


分享嘉宾:屈世超 快看 数据开发负责人
编辑整理:许友昌 浙大中控
出品平台:DataFunTalk
导读:快看在过去经历了业务线以及每个业务线数据体量的极速扩张,我们的数据部门也因此在数据建设和治理方面面临了很多的问题和挑战,过去一年我们进行了闭环的数据治理实践,总结了一些经验,这次很高兴有机会在 DataFun 和大家进行分享。本次分享的重点:
-
治理背景
-
逻辑闭环
-
实践经验
-
总结与展望
01
治理背景
1. 公司介绍
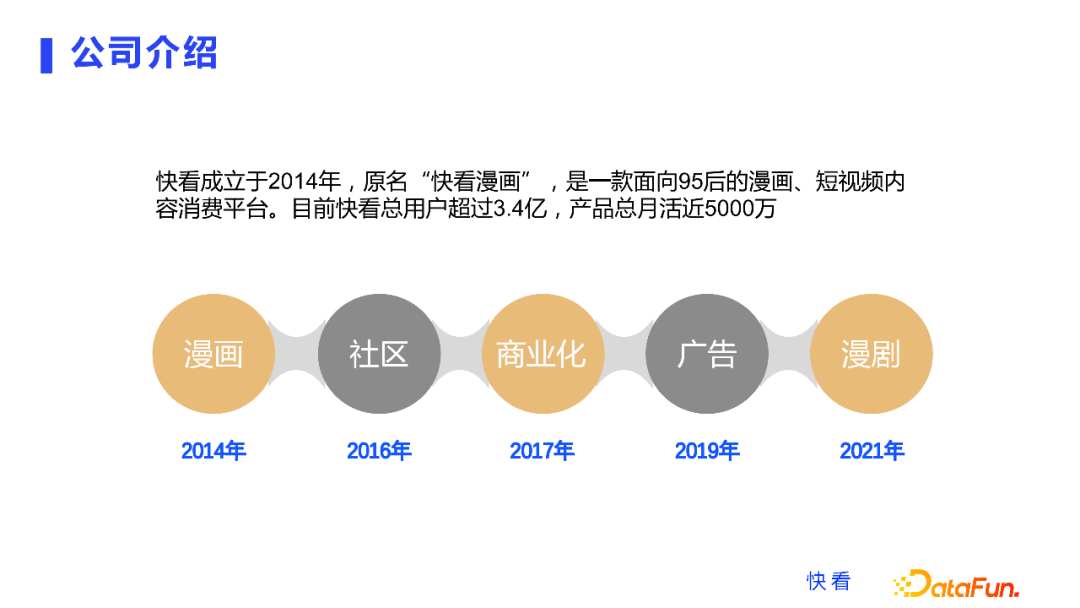
快看成立于2014年,原名快看漫画,是一款面向95后的漫画和漫剧短视频内容的消费平台,现在正在打造 Z 时代的兴趣社区,目前快看总用户量超过了3.4亿,产品各个平台的总月活近5000万,这样的业务规模还是比较大的。
我们的业务线比较多,从时间线来看,包括了2014年做漫画,2016年开始做社区,从 2017 年到现在,商业化又是我们重点发力的一个方向,包括了2019年广告商业化, 2021年快看又宣布品牌升级,从一个漫画平台升级成了漫画加短视频加兴趣社区这样一个综合性的一站式内容消费平台,这是在两个月前进行的产品升级,引入了更多的漫剧短视频形态。
2. 治理背景
公司的发展会带动业务的快速发展,同时也会带来数据建设方面的一些问题,这也是我们进行数据治理的背景。

第一个方面,老业务体量的持续膨胀变大和新业务线扩张带来业务过程与指标维度的急剧增长,给数据的建设和开发带来了很大压力。面对这种情况,我相信大部分公司很难避免烟囱式的开发,需要什么数据就去抽取和统计什么数据,没有去规划长期的数据治理工作。这导致我们的数据十分零散,分布在数仓和大数据平台中,形式上也没有做标准化,质量很差,数据建模没有形成一个规范,导致业务上的开发人效非常低。
