胡梦宇 知乎大数据基础架构开发工程师
贾承昆 知乎大数据基础架构负责人
陈 曦 知乎大数据基础架构开发工程师
1. 前言
纠删码(Erasure Coding)简称 EC,是一种编码技术,通常被用于 RAID 和通信领域来保证数据的可靠性。采用纠删码编码的文件通常称为纠删码文件或者 EC 文件,EC 文件在小部分损坏时,也能够解码出可靠的数据。
作为当前最流行的分布式文件系统之一,数据的可靠性是 HDFS 面临的首要问题。在 Hadoop2 时代,HDFS 的数据可靠性是通过冗余副本实现的,为了保证某一文件的可靠性,通常要付出原文件几倍(通常是 3 倍)大小的存储。随着数据量的不断增长,冗余副本将会带来巨大的成本开销,为了降低冗余数据成本,HDFS 在 Hadoop3 上引入了纠删码技术。
HDFS 常用的 EC 编码分为两大类,XOR 与 RS,根据其选择的参数,节省的存储的比例也不同。以 HDFS 默认的 EC 编码方式 RS-6-3-1024K 为例,采取此方式编码的文件相比于三副本,最高可节省约 50% 的存储。
2. EC 策略
2.1 EC 的限制
虽然 EC 技术节省了十分可观的存储开销,但是在使用中也存在不少问题。
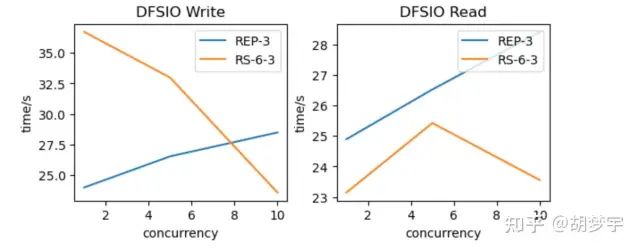
一方面是性能问题,以 RS-6-3 为例,每个文件块由原来的 3 副本变成了包含 9 个 Block 的 Block Group,而且这 9 个 Block 必须分布在不同的机器,每次读操作至少需要 6 个 Block 才能还原数据,也就是至少需要 6 个 DN 同时返回,数据才能被正常解析;而在 3 副本模式下,一个 DN 上就有完整的 Block,只需要最多 1 个 DN 返回就可以读取,所以 EC 在生产中可能会放大 DataNode 的请求量,带来额外的负担。另外如果数据块有损坏的情况,读取后还需要对数据做还原,这部分也需要消耗算力。我们使用 DFSIO 对 EC 的读写性能进行了测试:
-
在低并发的情况下,EC 不论读写性能都比 3 副本要差
-
随着并发逐渐增加,EC 打散副本部分的优势开始体现,整体耗时会更短
 另一方面,EC 文件不支持修改,从 HDFS API 的角度看就是不支持 append 和 truncate 操作。因此对于正在写入或者有可能被追加的目录,不应该采用 EC 编码,避免错误,该场景在 Flink 实时写入数据时较为常见。
这些限制我影响我们的 EC 策略偏好:我们倾向于对较冷的数据进行 EC,以减少频繁读取/刷数对集群的影响。
另一方面,EC 文件不支持修改,从 HDFS API 的角度看就是不支持 append 和 truncate 操作。因此对于正在写入或者有可能被追加的目录,不应该采用 EC 编码,避免错误,该场景在 Flink 实时写入数据时较为常见。
这些限制我影响我们的 EC 策略偏好:我们倾向于对较冷的数据进行 EC,以减少频繁读取/刷数对集群的影响。
2.2 冷热文件分级
EC 技术在应用于生产中,面临的首要问题就是将数据进行冷热分级。
知乎的冷热文件分级由文件的三个特征共同决定:产出时间,访问时间,访问频次。
产出时间:文件的创建时间,如果文件中途有修改,以最后修改时间为准。近期产出的文件一般会参与下游 ETL 计算以及在 adhoc 查询中被反复读取,所以产出时间较近的文件一般都会标记成热文件。
访问频次:有些文件虽然产出时间较近,但是它的使用频率很低,比如有些 Hive 表的文件只是在线数据库的天/周/月级的备份文件,在一般情况下并不会读取它,这类文件可标记成冷文件;而有些文件虽然产出时间较为久远,但是每天都有较大的访问量,这类文件明显就是热文件。
访问时间:有些文件在创建后,只在创建后的一段时间内访问频率较高,过了这段时间,访问量断崖式下跌,这类文件在不同的时期具有不同的冷热分级。
