
本期作者

韩建凯
哔哩哔哩资深开发工程师
背景
当前账号系统从研发维护的角度有以下痛点:
账号研发团队支持多条业务线:B站国内版、B站国际版、海外游戏等。但当前每一个业务线都是独立的代码分支,研发的维护成本很高,随着业务线的增加,维护成本成线性增长;其次因为版本比较多研发小伙伴很难熟悉所有版本细节,因此部分业务支撑存在研发小伙伴单点问题;同时多版本对上游接入也非常痛苦,我们共向游戏团队提供了三套API,也被多次吐槽
当前账号系统内部微服务拆分很细,B站国内版账号服务 20+ 微服务,系统架构、领域边界等问题长时间被人诟病
在考虑到账号内部很多不合理的设计在现有系统上维护升级成本较高,我们计划对现有的账号系统进行重构:即账号多租户架构升级,所有业务线使用一套全新的代码,以海外游戏为起点,后续慢慢替换所有业务线。今天就主要是给大家介绍一下,我们账号系统重构之后的架构是什么样的,代码是如何实现不同租户之间的差异的,以及在上线过程中的遇到的一些核心问题
账号架构
系统分析
账号提供的核心能力是认证,同时用户也可以对认证时的账号信息进行管理

用户信息
账号信息要素并不复杂,主要信息如下:
-
基础信息:mid、用户名、密码
-
手机号:用户可以通过手机号+密码、手机号+短信验证码 等完成登录,同时也是触达用户的渠道
-
邮箱:用户可以通过邮箱+密码登录,同时也是触达用户的渠道
-
SNS:主要包含微信、QQ、微博、Google、Facebook、Twitter、Apple,用户通过绑定三方账号可以通过三方认证进行登录
系统能力
为了让用户能够更方便使用以及更好地管理自己的账号,我们提供了一些面向用户的能力
-
注册:生成 B 站账号,用于记录用户数据,同时还可以关联外部信息如:手机、邮箱、SNS互联网账号。
-
登录:用户使用用户名+密码、邮箱+密码、手机号+密码、手机验证码、三方认证等方式来确认用户身份,完成登录,同时颁发一个唯一的token
-
密码管理:用户可以通过手机号、邮箱来找回密码,也可以通过个人中心修改密码
-
手机、邮箱绑定:用户可以绑定手机、邮箱,也可以更换手机号、邮箱
-
SNS管理:用户可以绑定、解绑第三方账号
我们除了提供面向用户的功能之外,我们还提供了服务于业务系统的用户认证能力如下:
-
鉴权:用户登录成功之后,后续只需要 token 信息就可以确认身份,token认证用户是感知不到的,一般是在做一些需要认证的操作时(例:发表评论、发弹幕)请求会带上token,后端服务来账号服务进行鉴权。
当然为了更好地支撑以上能力,我们还有很多边缘的功能,这些功能特点就是他不是单独提供能力给用户,而是服务于以上能力,如下:
-
行为验证码:注册、登录时为了防止刷子,一些操作需要行为验证码校验,主要提供注册和验证行为验证码的功能
-
手机号黑名单:如果被明确为刷子手机号,可以加入黑名单,禁止注册和登录
-
发邮件、短信:在注册或登录时,通过发邮件验证用户身份
根据账号业务边界和业务对象的关联性以及高内聚低耦合的原则,我们把账号划分一下子域
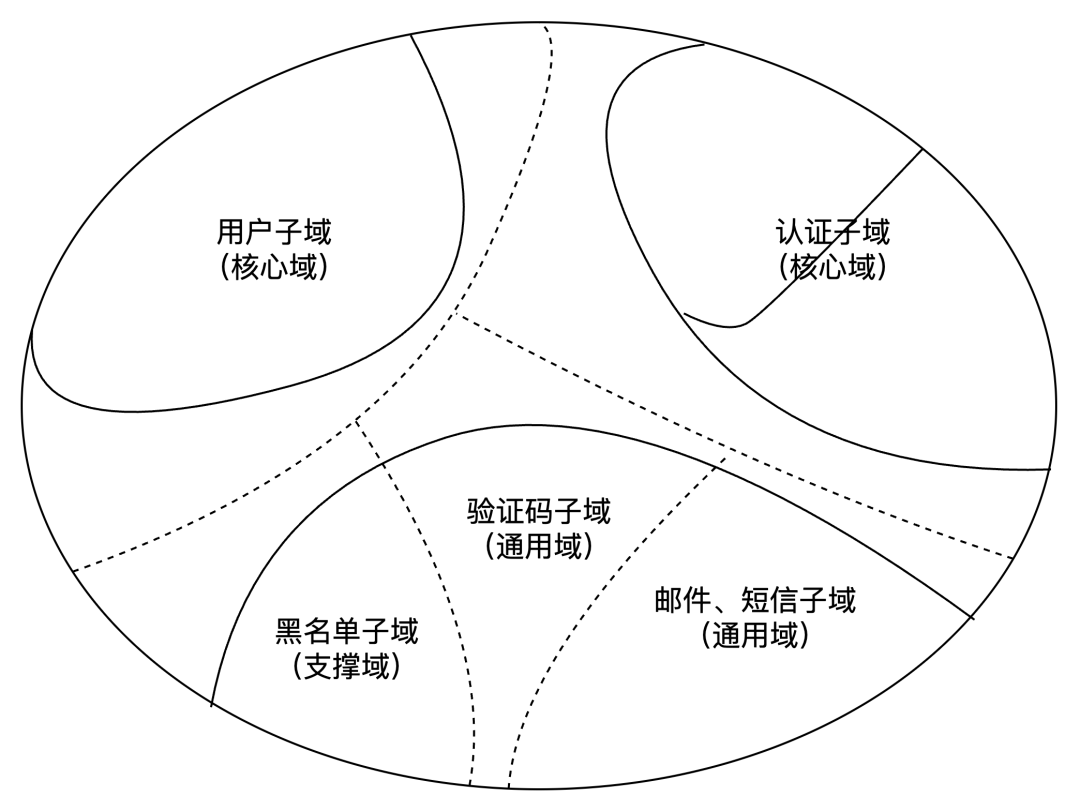
-
用户子域:负责 B 站账户的注册以及账号基础信息(与登录、鉴权相关的基础信息)维护
-
认证子域:负责 B 站账号登录、鉴权。登录和鉴权虽然是两种完全不同的操作,但是都是用来来认证当前操作是哪一个用户,登录之后颁发的 token,后续用户不再需要简化了后续的认证流程。
-
验证码子域:负责登录注册等流程中的验证码注册和展示功能
-
黑名单子域:负责黑名单管理和验证工作
-
邮箱、短信子域:负责短信、邮箱验证码以及消息触达
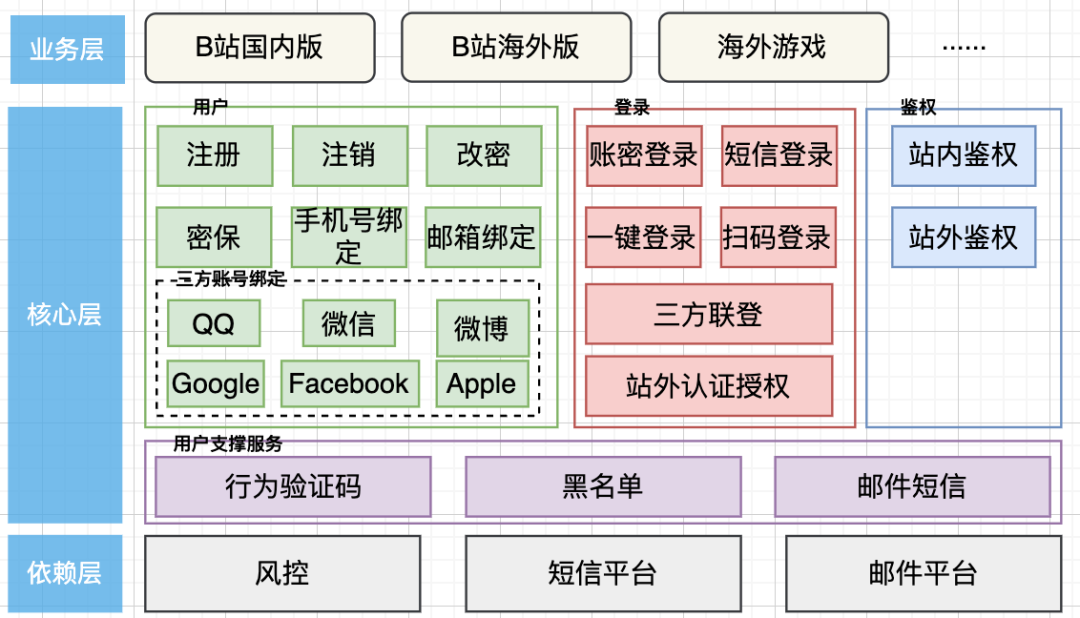
在考虑微服务拆分时,我们既要考虑不同领域之间的依赖关系,同时也要考虑领域未来的扩展能力,以及单个服务的模块是否清晰合理。另外混乱的微服务架构反而会比单体服务带来更大的问题,最终我们把新的架构拆分为4个微服务:用户服务、登录服务、鉴权服务、账号支撑服务,主要考量如下:
-
用户域相对比较独立,主要负责登录、鉴权相关基础信息的维护以及查询工作,我们单独微服务
-
认证域拆为登录、鉴权服务,首先是因为登录、鉴权在流量上差别很大,鉴权流量大很多,运维保障的要求也有一定差别,鉴权服务要求绝对重保;其次从读写分离上看鉴权是读、登录是写。因为两个服务处理的数据是一致的,防止两个服务对数据的操作有差异,我们把对数据的操作抽出了公共模块被两个服务依赖