第二个方面,我们在一开始很难有足够的人力全面地开展数据治理的工作,数据治理的启动需要一定的动力以及相应的规划,我们需要考虑在现有的数据质量差的情况下,如何既能够支持业务需求,也能够把治理工作开展起来,并且保持边污染边治理的平衡,最终实现数据的治理。
第三个方面,大家都知道数据建设的链路是非常长的,从多源头的数据采集,再对数据进行 ETL 清洗,然后进行数仓建模,以及最后我们对数据应用的管理,因此进行数据治理需要纵观全链路去管理,仅从单点去做,可能收益非常有限,甚至看不到收益。而且,我们业务线多,还会面临跨业务域进行依赖。跨业务域的数据依赖在我们的日常工作中经常遇到,比如我们的漫画商业化业务会依赖漫画内容数据,这样的依赖网络里面,我们切入点可能会比较难寻找,所以治理难度也比较大。
3. 治理路径规划
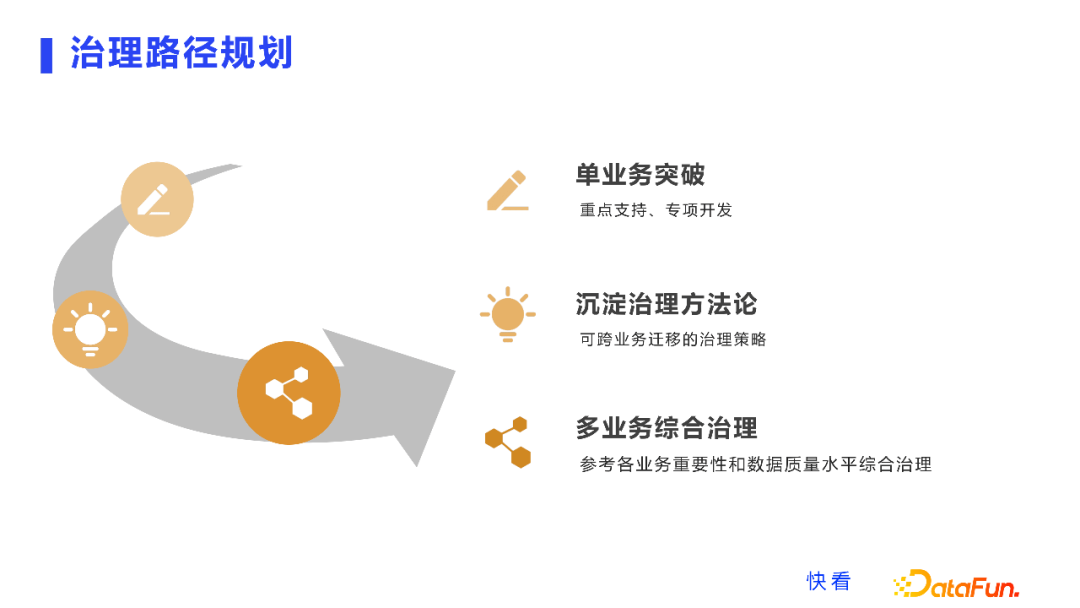
针对以上问题,我们经过讨论之后认为快看业务线繁多,很难保证足够的人力全部在各个业务线同时开展,我们的思路是:
第一步,先从单个业务进行突破,重点支持专项开发当前最核心业务,当然也是我们认为数据质量问题比较大,投入后取得收益会比较大的业务线。
通过第一个业务线的重点突破,第二步,我们期望能够沉淀适合快看数据场景的治理策略,之后进行跨业务的迁移和应用。
第三步,在沉淀完一个MVP的方案基础上,在其他业务上借鉴复用开展数据治理,这样就能够减少在其他业务上从零开始的情况。
这三步就是我们进行数据治理的路径规划。
02
治理逻辑闭环
在这样的治理路径规划下,我们沉淀了一个适合快看各个业务场景治理的框架,也就是治理的逻辑闭环,在实际的方案中主要分为三大块:第一是我们要进行业务范围的管理,第二部分是进行数据资产的治理过程,第三部分就是数据的应用反馈。
闭环是如何形成的一个环的?