结合文件的这三个特征,我们的冷热文件分级策略可简单描述为,产出时间超过 i 天,并且在 j 天内读取频次小于 k,我们就会将其标记成冷文件,其余文件均视为热文件。其中 i,j,k 为可变参数,不同的目录或者 Hive 表的分区可根据用户的需求设置不同的参数。
文件产出的时间可以通过 fsimage 解析出来,文件的访问频次可以通过 NameNode 的 audit log 统计,但是要注意 audit log 统计的时候,元数据请求如 getFileInfo 等不算作读取请求,只有 getBlockLocation 才算。
fsimage 我们会每天产出一份落入 Hive 表中, NameNode 的 audit log 我们会采集到 Kafka,通过 Flink 实时落入到 Hive 表,通过这两张表,我们可以计算出符合 EC 策略的目录和文件。
2.3 文件转存 EC 方式
目前 HDFS 没有提供将文件转换为 EC 文件的方式,常见的方式是利用 cp 或者 distcp 将文件重写到 EC 目录,再替换原文件,流程如下:
(1)创建一个临时目录,设置此目录的编码方式为 EC;
(2)拷贝需要转 EC 编码的文件到临时目录,并且设置新文件的权限,owner,group 等元信息,使其与原文件相同;
将文件转为 EC 格式可以按照文件粒度或者目录粒度来做。这两种方式的优缺点比较如下:
(1)首先是小文件的问题,对于小文件来说,进行 EC 编码后,不仅不能降低存储开销,反而会增加存储开销。下图是大小为 1M-20M 的文件通过 RS-6-3-1024K 编码后的大小,仅供参考。
相比于按照目录粒度做 EC 编码,按照文件粒度做 EC 编码可以精确跳过小文件,只对大小符合要求的文件进行 EC 编码,这样能尽量多的节省存储。而按照目录做 EC 编码就只能粗略地依据目录的平均大小来做。
(2)其次是在新旧文件替换时,按照文件粒度做 EC 编码时,可以利用 HDFS 提供的原子 rename 接口 overwrite 原文件,可以避免很多问题,而按照目录粒度做 EC 编码时,目录是不能像文件那样直接 overwrite,只能自己实现替换逻辑,因为此操作不是原子的,可能会出现一些异常情况,需要额外处理;
(3)按文件粒度进行 EC 编码,会导致一个目录内既有 EC 文件又有非 EC 文件,管理起来比较混乱,尤其是对 Hive 的分区表;
(4)按目录粒度进行 EC 编码可以直接使用 distcp 工具来拷贝文件,而按照文件粒度 EC 不再适合使用 distcp,因为每个文件一个 distcp 任务对 Yarn 的压力太大,因此需要另外开发文件重写工具。
最后我们选择了按照目录粒度来做 EC,因为我们想直接用 distcp 工具拷贝文件,并且不想引入额外的复杂度。
3. EC 数据转换工具
 其中 EC Worker 是我们基于 distcp 开发的 EC 数据转换工具,EC Worker 具有以下功能:
(1)自动转 EC:订阅 EC 策略产出的目录列表,自动提交 distcp 任务到 Yarn 拷贝数据为 EC 编码格式,拷贝完成后替换原目录;
(2)用户伪装:能够以目录的 owner 提交对应的 distcp 任务;
(3)并发控制:能够精确控制同时运行的 distcp 任务数量,以及每一个 distcp 任务运行的 map 数;
(4)自动容错:在 distcp 失败或者替换目录失败时,保证原始目录不丢失;
(5)监控报警:在自动容错失败时,直接报警,让人工介入恢复原始目录;
(6)文件校验:能够校验文件在 EC 前和 EC 后是否一样,以及 EC 文件是否有 block 损坏;
(7)文件修复:EC Worker 能够校验损坏的 EC 文件,并且自动生成修复命令。