-
账号支撑服务承接很多子域的功能,a. 这类子域相对比较独立,如果单独微服务会拆的很细 b. 此域是支撑域,也可以把这些域划分到对应的用户、认证两个核心服务内,但是这类功能很碎,放到核心域会使关键服务很臃肿,不够聚焦 。我们参考DDD的战术落地,后续某个子域如果发生了较大发展,我们可以快速独立出一个服务
架构模型
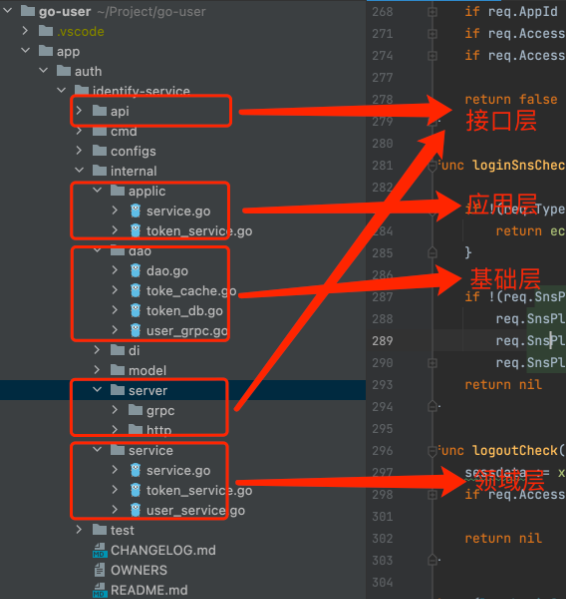
我们基于DDD四层架构模型来指导我们的微服务落地,但DDD对我们研发有相当高的要求,需要整个团队自上而下对架构模型有比较深刻的理解,同时考虑到DDD四层架构模型有很多概念比较繁琐,账号系统并不是那种十分复杂的系统,完全实践反而会提高理解成本,增加维护成本,因此我们基于当前大家熟悉的go工程结构,融合了DDD四层架构模型,做了以下定义:
-
接口层:所有流量入口,接口定义、实现,同时还包括消息的监听,job的触发入口,主要有这些:grpc、http、mq、job
-
应用层:负责流程编排、差异化能力路由。例如登录,应用层就负责以下5个流程节点的串联调度:1. 入参校验 2. 登录次数校验 3. 账密校验 4. 生成token 5. 返回
-
领域层:具体的业务逻辑实现,包含所有租户的能力实现。例:构建token、持久化token、写入缓存
-
基础层:和外部交互的适配器,屏蔽外部特性,转化成应用内识别定义的数据类型。例:持久化token,mysql插入一条token数据即可根据表里所有字段来进行查询,kv(key-value)存储要根据其他字段查询时就需要单独建立二级索引,因此插入3条来保证完整性,但不管基础层如何实现,上层完全不感知。
账号业务架构图
多租户方案
此次重构的一个重要目标就是所有账号体系使用同一套代码,为此我们引入租户的概念,每一个租户都是一套独立的账户体系(如:B站国内版、B站海外、海外游戏等),不同账号体系的差异都最终落脚在租户上
不同租户可能会有以下特点:
-
数据物理隔离:不同租户数据是要隔离的,我们不能允许B站国内版账号登录B站国际版App,也不允许在B站国际版app的登录token能够在B站国内版进行鉴权
-