数据治理是一个长期过程,如何保证持续性?我们通过一个治理的闭环,建立治理、反馈以及反馈完之后再治理的持续性优化机制。在这个机制中,我们分配相应的人力去重点跟进各个过程,以保证我们刚才提到的对数据进行持续的治理。
为了介绍我们的整体的逻辑闭环,先抛一个问题,如何排空一个蓄水池里的水?这个是大家小学经常做的一道应用题,一个蓄水池有一个进水口一个排水口,进水口以一定的速度进水,排水口以一定速度排水,怎样能够排空它?
首先前提是排水口一定要比进水口的速度快。刚才也提到我们现在是边污染边治理,我们需要保证数据污染的速度是要小于数据治理的速度的。对于蓄水池这个例子来说,就需要对于入水口进行限流限速,对排水口进行提速,其实这样就引出来了我们的逻辑闭环的一个基本数学原理,也就是在数据治理的过程中,要保证数据污染的速度在经过治理之后是越来越小的,而数据治理的速度是越来越高的,这样才能保证数据治理的越来越好。
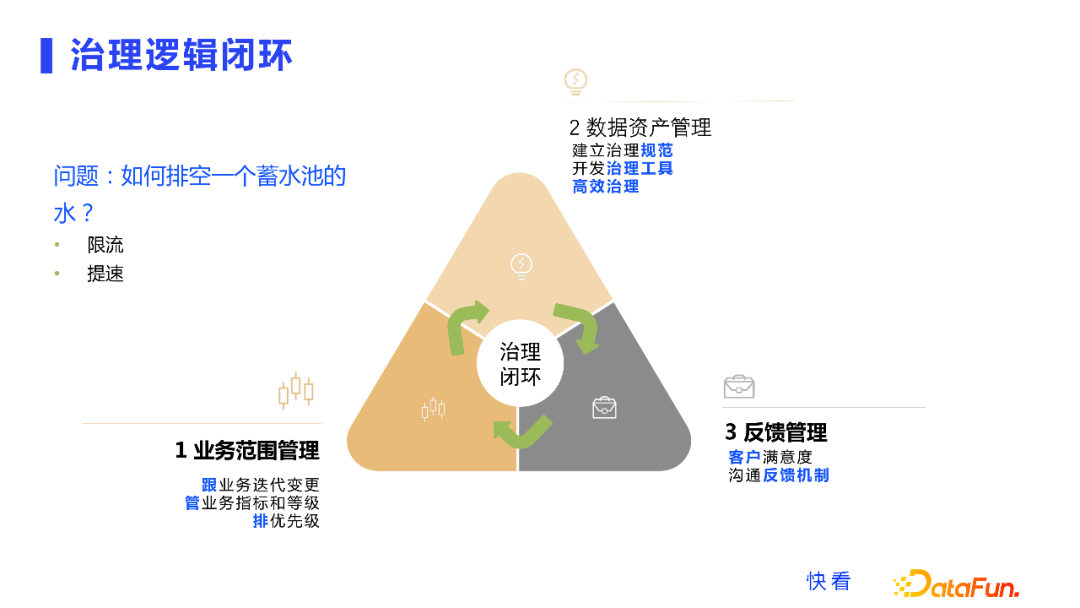
第一部分是业务范围管理,也就是跟进各个业务的迭代变更,业务有哪些变化?增加了什么功能?删除了什么功能?或者功能有什么变化?第二部分是管理业务指标和等级,第三部分对业务过程进行优先级排序。
为什么要做业务范围的管理?
