


使用 Apache Iceberg 作为您的数据湖表格式可以实现更快的数据湖分析、时间旅行、分区演化、ACID 事务等。Apache Iceberg 是实现开放式 Lakehouse 架构的关键部分,因此您可以降低数据仓库的成本并避免供应商锁定。
最近,我写了这篇关于将 Hive 表迁移到 Iceberg 表的不同策略的文章。在本文中,我展示了一些实践练习,以演示 Hive-to-Iceberg 的转换如何工作,因此,你可以在将这些技术大规模应用到你自己之前的数据管道。在将现有 Hive 表迁移到 Iceberg 表时,也可以使用这些相同的技术和命令。
流程如下:
-
使用Spark启动Docker容器
-
建Hive表
-
在不重述数据的情况下将 Hive 表迁移到 Iceberg 表(使用 add_files procedure进行就地迁移)
-
通过重述数据将Hive表迁移到Icberg表(迁移使用“Create Table As Select”AKA CTAS语句)

你需要安装 Docker 才能继续实现这个用例。第一步,将使用我创建的名为 iceberg-starter 的 Docker 映像启动一个容器,这将使我们有机会亲身体验 Iceberg。
docker run -it --name iceberg-env alexmerced/iceberg-starter
这会将 shell 放到 Docker 镜像中,然后我们将使用下面的命令打开 Spark,这会在我们的 Spark Session 中配置一个 Iceberg 目录。
spark-shell --packages org.apache.iceberg:iceberg-spark3-runtime:0.13.0
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
--conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog
--conf spark.sql.catalog.spark_catalog.type=hive
--conf spark.sql.catalog.iceberg=org.apache.iceberg.spark.SparkCatalog
--conf spark.sql.catalog.iceberg.type=hadoop
--conf spark.sql.catalog.iceberg.warehouse=$PWD/iceberg-warehouse
--conf spark.sql.warehouse.dir=$PWD/hive-warehouse
分解一下这些配置是做什么的。
--packages org.apache.iceberg-spark3-runtime:0.13.0
这个是 Spark 使用 iceberg 包
--conf spark.sql.catalog.spark_catalog=org.apache.Apache Iceberg.spark.SparkSessionCatalog
Spark catalog 默认使用 V1 Data Source 规范,这个跟Spark V2 Data Source API 不同。在这个设置当中,我们改变了这个实现,将Spark catalog 切换到 V2 版本 Iceberg API,使用 Iceberg 与默认 catalog 交互所需的功能。
--conf spark.sql.catalog.spark_catalog.type=hive
这会将接口的默认catalog实现设置为Hive。
--conf spark.sql.catalog.iceberg=org.apache.Apache Iceberg.spark.SparkCatalog
这个是创建了一个新的catalog 叫做 “iceberg”, 并将其实现设置为Iceberg的Spark catalog。
--conf spark.sql.catalog.iceberg.type=hadoop
这个将 “Iceberg” catalog 设置到基于文件的 Hadoop 实现上。
-–conf spark.sql.catalog.iceberg.warehouse=$PWD/iceberg-warehouse
