
Apache Hudi 是一种流行的开源 Lakehouse 技术,在大数据社区中迅速发展。如果您在 AWS 上构建了数据湖和数据工程平台,您可能已经听说过或使用过 Apache Hudi,因为 AWS 在其众多数据服务(包括 EMR、Redshift、Athena、Glue 等)中原生集成并支持了 Apache Hudi


在考虑在 Microsoft Azure[1] 上构建数据湖或 Lakehouse 时,大多数人已经熟悉 Databricks 的 Delta Lake,但现在有些人发现 Apache Hudi 是一种可行的替代方案,可与 Azure Synapse Analytics[2]、HDInsight[3]、ADLS Gen2[4] 、EventHubs[5] 等 Azure 原生服务一起使用,甚至包括 Azure Databricks。由于可用的文档有限,本博客的目标是分享有关如何在 Azure 上轻松启动和使用 Hudi 的步骤。Apache Hudi 是一种开源 Lakehouse 技术,使你能够将事务、并发、更新插入和高级存储性能优化引入 Azure Data Lake Storage (ADLS) 上的数据湖。Apache Hudi 为您的工作负载提供了显着的性能优势[6],并确保您的数据不会被锁定或绑定到任何一家供应商。使用 Apache Hudi,您的所有数据[7]都保留在 parquet 等开放文件格式中,Hudi 可以与任何流行的查询引擎(如 Apache Spark、Flink、Presto、Trino、Hive 等)一起使用。
Hudi 和 Synapse 设置
在 Azure 上使用 Apache Hudi 就像将一些库加载到 Azure Synapse Analytics 中一样简单。如果您已经拥有 Synapse 工作区、Spark Pool 和 ADLS 存储帐户,则可以跳过以下一些先决条件步骤。
准备条件 – Synapse工作区
首先如果还没有工作区,请创建一个 Synapse 工作区[8]。无需特殊配置,您需要记住 ADLS 帐户名称和文件系统名称以供以后使用。
准备条件 – Serverless Spark Pool
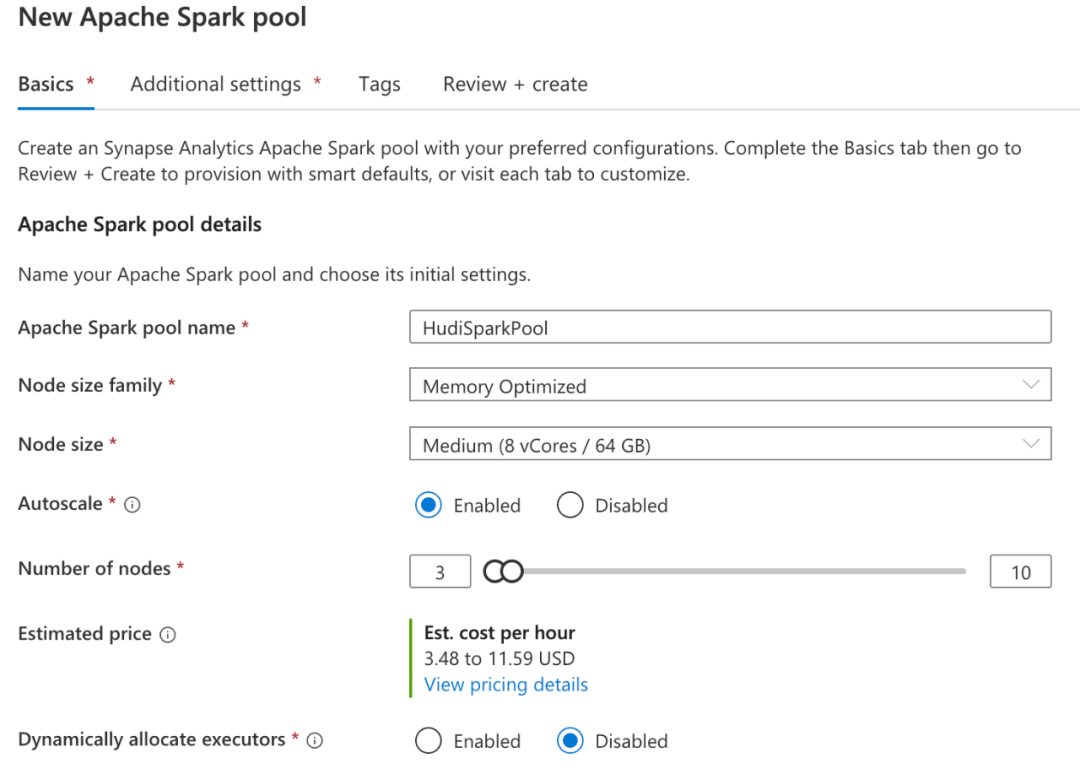
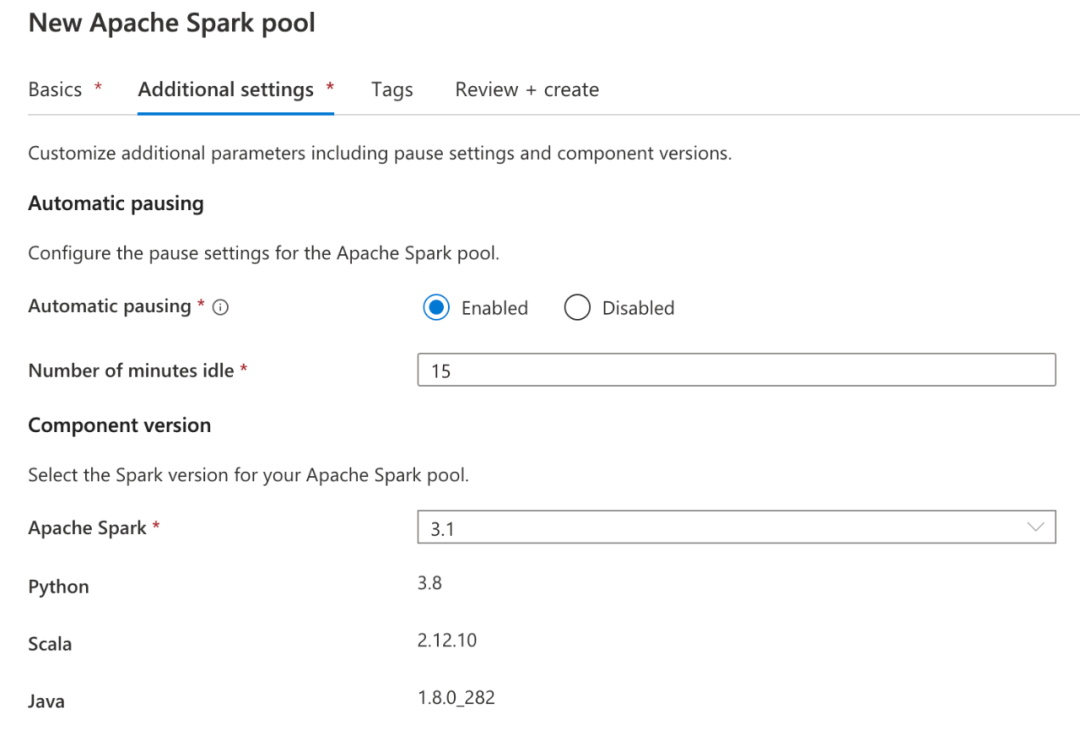