拿我们的一个商业化业务来举例,我们会做很多商业化模式的探索,会有很多子模块的尝试,比如分销、IP拓展和变现。进行这种尝试,对于我们数据这边来说,往往会有滞后性,进行业务过程的探索和我们数据建设和治理的过程不是同期进行的,往往存在的情况是优先探索功能,当 MVP 探索出来,发现 ROI 为正之后,会进行业务过程的放大,同时会对我们的数据指标和数据提很多需求。如果前期我们没有跟进,后期一旦接到这种需求,对于数据来说是比较被动的。
所以我们认为,在治理的第一个阶段,我们需要能够把业务过程的范围跟起来,把业务过程跟起来之后及时同步给数据建设、数据治理团队,尤其数据建设团队,让他们能够及早地跟进业务过程,以及底层数据源,比如业务数据库的一些变化,提早进行筹备。另外,我们也要对新业务过程和老业务过程的业务指标进行管理,因为在业务探索过程中,一旦有变化,可能会提出一些重复的业务指标,或者一些非核心非必要的指标。对应到前面例子中的进水口,我们要对进水口进行限流,限流就依赖于我们对业务范围、业务指标进行管理和等级的排序,这部分工作由数据产品和数据分析师团队共同去做。
第二部分是数据资产管理,就是建立数据治理的一个规范,开发数据治理的一些工具,最后基于规范和工具,对各个业务的数据,尤其是核心业务去进行高效的治理。
为什么要加一个反馈管理机制?
数据治理是一个长期的过程,而且数据很容易被污染,在数据同步采集的过程中,对这些脏数据缺乏鉴别和筛选,后续可能就会产生问题,所以需要一个反馈管理,这也是治理逻辑闭环进行持续性迭代的一种问题收集方式。我们治理了数据,希望用户能够把它用起来。我们的用户包括业务开发同学、分析师、数据产品,以及业务产品等。对于他们的满意度、使用中遇到的问题,我们要建立一个沟通反馈的机制,保障这些问题能反馈提给我们,这就是一个闭环。
闭环总结:
在业务上把源头跟起来,尤其做业务过程、指标优先级方面的管理,根据管理好的这些业务过程和指标的优先级,借助工具和规范,有序、有规划地去做好数据业务的治理,这个规范是需要沉淀的。最后治理完了,数据使用中会有持续的反馈,根据反馈,再去做持续的治理。