业务逻辑差异:不同租户使用的能力可能是有差异的,有些是体现在能力上的不同,比如B站国内版不支持Google等三方登录,但是B站国际版支持;有些相同能力内部的小部分逻辑是有差异,比如B站国际版不允许国内手机号登录,而B站国内版可以,这个更多的是在业务校验逻辑的时候有差异
-
外部依赖差异:不同租户所处环境不同,可能会使用到不同的中间件,一些基础组件在国内是有的,但是在海外没有,比如kv国内有,海外游戏日韩却没有部署
如果这些差异我们都是通过代码里if else 来进行实现,那我们的代码会变得很丑陋,随着接入更多账号体系,维护成本会越来越高。那以下我们就详细介绍代码里我们是如何实现多租户差异的
数据物理隔离
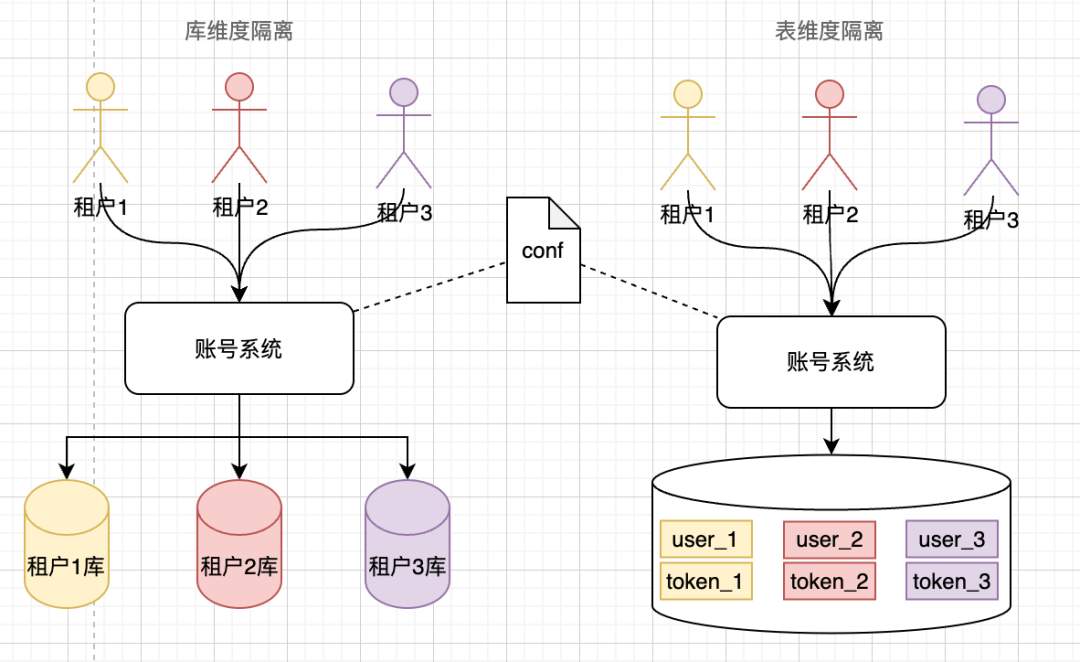
数据物理隔离我们主要提供了两种方案,数据库维度隔离,和表维度隔离,账号系统通过配置来进行持久化数据的选择
库维度隔离:隔离级别最高,安全性最好,适用于数据量以及qps比较大的业务,或者是明确政策要求库维度隔离的业务。当前海外游戏使用的此隔离方案
表维度隔离:不需要申请资源,在现有服务上能快速支持新的业务,适用于数据量以及qps比较小的业务
业务逻辑差异
不同的能力可以使用不同的接口,但是如果是相同的能力,比如登录,比如B站国际版不允许国内手机号登录,而B站国内版可以,我们的方案如下:
-
我们对所有接口进行梳理,把服务抽象成一个个独立流程,每一个流程可以理解为更小的流程节点,流程节点的抽象是要考虑产品本身提供的能力,而不仅仅是考虑某一个租户的逻辑
-
不同租户在同一个能力的逻辑差异体现在具体的流程节点上,再把流程节点抽象成接口,然后进行不同的实现,不同租户根据配置文件选择不同的实现来完成逻辑差异
例子:
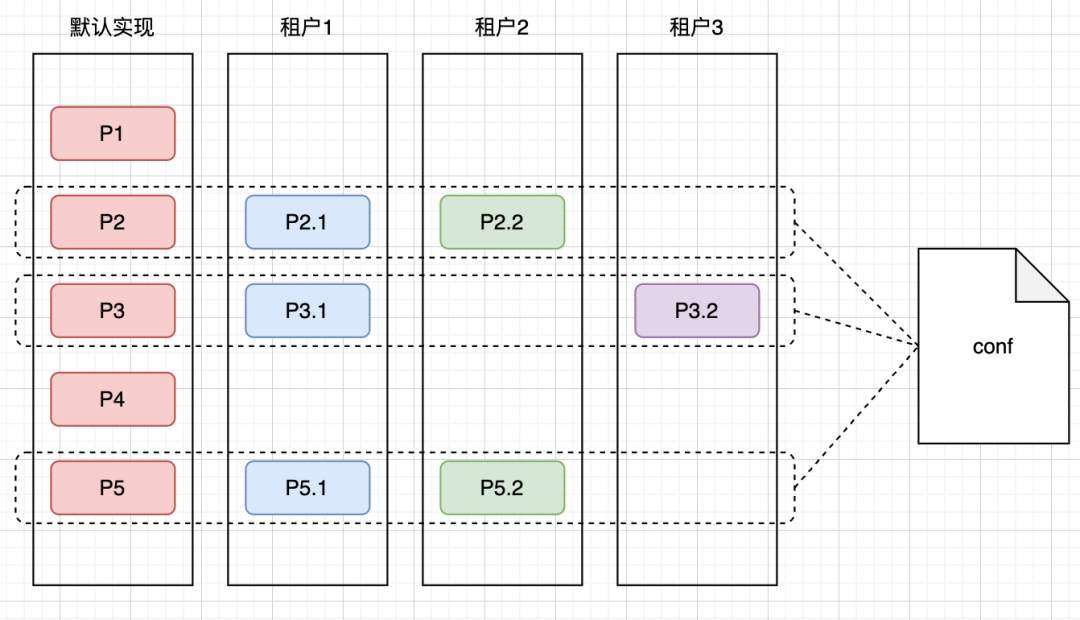
某一个接口我抽象出来流程节点有P1、P2、P3、P4、P5,其中P2、P3、P5不同租户之间逻辑有差异,那么我们就会对其进行接口抽象,针对于如图三个租户选择不同的实现,走不同的链路
租户1:P1、P2.1、P3.1、P4、P5.1
租户2:P1、P2.2、P3、P4、P5.2
租户3:P1、P2、P3.2、P4、P5