因为转 EC 最大的开销在数据拷贝阶段,而这一阶段又在 Yarn 上执行,所以 EC Worker 可以开发成一个非常轻量的客户端程序,我们以 4Core 16G 的配置运行 EC Worker,足以支撑上千的 distcp 任务同时运行。
利用 distcp 转存 EC 文件需要注意以下几点:
(1)因为文件转存 EC 编码后,block 将会发生变化,所以在进行拷贝的时候需要将 CRC 校验关闭,否则将会导致 distcp 任务失败;
(2)需要额外开发校验逻辑,保证数据在 EC 前和 EC 后内容是一样的;
(3)进行目录替换时,如果是有 federation 的 HDFS 集群,需要注意使临时目录与原目录在同一个 nameservice 下。这里提供一个思路,进行 federation 拆分的目录一般是大目录,进行 EC 的目录一般都是这些目录的子目录,所以我们可以设置临时目录在原目录的父目录下,临时目录以
其中 EC Worker 是我们基于 distcp 开发的 EC 数据转换工具,EC Worker 具有以下功能:
(1)自动转 EC:订阅 EC 策略产出的目录列表,自动提交 distcp 任务到 Yarn 拷贝数据为 EC 编码格式,拷贝完成后替换原目录;
(2)用户伪装:能够以目录的 owner 提交对应的 distcp 任务;
(3)并发控制:能够精确控制同时运行的 distcp 任务数量,以及每一个 distcp 任务运行的 map 数;
(4)自动容错:在 distcp 失败或者替换目录失败时,保证原始目录不丢失;
(5)监控报警:在自动容错失败时,直接报警,让人工介入恢复原始目录;
(6)文件校验:能够校验文件在 EC 前和 EC 后是否一样,以及 EC 文件是否有 block 损坏;
(7)文件修复:EC Worker 能够校验损坏的 EC 文件,并且自动生成修复命令。
因为转 EC 最大的开销在数据拷贝阶段,而这一阶段又在 Yarn 上执行,所以 EC Worker 可以开发成一个非常轻量的客户端程序,我们以 4Core 16G 的配置运行 EC Worker,足以支撑上千的 distcp 任务同时运行。
利用 distcp 转存 EC 文件需要注意以下几点:
(1)因为文件转存 EC 编码后,block 将会发生变化,所以在进行拷贝的时候需要将 CRC 校验关闭,否则将会导致 distcp 任务失败;
(2)需要额外开发校验逻辑,保证数据在 EC 前和 EC 后内容是一样的;
(3)进行目录替换时,如果是有 federation 的 HDFS 集群,需要注意使临时目录与原目录在同一个 nameservice 下。这里提供一个思路,进行 federation 拆分的目录一般是大目录,进行 EC 的目录一般都是这些目录的子目录,所以我们可以设置临时目录在原目录的父目录下,临时目录以 .ec_tmp_ 为前缀,比如 /a/b/c 的临时目录为 /a/b/.ec_tmp_c。
4. EC 损坏文件修复
我们对文件做 EC 编码的目的是为了节省成本,从 HDFS 角度而言,节省成本只有退役 DataNode 才能实现,因此我们在对大量存量数据 EC 后,需要根据节省的存储大小,退役相应数量的 DataNode。
知乎的 Hadoop 版本是 3.2.1,这个版本关于 EC 还有一些退役,重建相关的 BUG,具体可查看附录。我们在退役的过程中,触发了这些 BUG,导致有一些 EC 文件损坏,损坏的比例约为 0.005%,重建一亿个 block 就有 5000 个 block 损坏。当时正值年底,业务方需要大量读取数据做全年报表,而损坏的 EC 文件又导致有些 Hive 表不可读,修复迫在眉睫。
4.1 检查 EC 文件是否损坏
在 HDFS 中,EC 文件是以 stripe 的形式进行存储,以 RS-6-3 为例:
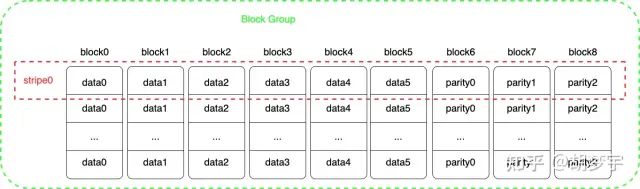 一个文件被分为多个 block group,而每一个 block group 分为 9 个 block,其中 6 个为数据块,3 个为校验块,而每一个 block 又被等分为等长的多段数据从而组成 stripe。
(1)遍历其所有的 block group,利用 BlockReader 读取每一个 block group 的 stripe 数据;
(2)对于每一 stripe,利用 Hadoop 提供的 EC 编码器,将 data0-data5 的数据进行编码,得到校验块与 parity0-parity2 对比;
(3)如果新编码出的校验块与 parity0-parity2 不同,则 EC 文件损坏;如果相同,则检查下一个 stripe;
(4)如果所有的 stripe 都能通过检查,则 EC 文件没有损坏,只要出现一个 stripe 没有通过检查,就认为 EC 文件损坏了。
我们将上述逻辑整理成了 MapReduce 任务,内置到 EC Worker 里进行自动化检查。
这里社区有一些实现,具体参考:HDFS-16286(https://issues.apache.org/jira/browse/HDFS-16286)。
一个文件被分为多个 block group,而每一个 block group 分为 9 个 block,其中 6 个为数据块,3 个为校验块,而每一个 block 又被等分为等长的多段数据从而组成 stripe。
(1)遍历其所有的 block group,利用 BlockReader 读取每一个 block group 的 stripe 数据;
(2)对于每一 stripe,利用 Hadoop 提供的 EC 编码器,将 data0-data5 的数据进行编码,得到校验块与 parity0-parity2 对比;
(3)如果新编码出的校验块与 parity0-parity2 不同,则 EC 文件损坏;如果相同,则检查下一个 stripe;
(4)如果所有的 stripe 都能通过检查,则 EC 文件没有损坏,只要出现一个 stripe 没有通过检查,就认为 EC 文件损坏了。
我们将上述逻辑整理成了 MapReduce 任务,内置到 EC Worker 里进行自动化检查。
这里社区有一些实现,具体参考:HDFS-16286(https://issues.apache.org/jira/browse/HDFS-16286)。
4.2 查找损坏的 blockId
上述逻辑只能找到损坏 stripe,而无法找到具体是哪个 block 损坏了,这里我们提供一种思路来查找损坏的 blockId,对于某一损坏的 stripe:
(1)选择 3 块数据擦除,用 EC 解码器利用剩下的 6 块数据恢复擦除的 3 块数据;
(2)逐一比较擦除的 3 块数据与新生成的 3 块数据;
(3)如果只有一块数据相同,则剩下的另外两块数据损坏;如果只有两块数据相同,则剩下的另一块数据损坏;如果没有数据块相同,则重新选择另外不同的 3 块数据进行擦除,重复步骤 1;
(4)如果对于任意的 3 块数据,擦除,编码生成后,都没有找到相同的数据块,则表明该文件损坏了 3 个或以上的数据块,需要借助其它方式进行判断。
EC 解码器可参考类 org.apache.hadoop.io.erasurecode.rawcoder.RSRawDecoder,需要注意,解码器是非线程安全的。
在选择 data0,data1,data2 擦除时,新生成的数据我们记为 data0_new,data1_new,data2_new,此时比较旧数据与新数据,会得到以下结果:
data0 != data0_newdata1 = data1_newdata2 = data2_new
假设 data0 与 data1 损坏,则会得到以下结果:
data0 != data0_newdata1 != data1_newdata2 = data2_new
上述方法只适用于损坏 1-2 个 block,如果损坏了 3 个以上 block,则 EC 文件无法恢复,如果正好损坏 3 个 block,而文件格式又恰好是一些比较特殊的格式,如 ORC,Parquet 等,则可采用以下方法:
(1)选择 3 个 DataNode 排除,利用剩下的 6 个 DataNode 读出整个文件;
(2)利用 parquet-tools 或者 orc-tools 解析读出来的文件;
(3)如果能解析出来,说明排除的 3 个 DataNode 上的数据正好是损坏的,删除这 3 个 DataNode 上的 block,使其重建即可修复;如果不能解析,则换另外 3 个 DataNode 重复步骤 1;
(4)如果任意排除 3 个 DataNode 读出的文件都不能解析,则说明该 EC 文件损坏了 3 个以上的 block,无法恢复。
排除指定的 DataNode 读取文件,需要用到 HDFS 客户端类 DFSClient 的一些高级 API,这里不做赘述;另外还有一个更简单的办法,就是读取时,在客户端所在的机器上利用 iptables 手动排除这些 DataNode 的入流量,即可排除这些 DataNode。
4.3 快速定位 block 所在磁盘地址
修复损坏的 block 十分简单,就是到对应的 DataNode 机器上将其删除,使其重建即可。但是这里有一个难点,就是如何迅速找到需要删除的 block 所在磁盘路径。常见的办法是通过 find 命令查找,block 在磁盘里存储时,文件名正好是 blockId,所以这里用 find 命令查找 block 是可行的,但是一个 DataNode 上的 block 有数十万甚至上百万,find 命令查找一次需要的时间太长,在磁盘负载较高的情况下,甚至能达到几分钟,这种方式在大规模修复的时候显然是不可取的。所以此时需要用到另外一种方法。
DataNode 提供了一个接口,具体可查看 org.apache.hadoop.hdfs.protocol.ClientDatanodeProtocol#getBlockLocalPathInfo,这个接口返回的对象里存储了 block 所在的磁盘路径。但是需要注意此接口只有特定用户才能访问,可访问的用户需要配置在 DataNode 的 hdfs-site.xml 中,比如:
dfs.block.local-path-access.user hdfs
我们将上述查找流程内置到 EC Worker 里,EC Worker 会自动生成修复命令,删除损坏的 block。
5. 总结
知乎通过 HDFS EC 技术,将总存储 25% 的文件转成了 EC 编码格式存储,节省了约 12% 的存储空间。
总体来说,HDFS EC 文件在不涉及到 EC 块重建的情况下,还是比较好用的。一旦涉及到大量块重建,比如节点宕机,机器退役的情况,低版本的 Hadoop 很容易踩到各种各样的坑,需要去社区寻找 EC 相关的 patch 进行修复。所以我们建议有条件的用户还是直接升级 Hadoop 到一个较高的版本(如 Hadoop3.3.4),或者是将 EC 相关的 patch 尽量打入当前使用版本,这样可以避免很多 EC 相关的问题。
6. 附录
以下为我们基于 Hadoop 3.2.1 版本合入的社区 patch,仅供参考。
💬:怎样的指标体系具有业务价值?
🙍:赵松 某知名高端电动车品牌 大数据产品负责人
⏰:102/22 19:00-20:00
🔗:扫码进群收看直播

本文转载自胡梦宇等人 DataFunSummit,原文链接:https://mp.weixin.qq.com/s/GnMHv-ggEcrGLGpc1NcmdA。