03
实践经验
我们花了半年多的时间整理出来这个闭环,同时使各个岗位角色配合起来,去进行闭环的落地。在落地的过程中遇到很多问题。这部分将介绍闭环落地过程中,我们都采用了什么样的方式。
1. 业务管理范围
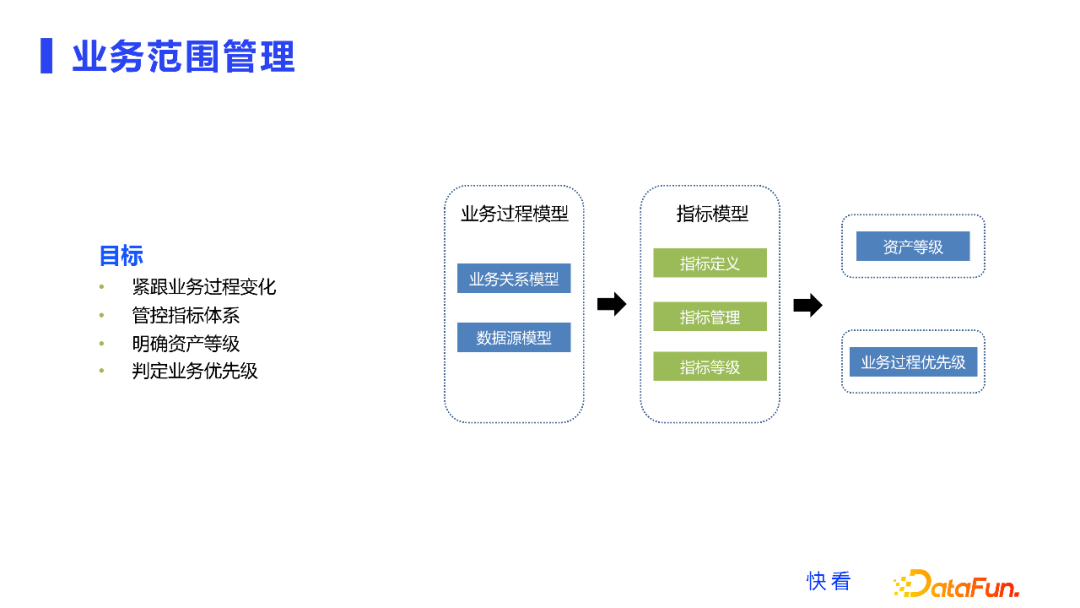
先看业务范围管理这一块的架构。
首先业务范围管理的目标,是保证数据侧能够紧跟业务过程的变化。然后根据指标体系的指标等级,明确这些业务过程、数据资产的等级是什么,我们还可以根据指标的优先级去判定业务需求的优先级。
我们的业务过程模型思路是:
首先在业务范围管理的过程中,建立业务过程的模型,业务过程模型包括了业务关系模型以及数据源模型。我们内部落地了一些规范机制去跟进业务过程的变化,比如数据产品分析师,以及个别开发同学,有职责在业务需求的评审过程中去了解需求的变化、业务的变化,然后我们把变化整理到业务关系模型中(其实就是整理到内部的知识库文档中)。业务变化有可能是底层数据源的变化,数据库的库表结构的变化,甚至取值的变化,我们也都实时地收集到,这是我们业务范围管理的第一步。
下一步是指标模型的管理。首先是对新业务和老业务指标的定义和维护,然后对指标进行管理,包括指标的合理性、有效性、优先级、是否重复,我们不希望业务的指标库无限扩大,而是希望它是有序有意义的,同时指标管理还会进行等级管理,不同业务的不同指标的等级肯定是不一样的,我们需要和业务方一同去维护,确定下来。我们把业务过程维护好,然后把业务过程对应的指标库、指标模型也建设起来,这其实就可以了解业务所有模块数据资产的等级,一般可以根据指标等级去推测。另外我们也能够知道业务过程各种需求的优先级分别是什么。
这就是我们业务范围管理这一块的框架和思路。这个过程目前是以团队知识库的形式去维护的,指标管理是通过数仓管理后台系统进行管理,业务过程和资产等级等以 WiKi 形式去维护。