将 Hudi 与 Apache Spark 一起使用非常容易,因此让我们创建一个 Synapse Serverless Spark池,我们可以使用它来读取和写入数据。首先打开刚刚创建的 Synapse Workspace 并在 Synapse Studio 中启动它。按照此快速入门创建 Spark 池[9]。您无需为 Hudi 设置特定设置,但请注意您选择的 Spark 运行时版本,并确保您选择了合适的 Hudi 版本[10]来匹配。在本教程中,我选择了使用 Scala 2.12.10 和 Java 1.8 的 Synapse 中的 Spark 3.1。
准备条件 – 将 Hudi 包添加到 Synapse
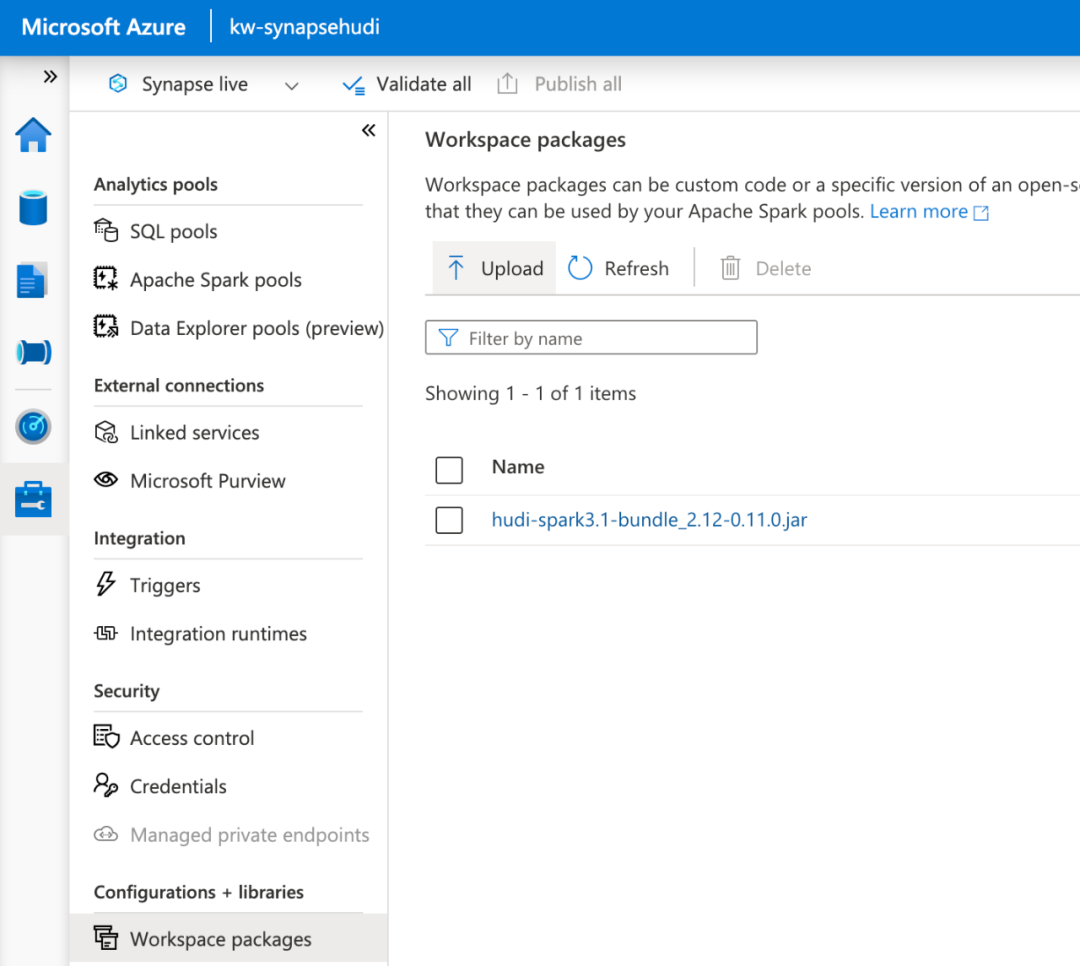
虽然 Apache Hudi 库默认预装在 AWS 和 GCP 上的大多数其他数据服务上,但您需要执行一个额外步骤才能在 Azure 上运行 Hudi。有关如何将包安装到 Synapse 工作区的信息,请参阅文档[11]。使用 Spark 3.1可以配套使用 Hudi 0.10+,可以从 Maven 中心下载了最新的 Hudi 0.11.1 jar:https://search.maven.org/search?q=a:hudi-spark3.1-bundle_2.12 从此处的工作区将 .jar 包上传到 Synapse 工作区:
现在包已上传到工作区,您需要将此包添加到工作区池。导航到Spark池并查找包选项:

单击“从工作区包中选择”

并选择您上传到工作区的 Hudi .jar:

准备条件 – 创建 Synapse Notebook
在 Synapse Studio 中创建一个Notebook[12]。本教程使用的是 Scala,也可以使用 Python。
Hudi 和 Synapse 快速入门
这个简单的快速入门会让您大吃一惊。有关更深入的材料请参阅下面的其他资源。如果您不想在教程的其余部分复制/粘贴代码,您可以从我的 Github 下载此笔记本[13],然后将其导入Synapse 工作区[14]。
导入样本数据
对于这个简单的快速入门,我使用了来自 AML 开放数据集的经典 NYC Taxi 数据集。
from azureml.opendatasets import NycTlcYellow
from dateutil import parser