下面是我们梳理的B站国内版、B站国际版、海外游戏账密登录的流程节点,其中红色是差异实现,缺失的节点空实现代替
| 序号 |
B站国内版 | 海外游戏 |
B站国际版 |
| 1 | 入参校验 | ||
| 2 | 验证码校验(极验) | 图形验证码 | |
| 3 | 登录次数校验 | ||
| 4 | 用户名密码校验(兼容二次号逻辑) | 用户名密码校验 | 用户名密码校验 |
| 5 | 验证登录管控 | 空实现 | |
| 6 | 验证风控 | 空实现 | 空实现 |
| 7 | 验证常用设备 | 空实现 | 空实现 |
| 8 | 生成token | ||
| 9 | 返回Response |
注:很多时候多租户之间是没有差异的,我们为了防止过度设计,我们没有从一开始就抽象了过多流程节点的接口,而是通过演进的方式遇到有差异时再将流程节点抽象成接口
外部依赖差异
不同租户所处的物理环境不同,依赖的外部资源也可能有差异,比如我们token信息B站国内版存储到taishan (kv存储)里,但是海外游戏台湾、日韩是只能存储在mysql,如何用同一套代码做兼容?
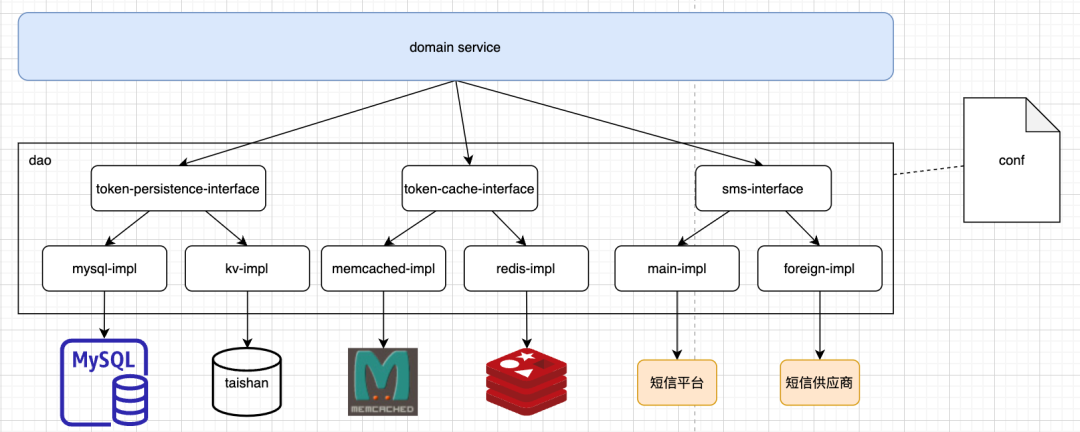
我们的方案是把所有数据的操作、以及外部依赖操作如果有差异都抽象出不同的接口,如上面所说的token信息的存储差异,我们会抽象出数据持久化的接口,分别有mysql、taishan(kv存储)的实现,在执行数据操作时,根据配置选择不同的接口实现来完成操作,领域服务层完全不需要关心存储细节。
典型类图
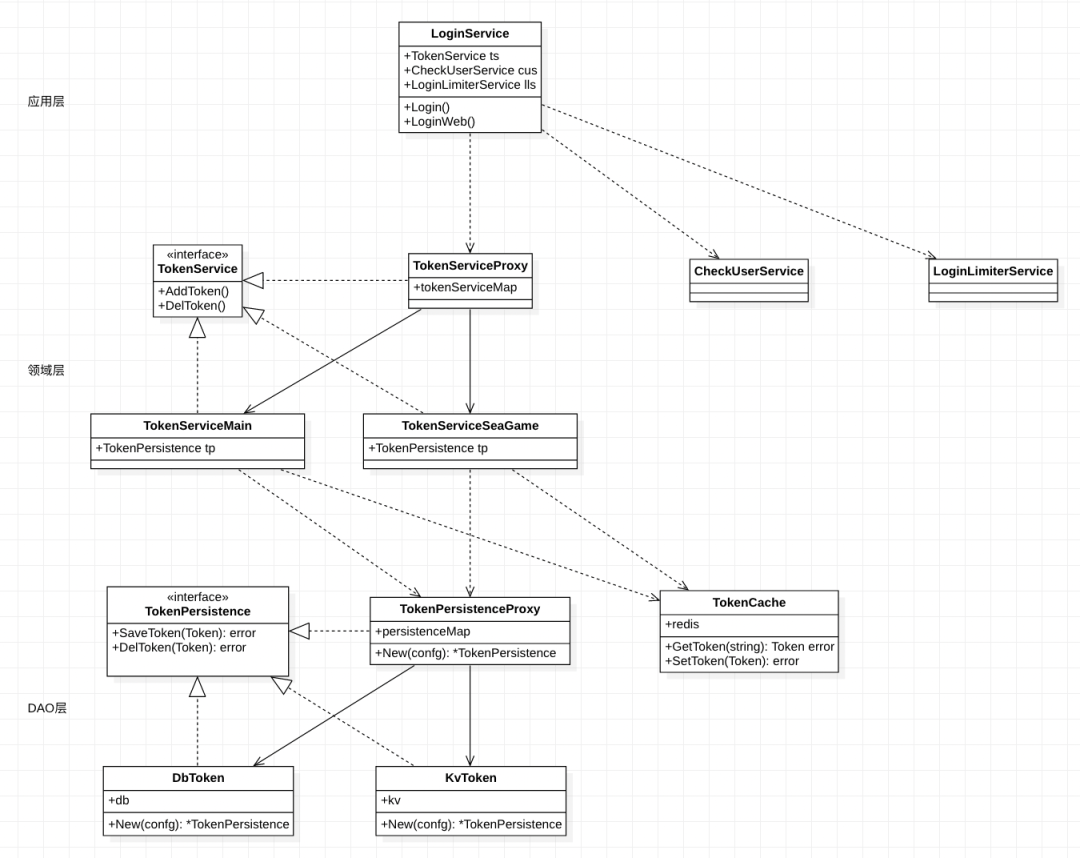
我们在需要差异化实现的地方抽象接口,然后在Proxy实现中根据租户进行路由选择,那Proxy是如何选择的呢?就需要介绍我们的配置化接入
配置化接入
之前我们接入一个新的账号体系时,我们会申请新的服务树,拷贝一份代码仓库,在新的代码仓库上个性化改造,申请一整套资源然后部署。这样做接入成本很高,同时也不容易沉淀能力。多租户账号系统我们把账号体系的接入转换为租户的接入,接入时主要有以下两种方式接入
独立部署