2. 数据治理规范和架构
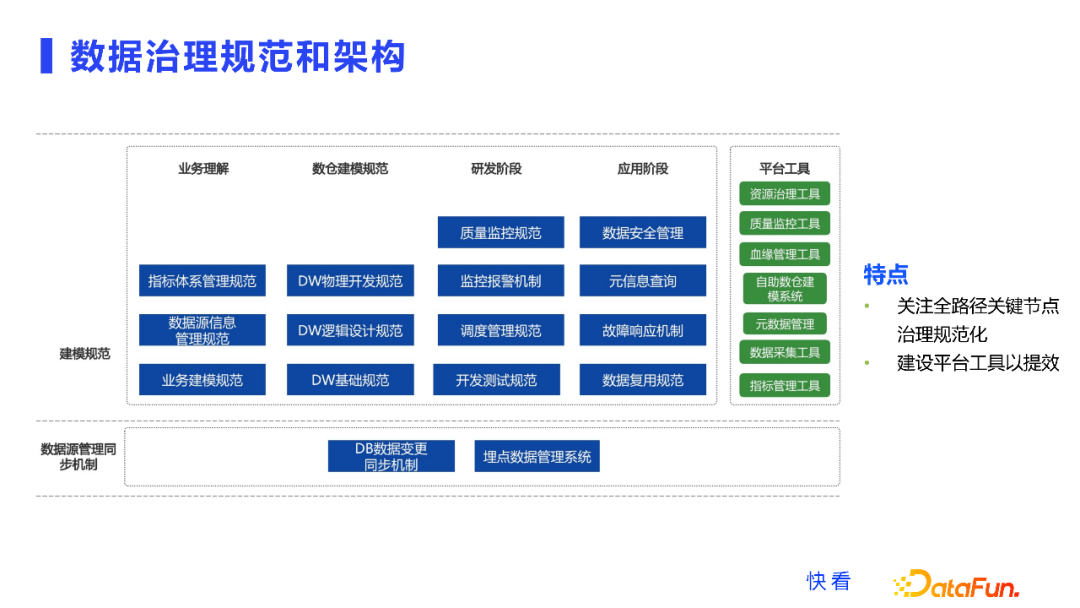
逻辑闭环的第二步,数据治理。数据治理非常依赖全链路关键路径节点上进行的规范化,因为我们的数据链路非常长,需要把全链路上比较关键的节点进行规范化建设,包括治理各个阶段的规范、流程、要求等,同时我们还会需要建设数据平台的工具,来对整个过程进行提效。
上图中蓝色部分是我们各个链路节点规范化的建设,绿色部分是平台提效工具的建设。数据源是我们的基础,它的准确性决定了数据治理的有效性。第一部分是 DB 数据变更的同步机制,在我们工作中经常遇到业务数据变更了,但是没有通知到我们,采集到的数据可能只是历史的某一部分数据,如果没有及时更新,出的数据会有质量问题。
另外,对于埋点数据进行管理也非常有必要。快看做了一个埋点数据的管理系统,对数据进行统一的采集上报,对它的格式规范、数据质量,进行了各种监测,保证了我们的埋点数据的质量。
再往上就是采集完数据之后,数据建设和治理的阶段,我们要了解业务,要对业务进行建模,因此需要业务建模规范、数据源信息管理规范。另外,指标体系也需要进行管理,这是我们的业务理解部分。
再往右看,是数据建设和数据治理实施的流程。
按照流程来,再往右就是数仓建模的规范,数仓建模的基础规范、分层规范、分层依赖规范,这个是我们去共创落地的。另外就是数仓逻辑设计和物理开发阶段的规范,我们如何根据业务过程、指标、业务需求,去设计不同分层更高效的表结构,包括维表、事实表、汇总表,去支撑更多的业务诉求。
再往后就是开发阶段,对于业务需求、业务指标以及业务数据的建设,需要有相应的数仓开发测试规范,以及任务调度管理的规范,对于任务的监控报警机制以及数据质量的监控,都要规范化。
数据开发完后,是应用阶段,我们需要评估数据的复用性,这块有相应的机制去保障,比如故障响应机制,这是保障用户体验非常重要的一个点。另外就是给业务方提供原生数据源信息的查询时还要做好数据安全的管理。