这个设置了 “iceberg” 这个 catalog 的路径,Iceberg 会将文件写入到 Docker 容器文件系统中的 “~/iceberg-warehouse”。
--conf spark.sql.warehouse.dir=$PWD/hive-warehouse
这个配置告诉以 Hive 表格式存储表的默认 Spark catalog 指向 “~/hive-warehouse”中的表。
现在我们在 Spark shell 中,让我们创建一些 Hive 表来模拟可能在数据湖中拥有的表。
spark.sql("CREATE TABLE people (first_name string, last_name string) USING parquet");
由于我们使用了 USING parquet 子句,因此数据将存储在 Apache Parquet 文件中(数据必须在 Parquet、ORC 或 AVRO 中才能进行就地迁移)。这将创建一个 Hive 表。但是由于我们没有引用配置的“iceberg” catalog 或使用 USING iceberg 子句,它将使用默认的 Spark catalog,该catalog使用将存储在 ~/spark-warehouse 中的 Hive 实现。
向这张表中添加一些数据。
spark.sql("INSERT INTO people VALUES ('Alex', 'Merced'), ('Jason', 'Hughes'), ('Ben', 'Hudson')");
确认一下数据已被添加
spark.sql("SELECT * FROM people").show()
如果我们看到了数据,我们 Hive 就是准备好了在我们运行迁移之前,看下 Hive 表的数据存在哪里。退出 Spark shell
:quit
在我们的主目录中,您会注意到存在新的“hive-warehouse”和“metastore_db”目录。“metastore_db”目录是嵌入式 Hive metastore 元数据的存储位置(默认情况下在 derby 数据库中),而 hive-warehouse 目录是存储数据文件的位置。我们看一下table目录的内容。
ls ~/hive-warehouse/people
这个应该产生类似于一下内容的输出:
_SUCCESS
part-00000-bd527ad5-ff32-4704-af79-329ae4b2d008-c000.snappy.parquet
part-00001-bd527ad5-ff32-4704-af79-329ae4b2d008-c000.snappy.parquet
part-00002-bd527ad5-ff32-4704-af79-329ae4b2d008-c000.snappy.parquet
重新启动 Spark
spark-shell --packages org.apache.iceberg:iceberg-spark3-runtime:0.13.0
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
--conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog
--conf spark.sql.catalog.spark_catalog.type=hive
--conf spark.sql.catalog.iceberg=org.apache.iceberg.spark.SparkCatalog
--conf spark.sql.catalog.iceberg.type=hadoop
--conf spark.sql.catalog.iceberg.warehouse=$PWD/iceberg-warehouse
--conf spark.sql.warehouse.dir=$PWD/hive-warehouse
启动并运行 Spark 后,让我们确认我们的 Hive metastore已连接。通过运行以下命令检查我们在 Hive 目录中创建的表。
spark.sql("SHOW TABLES").show()
现在让我们将 Hive table 迁移成 Iceberg table.