from datetime import datetime
end_date = parser.parse('2018-06-06')
start_date = parser.parse('2018-05-01')
nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date)
filtered_df = nyc_tlc.to_spark_dataframe()
display(filtered_df)设置 Hudi 写入配置
选择一个 Hudi 基本路径并设置基本的写入配置。
- • 在 Hudi 文档中阅读有关 Hudi 记录键、预组合键和其他配置的信息:https://hudi.apache.org/docs/writing_data
-
• 在此处阅读有关 Hudi 写入操作的信息:https://hudi.apache.org/docs/write_operations
basePath = "abfs://kwadlsfilesyshudi@kwadlshudi.dfs.core.windows.net/hudi-test/"
tableName = "hudi_test_data"
hudi_options = {
'hoodie.table.name': tableName,
'hoodie.datasource.write.recordkey.field': 'tpepPickupDateTime',
'hoodie.datasource.write.operation': 'upsert',
'hoodie.datasource.write.precombine.field': 'tpepDropoffDateTime'
}将样本数据集作为 Hudi 表写入 ADLS G2
只需要使用hudi format即可:spark.write.format("hudi")
filtered_df.write.format("hudi").options(**hudi_options).mode("overwrite").save(basePath)创建 SQL 表
可以使用 Hudi 关键字创建托管或外部共享表 https://docs.microsoft.com/en-us/azure/synapse-analytics/metadata/table#shared-spark-tables