如果考虑到此账号体系QPS、用户数量、服务等级都比较高,服务要求严格重保,我们会采用独立部署的策略,独享服务树和外部资源,但是代码仓库只有一套,如果有个性化逻辑,只需要按照我们上面所说的差异化实现方案来进行实现就好了
共享部署
如果考虑到此账号体系QPS、用户数量、服务等级都比较低,我们可以多个账号体系公用一套资源,这样我们的接入成本会更低,只需要更改配置就可以快速接入,具体配置如下
-
我们把所有的外部资源都定义到一个map对象里,如配置中的DB、Redis
-
然后定义租户配置,租户配置也是一个map对象,key是租户key,value就是具体DB、Redis、流程节点的选择
[][]addr = "172.0.0.1:5805"dsn = "bstar:xxxxxxxxxxxx@tcp(172.0.0.1:5805)/intl"active = 10[]addr = "172.0.0.1:5062"dsn = "main:xxxxxxxxxxxx@tcp(172.0.0.1:5062)/main"active = 10[][]addr = "172.0.0.1:7101"[]addr = "172.0.0.1:7102"[]defaultKey = "main"[]"TokenService" = "TokenServiceMain"[]"TokenPersistence" = "KvToken"[]db = "main"table = ""redis = "main"[]"TokenService" = "TokenServiceBstar"[]"TokenPersistence" = "DbToken"[]db = "intl"table = "intl"redis = "intl"
如果没有新的差异化实现,新增租户时,只要在配置中增加租户配置就可以了,不管是独立部署还是共享部署,都大大降低了接入成本。
系统灰度方案
全新的多租户系统完成之后,我们就要考虑如何完成新老系统的迁移工作,针对于迁移我们给自己定了几个明确的目标:
-
安全:数据不丢,可灰度、可回滚
-
范围可控:上游无感知,减少项目依赖方
-
可监控:尽早感知因灰度导致的数据问题,提早做人工干预
我们整体迁移方案如下:
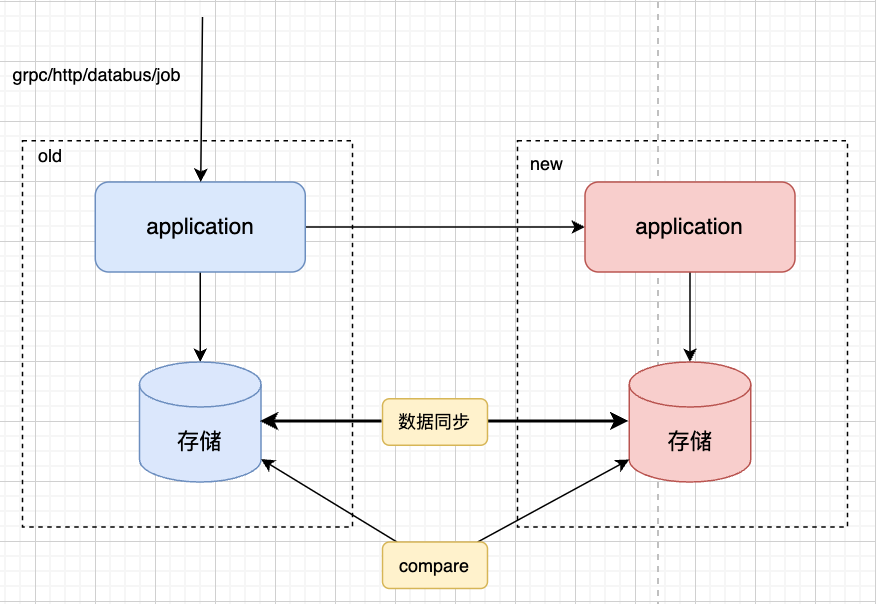