此迁移将使用就地迁移策略,就地迁移意味着我们将保留现有数据文件,并使用现有 Hive 表的数据文件仅为新 Iceberg 表创建元数据。与重写所有数据相比,这可能是一个成本更低的操作。现有的 Hive 表必须将数据存储在 Parquet、ORC 或 AVRO 中才能使其工作,这就是为什么 USING parquet 子句之前很重要。这可以通过两种方式完成:
-
使用migrate procedure: 这会将现有的 Hive 表替换为使用现有数据文件的 Iceberg 表。
-
使用 add_files procedure: 这会将 Hive 表的文件添加到现有的 Iceberg 表中,也使用现有的数据文件。
最为最佳实践,我推荐使用 snapshot procedure,这可以测试 migrate procedure 的结果。Snapshot 可以保持旧的Hive table 不变,因此你要在运行实际 migrate procedure 之前使用它,migrate procedure 会删除老的 Hive table。
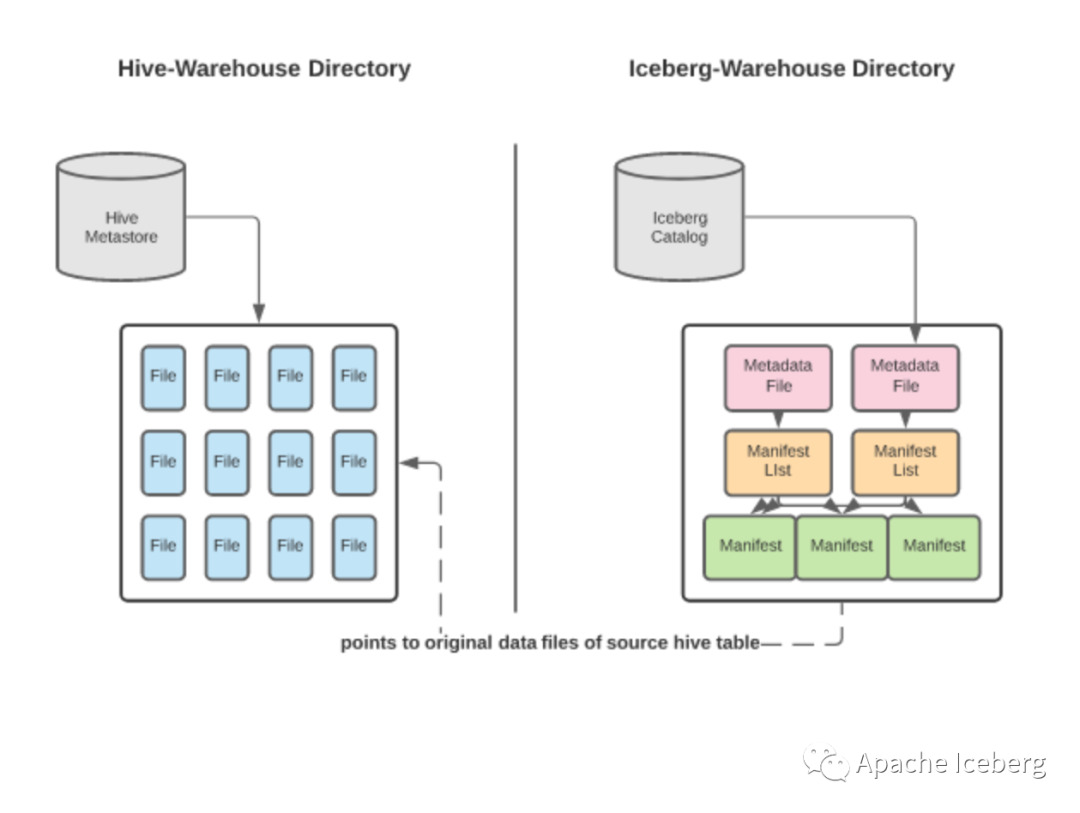
选用就地迁移的作用包括::
-
由于不会重述所有数据,就地迁移会更加的省时。
-
如果 Iceberg 元数据写入有误,只需要重写元数据,不需要重写数据。
-
数据沿袭得以保留,因为元数据仍然存在于旧的 Hive catalog 中,并以指向数据文件的演进(在 Iceberg 元数据中指向未来数据的演进)
这种方法有以下的缺点:
-
如果在元数据写入的期间,继续有新的数据写入,这就需要重新操作,将新的数据添加的元数据中。
-
为了避免重新操作,就需要停止任务执行,这可能在某些场景下不可行。
-
如果需要重任何数据,这个方法也是不可行的。比如,你想更改表格式或者将数据重新分区到iceberg 表中,这样的话,就需要将数据进行重述。
使用 add_files procedure我们将在本教程中使用 add_files procedure。所有的Iceberg procedures 都可以通过使用下面语法的 SQL 语句调用:
spark.sql("CALL catalog_name.system.procedure_name(arguments)")
在我们使用 add_files 之前,我们需要有一个现有的 Iceberg 表和一个匹配的 schema 来将我们的 Hive 表数据迁移到其中。因此,让我们使用以下命令创建一个 Iceberg 表。我们将使用 CTAS (CREATE TABLE AS SELECT) 语句创建一个与原始表具有相同 schema 的空表。
spark.sql("CREATE TABLE iceberg.db.people USING iceberg AS (SELECT * FROM people LIMIT 0)")
如果此命令抛出错误,请确保之前运行的 SHOW TABLES 查询是成功的。
现在已经创建了表,我们可以运行 add_files procedure,告诉它将数据文件从 people 表添加到 iceberg.db.people 表。
spark.sql("CALL iceberg.system.add_files(table => 'db.people', source_table => 'people')")
现在查询 Iceberg 表确保文件已经被添加。
spark.sql("SELECT * FROM iceberg.db.people").show()
我们也查询一下是否文件也已经归属在我们 Iceberg 表中。
spark.sql("SELECT file_path FROM iceberg.db.people.files").show(20, false)
你会看到这些文件位于存储 Hive 表的“spark_warehouse”目录中,确认该表使用的是原始数据文件,而不是重新创建的,现在两个表都使用相同的数据文件存在。
新的元数据已写入并存储在 Iceberg warehouse 中,我们可以在以下的查询中看到。
spark.sql("SELECT snapshot_id, manifest_list FROM iceberg.db.people.snapshots").show(20, false)