spark.sql("CREATE TABLE HudiTable USING HUDI LOCATION '{0}'".format(basePath))现在可以充分利用 Hudi 表上的基本 SQL:
%%sql
select * from HudiTable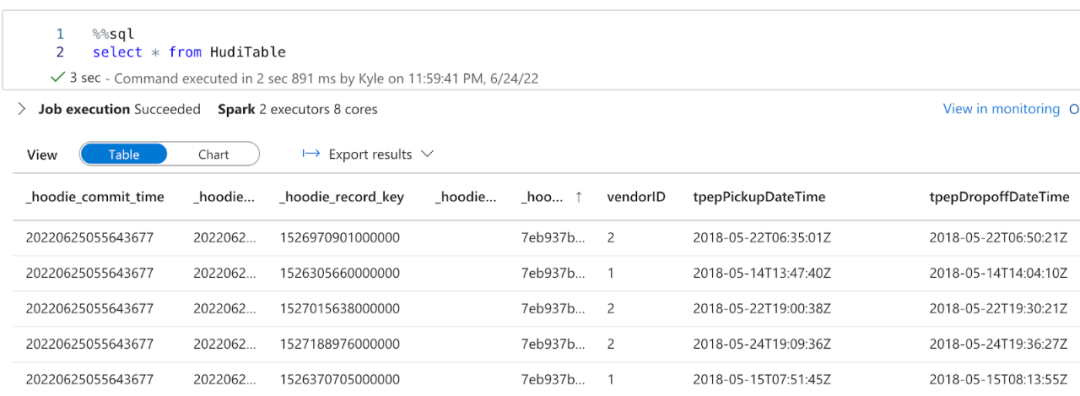
Upserts/Merges
Apache Hudi 在数据湖上提供了首个此类高性能索引子系统[15]。借助记录级索引和 ACID 事务,Hudi 可以轻松快速高效地进行更新插入和合并。假设在出租车行程结束后,乘客决定在行程结束几小时或几天后更改他的小费。对于这个例子,我们先抓取一条记录并检查原始的 tipAmount
origvalue = spark.
read.
format("hudi").
load(basePath).
where("_hoodie_record_key = '1526970901000000'")
display(origvalue.select("tipAmount"))
现在将 Hudi 写入操作设置为 upsert,将 tipAmount更改为 $5.23,并将更新后的值写入 append
from pyspark.sql.functions import lit
hudi_options = {
'hoodie.table.name': tableName,
'hoodie.datasource.write.recordkey.field': 'tpepPickupDateTime',
'hoodie.datasource.write.operation': 'upsert',
'hoodie.datasource.write.precombine.field': 'tpepDropoffDateTime'
}
updatevalue = origvalue.withColumn("tipAmount",lit(5.23))
updatevalue.write.format("hudi").
options(**hudi_options).
mode("append").
save(basePath)原始值变更了
testupdate = spark.
read.
format("hudi").
load(basePath).