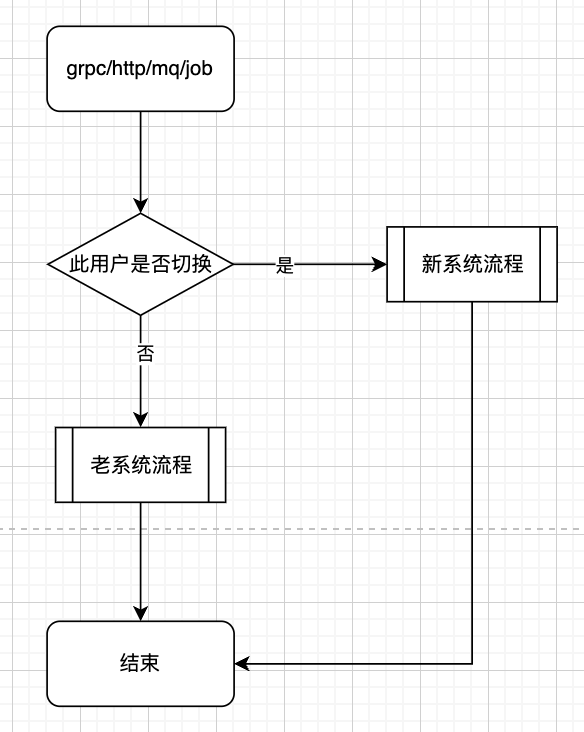
路由
上游系统完全无感知,继续调用老服务,在老服务做路由控制,可以根据接口类型做不同的灰度方式。灰度策略可以根据白名单、百分比进行灰度
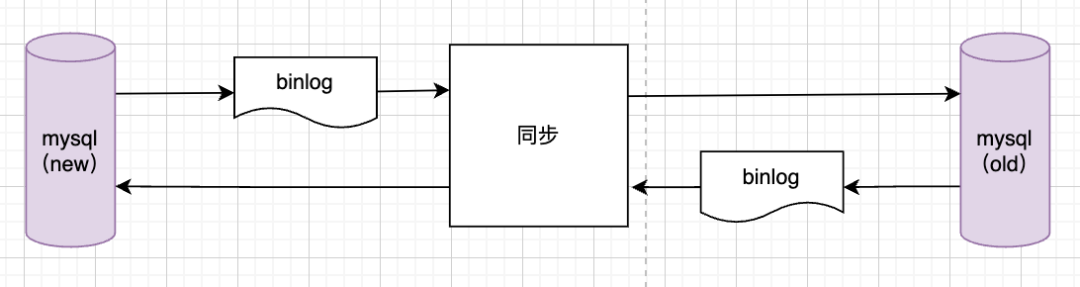
双向同步
新老DB通过binlog双向数据同步,保障新老数据准实时最终一致,保障可灰度、可回滚,新老系统业务逻辑完全不感知灰度状态。同时因为全新设计的新的数据模型和老系统数据模型有很大的差异,同步逻辑要做差异转换
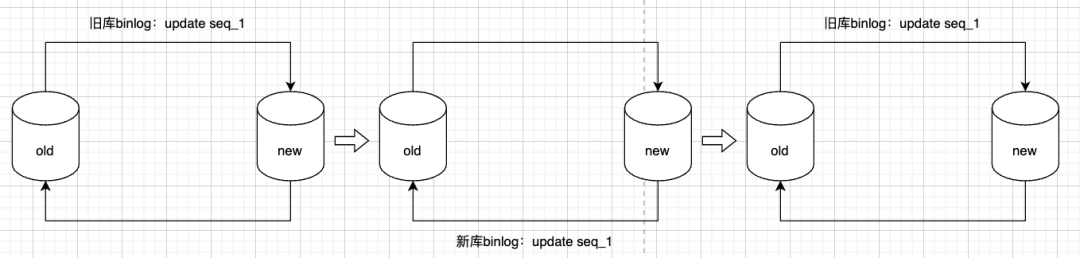
回环问题
数据双向同步就带来数据回环的问题,通常大家熟知的数据传输服务,比如A-B 两个库相互同步,一般是监听到A有事务同步到B,在写入B库的同时也在事务中增加一个固定标识,那么数据传输服务监听到B的事务时会判断一下是否有此固定标识,如果有就不再同步到A了。
但是我们通过监听canal消息只能获得到最新的数据,在A产生一个binlog,同步到B之后也会产生一个新的binlog,如果仍然同步这条binlog的话,就可能产生无限循环。最后我们主要总结如下三类循环为例:
数据更新产生循环:
如下图,此为典型的数据回环,如果不加以处理,seq_1 会无限循环更新下去
解决方案:
我们的方案是所有需要同步的表我们新增字段
sync_time` timestamp(3) NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '同步判断时间';当监听到binlog消息后我们会判断binlog消息中的sync_time 是否大于当前数据的 sync_time,如果大于执行更新
update user_reg_origin set guest=?,join_ip=?,join_time=?,ctime=?,mtime=?,sync_time=? where mid=? and sync_time;插入/删除产生循环:
在短时间内出现一次插入和删除操作,如果insert的消息没有同步结束,这个时候立即删除数据就可能会出现新、旧库不断插入、删除的无限循环。如下图,第2步如果监听的新库的insert seq_1 消息时,旧库数据已经被删除,那么再次插入就能插入成功,然后又会同步到已被删除的新库,出现循环

解决方案:
我们把每一条binlog都作为一条数据变更消息,这条消息处理完成之后增加redis一个标识,监听一条binlog消息后,我们查询反方向这条消息是否被处理过,如果被处理过就直接丢弃,如下图
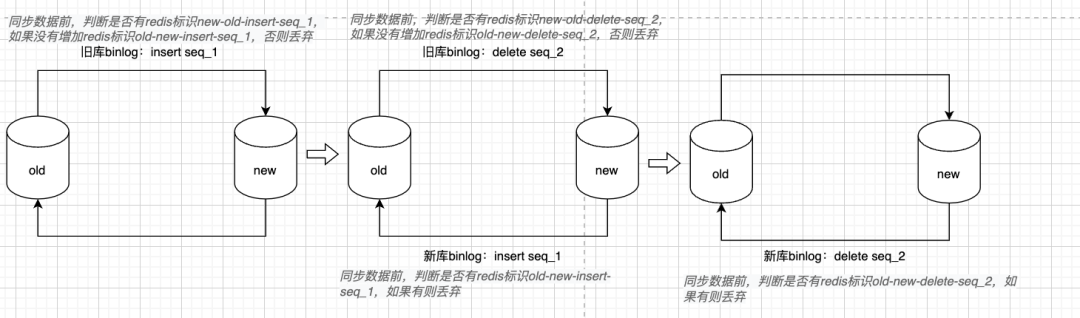
新系统软删除旧系统硬删除、
新系统硬删除旧系统软删除产生的循环
因为在执行更新操作同步的时候发现如果没有数据,我们就把更新之后的数据进行插入操作,如果瞬间再来一次删除,那么就会出现类似上面“插入/删除”循环的场景。
解决方案:
我们把软删除操作转换成对应delete和insert操作,后续策略和“插入/删除产生循环”解决方案一致
数据核对
为了及时发现新老系统数据不一致,我们增加了核对逻辑,主要有两种
数据变动增量核对:监听binlog消息,然后查询新、老库数据是否一致
查询接口返回核对:针对关键接口查询时会查询新老系统,进行比对
核对不一致的数据我们通过监控告警及时发现,但是考虑到数据修复的风险,我们并没有做自动修复,而是通过人工确认之后手工修复数据
未来展望
在当前公司的基础设施环境下,通过Canal来做数据双向同步确实比较复杂,随着公司DTS的建设,后续会考虑把此类同步通过DTS完成,就不需要再考虑数据回环的问题了
总结
多租户的架构升级替换现有的老系统并让业务完全无感知是一个高风险的事情,犹如行驶中的飞机换引擎,并且在海外游戏的替换过程出现了很多我们预期之外的问题,我和我的小伙伴们总结沉淀了问题解决方案,也为我们后续接入B站国内版、B站国际版等业务带来了更多的借鉴和参考。在此期间我们也接入了多个账号体系,顺利并高效地完成了账号能力的支撑工作
以上是今天的分享内容,如果你有什么想法或疑问,欢迎大家在留言区与我们互动,如果喜欢本期内容的话,欢迎点个“在看”吧!
本文转载自 韩建凯 哔哩哔哩技术,原文链接:https://mp.weixin.qq.com/s/7I6q07wVNMJ6UhFWzmKN_g。