最后是平台工具,平台工具是我们根据实际需求做的 MVP 模型,比如指标管理工具、数据采集工具、元数据管理工具以及自助数仓建设的系统,通过可视化的方式去建设我们的数仓,还有血缘管理工具,质量监控工具和资源治理工具,这些都是根据实际需求去做的,尽可能对我们的开发、数据治理进行提效。
3. 协作技巧
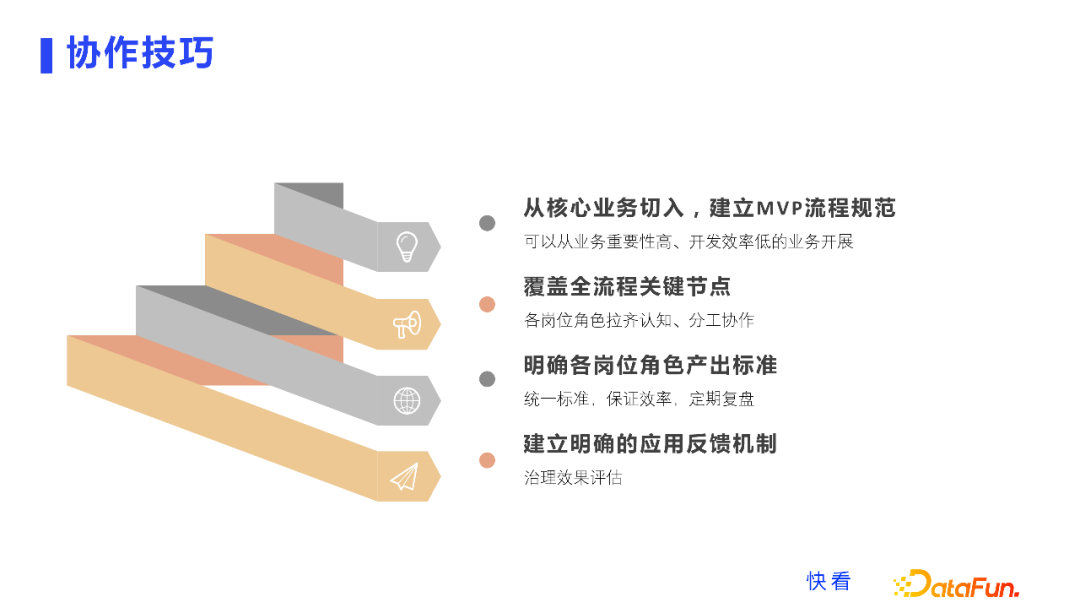
数据治理的链路很长,它需要数据产品分析师、开发同学,以及业务同学进行很好的协作。在这个过程中,需要我们能够从更高的视角,把这些团队协作起来,我观测到这是数据治理工作成败非常核心的一个点,而且从行业交流里面也发现这是很多公司的数据治理没法开展的一个原因。产品侧没有意识到这一点,不去配合,没有拉齐这方面的认知,数据开发同学就没有办法全力投入。因此需要覆盖全流程的关键节点,需要各个岗位角色拉齐认知、分工协作。在各个团队各个角色拉齐认知之后,我们要用一个闭环思路持续的去跟进,需要找一个切入点,在人力有限的情况下,建议从核心业务切入,建立MVP的流程规范,从重要性高、开发效率低的业务开展,能够让各个团队参与进去之后,快速地看到效果。最后明确我们各个岗位角色产出的一个标准,统一标准,保证效率,然后大家定期复盘,最后建立明确的应用反馈机制,去进行治理效果的评估和量化。
这就是我们的协作技巧。
04
总结与展望
1. 治理效果评估
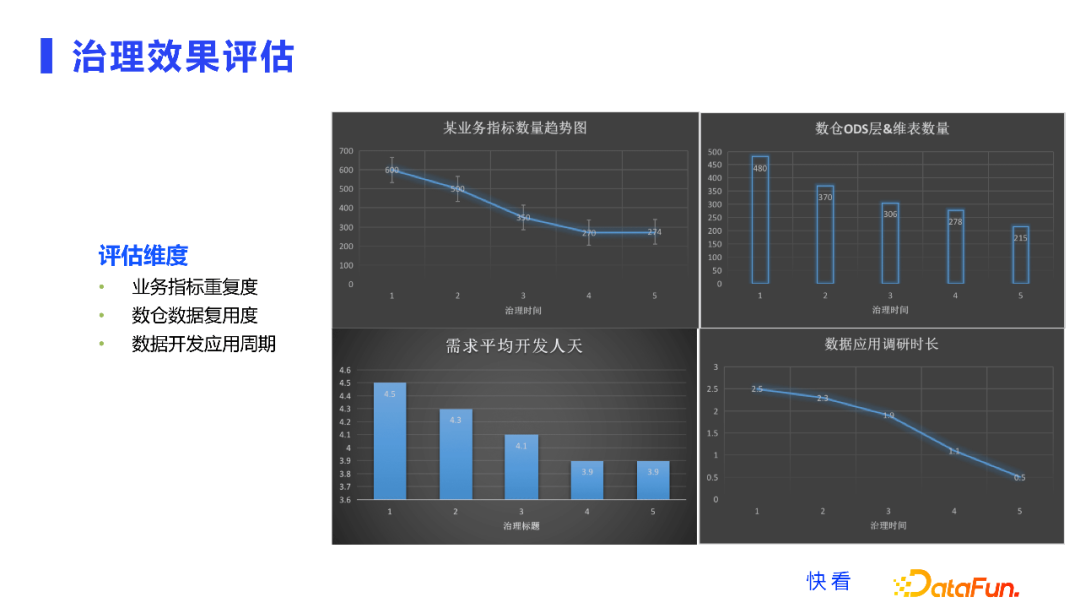
快看这边根据我们面临的问题,从三个维度进行效果评估:
-
业务指标的重复度:这在过去是非常严重的问题,指标非常多重复度也很高。
-
数仓数据的复用度:各种宽表的复用性,它对需求的cover程度有多高。
-