where("_hoodie_record_key = '1526970901000000'")
display(testupdate.select("tipAmount"))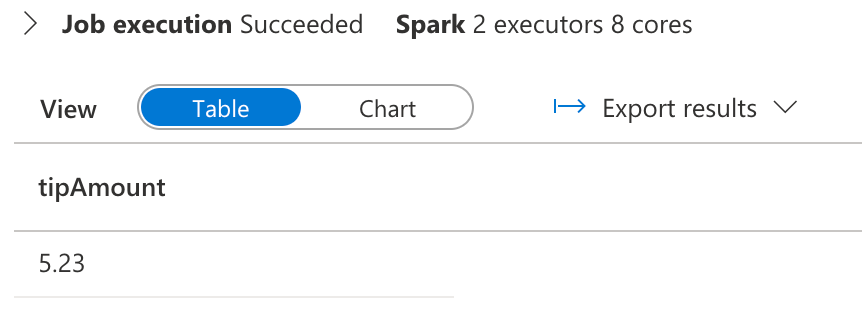
时间旅行
使用 Apache Hudi可以编写时间旅行查询来重现数据集在某个时间点的样子。可以使用提交瞬间或时间戳指定时间点:https://hudi.apache.org/docs/quick-start-guide#time-travel-query 有几种方法可以找到提交瞬间(查询表详细信息、使用 Hudi CLI 或检查存储)。为简单起见我在 Synapse Studio 中打开了 ADLS 浏览器并导航到保存我的数据的文件夹。该文件夹中有一个 .hoodie 文件夹,其中包含以 [commit instance id].commit 表示的提交列表。下面例子选择了最早的一个。
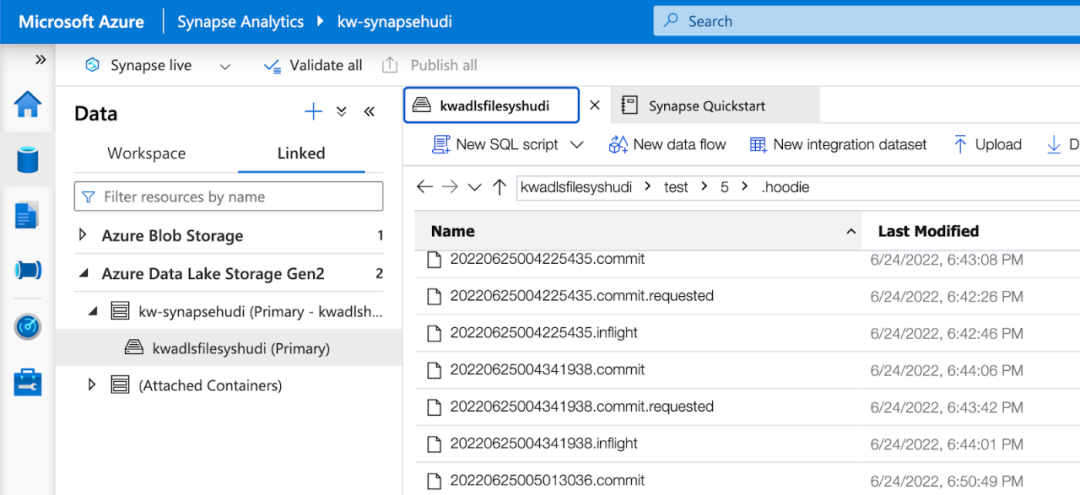
查询如下
testupdate = spark.
read.
format("hudi").
option("as.of.instant", "20220624055125356").
load(basePath).
where("_hoodie_record_key = '1526970901000000'")
display(testupdate.select("tipAmount"))
# you can travel back in time before the upsert and reproduce the original tipAmount增量查询
Apache Hudi 能够用高效的增量管道替换老式的批处理数据管道。用户可以指定“增量”查询类型,并向 Hudi 询问在给定提交或时间戳之后的所有新记录或更新记录。(对于这个例子,它只是我们更新的那一行,但请随意尝试更多)
# incrementally query data
incremental_read_options = {
'hoodie.datasource.query.type': 'incremental',
'hoodie.datasource.read.begin.instanttime': 20220624055125356,
}
tripsIncrementalDF = spark.read.format("hudi").
options(**incremental_read_options).
load(basePath)
display(tripsIncrementalDF)删除
对于大多数数据湖而言,一项具有挑战性的任务是处理删除,尤其是在处理 GDPR 合规性法规时。Apache Hudi 处理快速高效的删除,同时提供高级并发控制配置。查询要删除的记录
todelete = spark.
read.
format("hudi").
load(basePath).
where("_hoodie_record_key = '1527015638000000'")
display(todelete)接下来将 Hudi 写入操作设置为 delete 并将这些记录作为追加写入:
hudi_delete_options = {
'hoodie.table.name': tableName,
'hoodie.datasource.write.recordkey.field': 'tpepPickupDateTime',
'hoodie.datasource.write.operation': 'delete',
'hoodie.datasource.write.precombine.field': 'tpepDropoffDateTime'
}
todelete.write.format("hudi").options(**hudi_delete_options).mode("append").save(basePath)可以确认记录已被删除:
todelete = spark.
read.
format("hudi").
load(basePath).
where("_hoodie_record_key = '1527015638000000'")
display(todelete)结论
希望这提供了有关如何开始在 Azure 上使用 Apache Hudi 的指南。虽然本文专注于 Azure Synapse Analytics,但这并不是 Azure 产品组合中唯一可以使用 Apache Hudi 的产品。以下是在使用 Apache Hudi 在 Azure 上开发数据平台时可以考虑的一些架构的想法

本文转载自Apache Hudi,原文链接:https://mp.weixin.qq.com/s/l4DmUhJWUXJ0EvSmKFxXkQ。