让我们再次将 people 表变成 Iceberg 表,但这次我们将重述数据。这称为投影迁移,因为在迁移过程中,新的 Iceberg 表充当原始表的影子。两个表同步后,您可以切换到 Iceberg 表上的所有工作负载。在这种情况下,我们将根据现有 Hive 表数据文件中的数据在 Iceberg 表中创建新的数据文件。
投影迁移有接下来的作用:
-
投影迁移允许在用户公开表之前审核和验证数据。
-
你可以预先应用任何所需的 Schema 和分区更改。这也可以在迁移完成之后使用 Iceberg 分区演进和模式演进功能进行就地迁移。
-
数据损坏问题不太可能发生,因为可以在迁移过程中对数进行审计、验证和计数。因此,你可以清除旧表中存在的任何不完善的数据,并添加检查以确保所有记录都已正确添加到你的验证中。
也有下面的缺点:
-
存储空间将要暂时的加倍,因为你将同时存储原始表和 Iceberg 表。迁移过程完成之后,你将删除旧表,所以这也只是临时的一个问题。
-
因为正在重写表中的所有数据,所以此迁移方式可能比就地迁移花费更长的时间,所需的时间也是取决于表的大小。
-
要么必须在迁移发生时阻止对源表的写入,要么有一个适当的过程来同步表。
使用此方法将 Hive 表转换为 Iceberg 表就像运行 CTAS 语句一样简单。
spark.sql("CREATE TABLE iceberg.db.people_restated USING iceberg AS (SELECT * FROM people)")
现在这个表存在了,通过查询这张表确认一下。
spark.sql("SELECT * FROM iceberg.db.people_restated").show()
让我们看下这个数据的位置。
spark.sql("SELECT file_path FROM iceberg.db.people_restated.files").show(20, false)
这时文件位于我们 Iceberg catalog 目录 “iceberg-warehouse”中, 而不是Hive 目录 “hive-warehouse”中。这告诉我们写入了新数据文件而不是使用旧文件。
spark.sql("SELECT snapshot_id, manifest_list FROM iceberg.db.people_restated.snapshots").show(20, false)
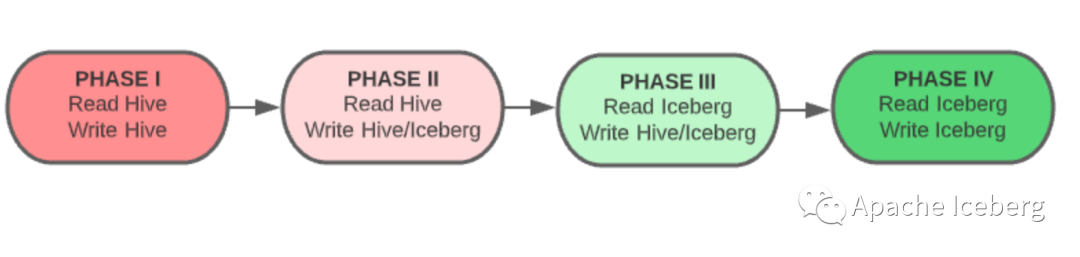
无论你是否重述文件,你现在都会有一张 Iceberg 表,随着演进,这个表具备了时间旅行、版本回归,分区演进等的所有好处。一般来说,你的迁移应该包括四个阶段过程:
-
在流程开始时,新的 Iceberg 表尚未创建或与源表同步,用户的读写操作仍然在源表上运行。
-
该表已创建但未完全同步。读取操作是在源表,写入操作是在源表和新表上。
-
新表同步后,你可以切换到对新表的读取操作。在你确定迁移成功之前,继续对源表和新表做写操作。
-
当一切都经过测试、同步并正常工作后,你可以将所有读写操作应用于新的 Iceberg 表并淘汰源表。
其他重要的迁移考虑:
-
确保你的最终计划对所有消费者都可见,以便他们了解读取或写入数据能力的任何中断。
-
确保新的查询模式有很好的记录,使数据消费者尽可能容易地开始利用新的 Iceberg 表。
-
如果重述数据,在数据被重写时利用并运行审计、验证和其他质量控制。
现在你已经有了将 Hive 表迁移到 Iceberg 表的实践经验,只需吸取经验教训并增强您的数据。如果你使用 AWS Glue,请查看本教程,了解如何使用 Glue 制作 Iceberg 表 : https://www.dremio.com/resources/tutorials/getting-started-with-apache-iceberg-using-aws-glue-and-dremio/
作者:Alex Merced
翻译:许伟
本文为从大数据到人工智能博主「bajiebajie2333」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://lrting.top/backend/12898/