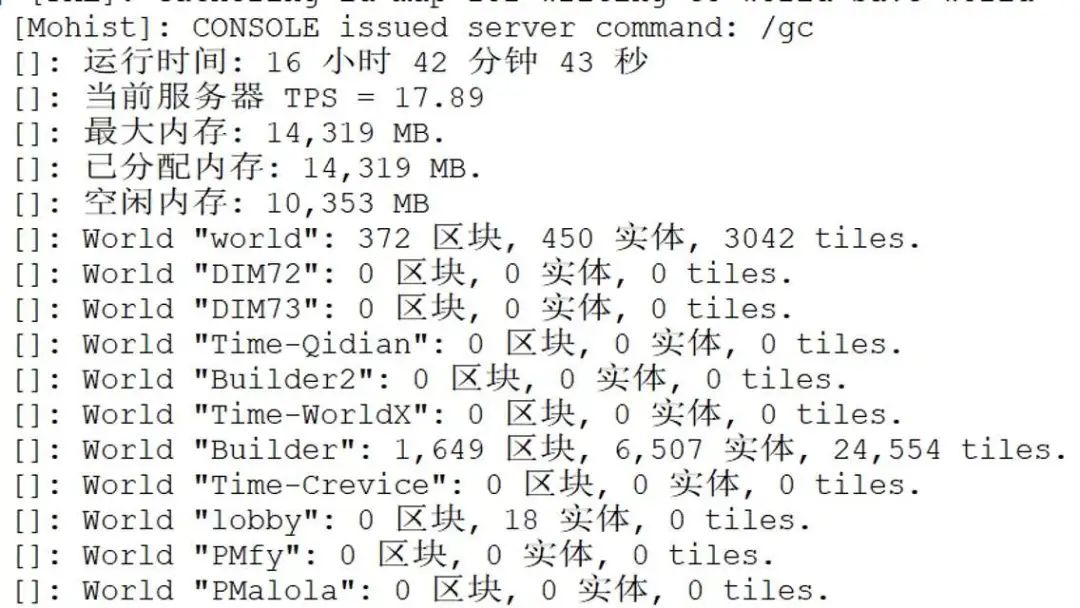
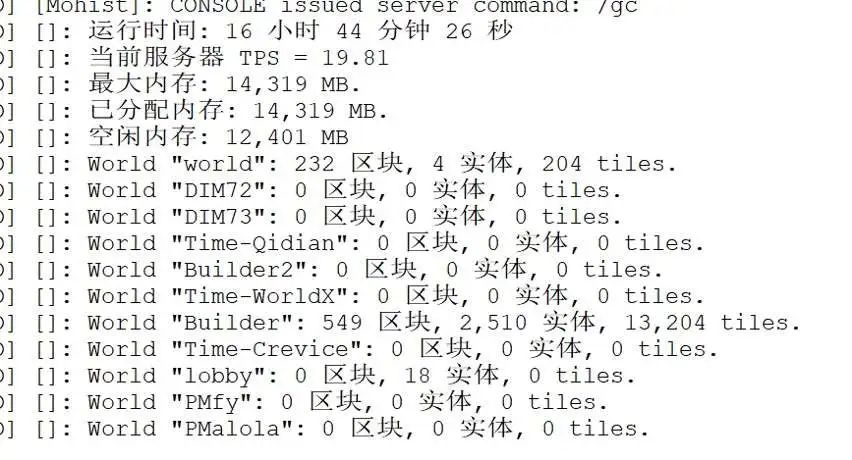
当某中心点 ρ 值大于设定的阈值,则判定为需要进行清理的点,将该点输出至 MySQL 表中。服务器检测到表数据就会对该中心点所在区块的数据进行清理。
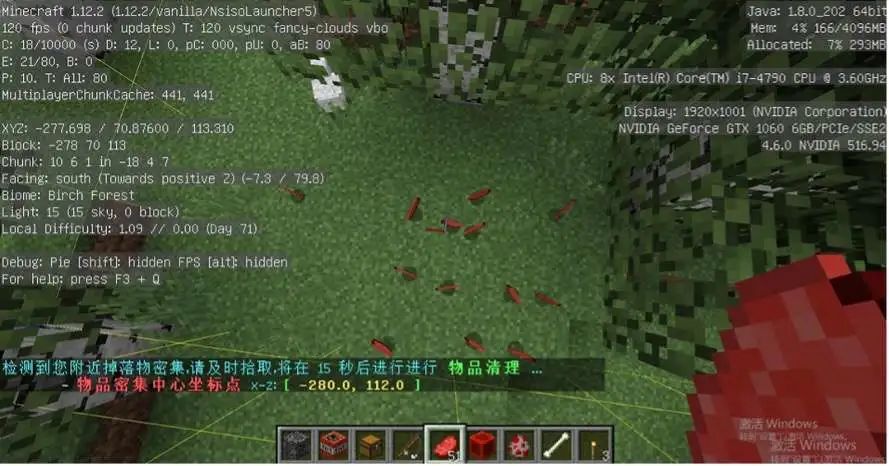
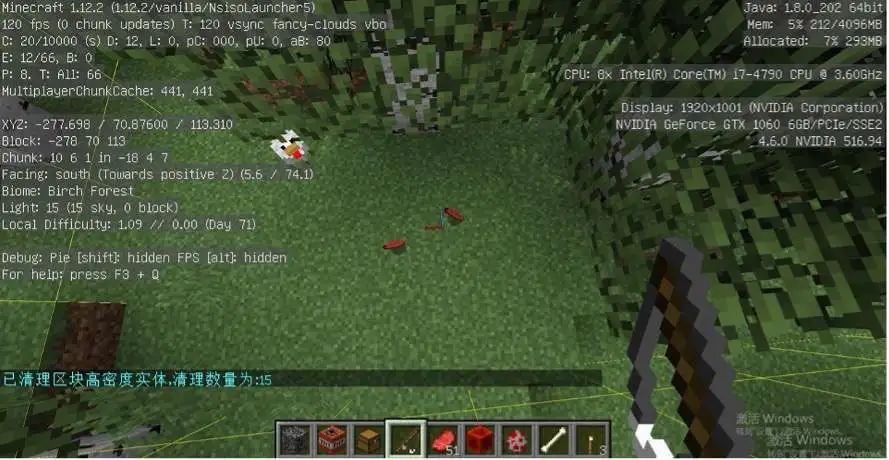
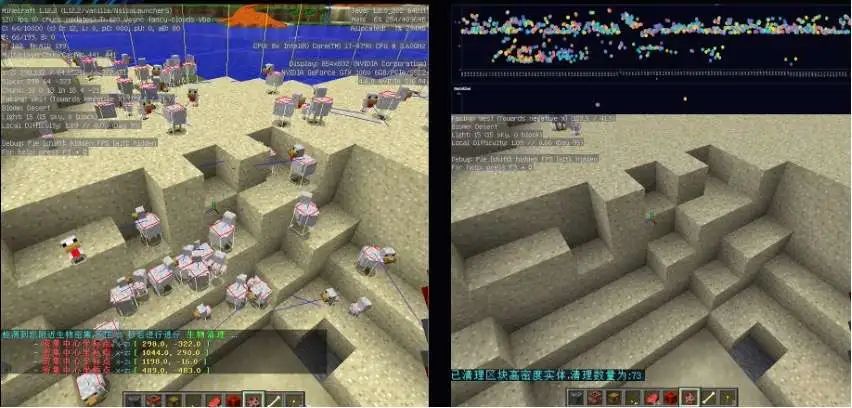
2.5 效果展示

-
服务端将实体坐标信息传给大数据后端,经处理输出到报表系统,实时查看地图生物信息。实现卫星地图效果
 Entity(生物类别)数据的分布
Entity(生物类别)数据的分布
 tileEntity(方块类别)数据的分布
tileEntity(方块类别)数据的分布