开发应用的周期:在上图大家可以看到,业务指标通过治理,持续削减,并且最后相对稳定。当然随着业务变化、业务过程的变化,它可能还会增,但是管理起来之后就能减少很多不必要的指标。我们数仓的各层数据和维表相关的数量,以及它的复用性,也能够得到明显改善。最后需求开发的人天和数据应用的调研时长,也持续下降。因为我们的数据地图更清晰了,大家使用数据、查数据、对数据口径确认也更快速。
2. 不足与规划
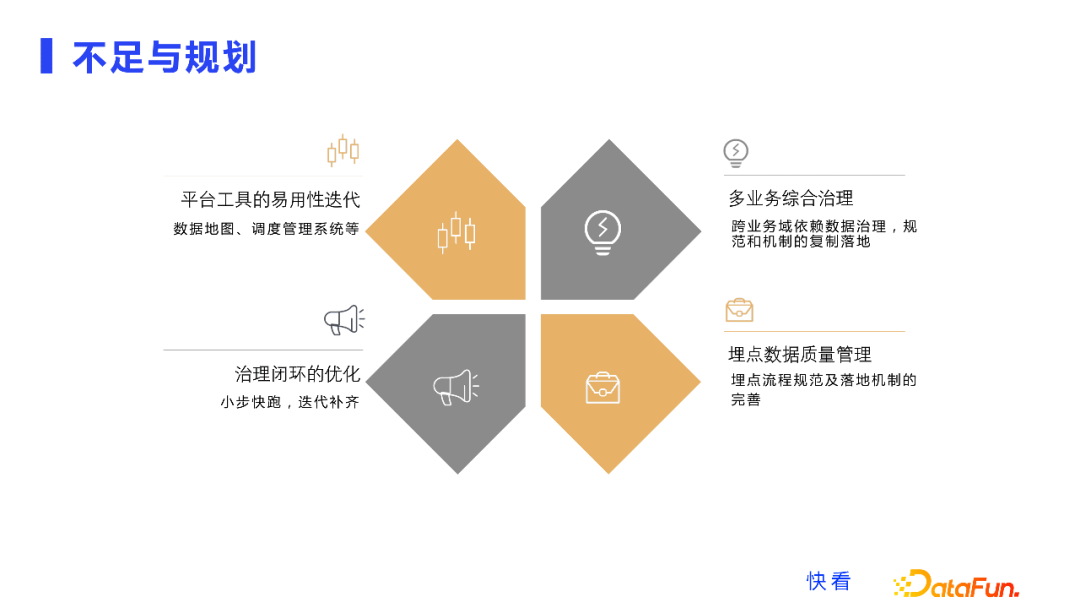
因为人力原因,我们的平台工具迭代较慢,平台工具都是MVP最小的模型,比如数据地图、调度管理,目前还存在一些不便性,需要我们投入更多人力去做。
第二点,我们多业务的综合治理,也就是跨业务域依赖治理,虽然有了一些规范和机制,但并没有在所有业务开展,需要后续去推进。
另外是持续优化,我们的策略是小步快跑,迭代补齐,刚才提到的三个步骤中的各个规范,它的框架都在不断完善中。最后是一个细节点,我们提到的数据源里面,埋点数据质量的管理,它的流程规范和落地机制,我们也在大力的去跟进完善,这毕竟是我们数据质量的一个源头,目前取得了一定效果,但仍需要去进行业务侧的推进和落地。
05
问题
Q:血缘节点规模现在是多大?用的是图数据库吗?
A:我们血缘关系这一块做了一些建设,但是还没有到一个非常完善的地步,我们用的存储结构也没有用图数据库,现在主要还是存储在 mysql 里面,规模基本上是每天有几千个任务,会进行任务血缘的关联,对于它的存储和使用性能目前没有遇到什么问题。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
01/分享嘉宾

屈世超
快看信息科技有限公司数据开发负责人
大连理工大学计算机专业硕士,曾就职小米、EverString,对微服务架构与开发和数据开发架构有丰富经验。现担任快看漫画数据开发负责人,带领团队从0到1搭建了数据架构和中台体系。
本文转载自屈世超 Flink,原文链接:https://mp.weixin.qq.com/s/nKV_Pi-4mWtd2eiSZrIhLw。