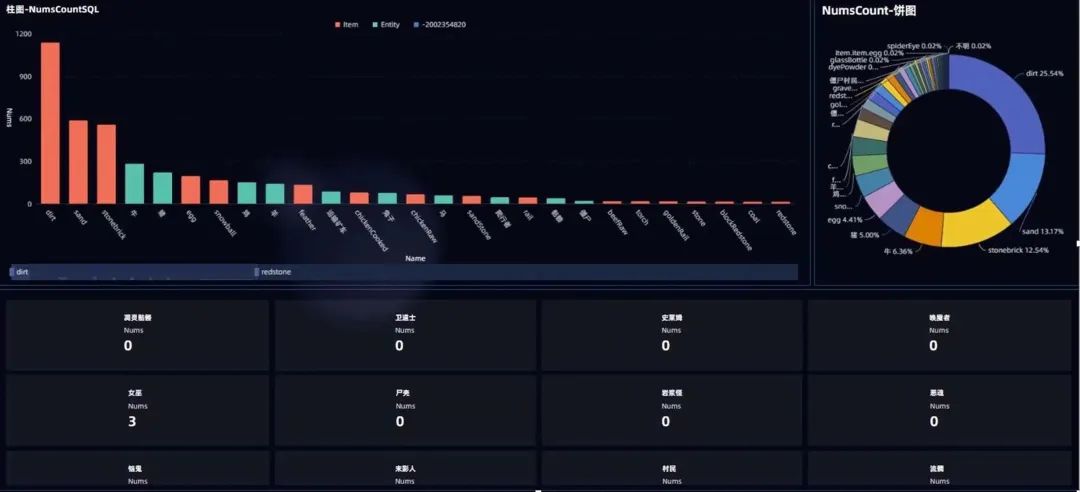 实体数据统计图
实体数据统计图
 如果你有足够的耐心,就可以在服务器里用方块实体摆一幅这样的图出来
如果你有足够的耐心,就可以在服务器里用方块实体摆一幅这样的图出来
结语

-
大型网游的实时任务系统 -
Boss 掉落物的实时调整,物品推荐 -
服务端没法迅速响应的分类回归预测 -
NPC的自然语言处理任务
参考
-
解构流存储 — Pravega(https://flink-learning.org.cn/article/detail/7a9cfcbcf3c01ad0b38a89249cfb7e99) -
MCBBS-插件开发教程(https://www.mcbbs.net/thread-1051397-1-1.html)
本文转载自季军-工一611 Apache Flink,原文链接:https://mp.weixin.qq.com/s/QNQ7GBOa437Cg8PZuvJCXA。